
소개
scikit-learn 을 사용한 K-최근접 이웃 (KNN) 분류 실습에 오신 것을 환영합니다! scikit-learn 은 머신러닝을 위한 강력하고 인기 있는 Python 라이브러리입니다. KNN 알고리즘은 가장 간단하면서도 효과적인 분류 알고리즘 중 하나입니다. 이 알고리즘은 특징 공간에서 'k'개의 가장 가까운 이웃의 다수 클래스를 기반으로 새로운 데이터 포인트를 분류합니다. 본 실습에서는 유명한 Iris 데이터셋을 로드하고, 이를 훈련 세트와 테스트 세트로 분할하고, KNN 분류기를 초기화 및 훈련하고, 마지막으로 훈련된 모델을 사용하여 새롭고 보지 못한 데이터에 대한 예측을 수행하는 등 머신러닝 모델 구축의 전체 과정을 살펴보겠습니다. 본 실습이 끝나면 scikit-learn 에서의 지도 학습 (supervised learning) 에 대한 기본적인 워크플로우를 확실하게 이해하게 될 것입니다.
datasets.load_iris() 로 Iris 데이터셋 로드하기
이 단계에서는 필요한 데이터셋을 로드하는 것부터 시작합니다. scikit-learn 에 편리하게 포함된 고전적인 Iris 데이터셋을 사용할 것입니다. 먼저 sklearn에서 datasets 모듈을 가져와야 합니다. 그런 다음 load_iris() 함수를 호출하여 데이터를 가져옵니다.
load_iris() 이해하기:
- 반환 타입: 다음을 포함하는
Bunch객체 (사전과 유사) 를 반환합니다..data: 특징 행렬 (150 개 샘플 × 4 개 특징: 꽃받침 길이, 꽃받침 너비, 꽃잎 길이, 꽃잎 너비).target: 레이블 배열 (종: 0=setosa, 1=versicolor, 2=virginica).feature_names: 4 개 특징의 이름.target_names: 3 개 종의 이름
- 목적: 분류 연습을 위해 깨끗하고 바로 사용할 수 있는 데이터셋을 제공합니다.
이것들을 각각 변수 X와 y에 할당할 것입니다. 이는 머신러닝에서 일반적인 관례입니다 (X 는 특징, y 는 레이블).
왼쪽 편집기에서 main.py 파일을 열고 다음 코드를 추가하세요.
from sklearn import datasets
## Load the iris dataset
iris = datasets.load_iris()
## Assign features to X and labels to y
X = iris.data
y = iris.target
## You can print the shape to see the dimensions
print("Features shape:", X.shape)
print("Labels shape:", y.shape)
이제 터미널에서 스크립트를 실행하여 출력을 확인하세요.
python3 main.py
특징 행렬과 레이블 벡터의 차원을 볼 수 있습니다.
Features shape: (150, 4)
Labels shape: (150,)
이는 각 샘플에 대해 150 개의 샘플 (꽃) 과 4 개의 특징이 있음을 의미합니다.
sklearn.model_selection 의 train_test_split 을 사용하여 데이터를 훈련 및 테스트 세트로 분할
이 단계에서는 데이터셋을 훈련 세트와 테스트 세트의 두 부분으로 분할합니다. 이는 보지 못한 데이터에 대한 모델 성능을 평가하기 위한 머신러닝의 중요한 단계입니다.
train_test_split() 매개변수 이해하기:
test_size=0.3: 데이터의 30% 를 테스트용으로, 70% 를 훈련용으로 예약합니다.random_state=42: 재현 가능한 분할을 보장합니다 (실행할 때마다 동일한 난수 시드 사용).- 목적: 보지 못한 데이터로 모델을 평가하여 과적합 (overfitting) 을 방지합니다.
- 출력: 네 개의 배열을 반환합니다: X_train, X_test, y_train, y_test.
훈련 세트로 모델을 훈련시킨 다음, 테스트 세트로 예측 능력을 테스트합니다. scikit-learn 은 이 목적을 위해 train_test_split이라는 유용한 함수를 제공합니다. sklearn.model_selection에서 이 함수를 가져와야 합니다.
main.py 파일 끝에 다음 코드를 추가하세요.
from sklearn.model_selection import train_test_split
## Split data into training and testing sets
## test_size=0.3 means 30% of the data will be used for testing
## random_state ensures reproducibility
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
## Print the shapes of the new sets
print("X_train shape:", X_train.shape)
print("X_test shape:", X_test.shape)
이제 스크립트를 다시 실행하세요.
python3 main.py
출력에는 훈련 및 테스트 세트의 차원이 포함됩니다.
Features shape: (150, 4)
Labels shape: (150,)
X_train shape: (105, 4)
X_test shape: (45, 4)
sklearn.neighbors 의 KNeighborsClassifier 를 n_neighbors=3 으로 초기화
이 단계에서는 K-최근접 이웃 (K-Nearest Neighbors) 분류기를 초기화합니다. KNN 의 핵심 아이디어는 데이터 포인트의 클래스를 예측하기 위해 가장 가까운 'k'개의 이웃 클래스를 살펴보는 것입니다.
KNeighborsClassifier() 매개변수 이해하기:
n_neighbors=3: 예측을 위해 고려할 가장 가까운 이웃의 수- 작은 값 (예: 1-3): 노이즈에 더 민감하며 과적합될 수 있습니다.
- 큰 값 (예: 5-7): 더 부드러운 결정 경계 (decision boundaries) 를 가지며 더 견고합니다.
- 알고리즘 동작: 예측 시, k 개의 가장 가까운 훈련 포인트를 찾아 다수결 투표 (majority voting) 를 사용합니다.
- 훈련 단계 없음: KNN 은 "게으른 학습자 (lazy learner)"입니다. 훈련 데이터를 저장하고 예측 중에 계산합니다.
KNeighborsClassifier는 scikit-learn 에서 이 알고리즘을 구현하는 클래스입니다. sklearn.neighbors에서 이 클래스를 가져와야 합니다. 분류기 객체를 생성하고 clf라고 이름을 지정해 보겠습니다.
main.py 파일 끝에 다음 코드를 추가하세요.
from sklearn.neighbors import KNeighborsClassifier
## Initialize the KNN classifier with n_neighbors=3
clf = KNeighborsClassifier(n_neighbors=3)
이 코드는 출력을 생성하지 않지만, 다음 단계에서 훈련할 준비가 된 분류기 객체를 메모리에 생성합니다.
clf.fit(X_train, y_train) 으로 분류기 학습
이 단계에서는 훈련 데이터를 사용하여 분류기를 학습시키거나 'fit'합니다. KNN 알고리즘의 경우, '훈련' 단계는 매우 간단합니다. 전체 훈련 데이터셋 (X_train 및 y_train) 을 저장하는 것만 포함됩니다.
.fit() 메서드 이해하기:
- 입력 매개변수:
X_train(특성 행렬),y_train(타겟 레이블) - 기능: 예측 시 나중에 사용할 수 있도록 훈련 데이터를 메모리에 저장합니다.
- KNN 특수성: 다른 알고리즘과 달리 KNN 은 fit 중에 매개변수를 학습하지 않습니다.
- 목적: 새로운 데이터에 대한 예측을 위해 모델을 준비합니다.
새로운 포인트에 대한 예측이 필요할 때, 알고리즘은 이 저장된 데이터셋에서 'k'개의 가장 가까운 포인트를 찾아 결정을 내립니다. scikit-learn 에서 모델을 훈련시키려면 분류기 객체의 .fit() 메서드를 사용합니다. 이 메서드는 훈련 특성 (X_train) 과 해당 훈련 레이블 (y_train) 을 인수로 받습니다.
main.py 끝에 다음 코드 줄을 추가하세요.
## Train the classifier using the training data
clf.fit(X_train, y_train)
print("Classifier trained successfully.")
코드를 추가한 후 스크립트를 실행하세요.
python3 main.py
분류기가 성공적으로 훈련되었다는 확인 메시지가 표시됩니다.
Features shape: (150, 4)
Labels shape: (150,)
X_train shape: (105, 4)
X_test shape: (45, 4)
Classifier trained successfully.
clf.predict(X_test) 로 클래스 예측
이 마지막 단계에서는 훈련된 분류기를 사용하여 테스트 데이터에 대한 예측을 수행합니다. 이제 모델이 훈련 데이터로부터 '학습'했으므로, 이전에 본 적 없는 테스트 세트의 특성 (X_test) 을 모델에 제공하고 각 샘플에 대한 클래스를 예측하도록 요청할 수 있습니다.
.predict() 메서드 이해하기:
- 입력 매개변수:
X_test(보지 못한 데이터의 특성 행렬) - 알고리즘 프로세스: 각 테스트 샘플에 대해 훈련 데이터에서 k 개의 가장 가까운 이웃을 찾아 다수결 투표를 사용합니다.
- 출력: 예측된 클래스 레이블 배열 (입력 샘플과 동일한 길이)
- 거리 측정 기준: 기본적으로 유클리드 거리 (Euclidean distance) 를 사용하여 포인트 간의 유사성을 측정합니다.
- 목적: 새롭고 보지 못한 데이터에 대한 모델 성능을 평가합니다.
이는 .predict() 메서드를 사용하여 수행됩니다. 이 메서드는 테스트 특성 (X_test) 을 입력으로 받아 예측된 레이블의 배열을 반환합니다. 이러한 예측을 predictions라는 변수에 저장하고 콘솔에 출력할 것입니다. 실제 레이블 (y_test) 을 출력하여 모델이 얼마나 잘 수행되었는지 확인할 수도 있습니다.
마지막 코드 조각을 main.py 파일에 추가하세요.
## Make predictions on the test data
predictions = clf.predict(X_test)
print("Predictions on test data:", predictions)
print("Actual labels of test data:", y_test)
이제 전체 스크립트를 실행하세요.
python3 main.py
테스트 세트에 대한 예측된 클래스 레이블 배열과 실제 레이블 배열이 차례로 표시됩니다.
... (previous output) ...
Classifier trained successfully.
Predictions on test data: [1 0 2 1 1 0 1 2 1 1 2 0 0 0 0 1 2 1 1 2 0 2 0 2 2 2 2 2 0 0 0 0 1 0 0 2 1
0 0 0 2 1 1 0 0]
Actual labels of test data: [1 0 2 1 1 0 1 2 1 1 2 0 0 0 0 1 2 1 1 2 0 2 0 2 2 2 2 2 0 0 0 0 1 0 0 2 1
0 0 0 2 1 1 0 0]
참고: 출력 배열은 여기에 전체 표시됩니다. 두 배열을 비교하면 예측이 실제 레이블과 완벽하게 일치하는 것을 볼 수 있으며, 이는 이 테스트 세트에서 모델 성능이 매우 우수함을 나타냅니다.
KNN 분류 결과 시각화
이 보너스 단계에서는 KNN 분류 결과를 더 잘 이해하기 위한 시각화를 생성합니다. 시각화는 모델이 얼마나 잘 수행되었는지 확인하고 KNN 알고리즘이 생성한 결정 경계 (decision boundaries) 를 이해하는 데 도움이 됩니다.
분류에서의 데이터 시각화 이해하기:
- 산점도 (Scatter plots): 특성 간의 관계와 클래스가 어떻게 분포하는지 보여줍니다.
- 색상 코딩 (Color coding): 다른 색상은 다른 클래스 (종) 를 나타냅니다.
- 훈련 vs 테스트 데이터: 모델의 일반화 (generalization) 를 이해하는 데 도움이 됩니다.
- 예측 정확도 (Prediction accuracy): 예측된 레이블과 실제 레이블을 시각적으로 비교합니다.
시각화를 생성하기 위해 main.py 파일 끝에 다음 코드를 추가하세요.
import matplotlib.pyplot as plt
import numpy as np
## Create subplots for multiple visualizations
fig, axes = plt.subplots(1, 2, figsize=(15, 6))
## Plot 1: Training data with different colors for each class
scatter1 = axes[0].scatter(X_train[:, 0], X_train[:, 1], c=y_train, cmap='viridis', alpha=0.7, s=50)
axes[0].set_xlabel('Sepal Length (cm)')
axes[0].set_ylabel('Sepal Width (cm)')
axes[0].set_title('Training Data Distribution')
axes[0].legend(*scatter1.legend_elements(), title="Classes")
## Plot 2: Test data predictions vs actual labels
## Create a comparison: correct predictions vs incorrect ones
test_predictions = clf.predict(X_test)
correct_predictions = (test_predictions == y_test)
## Plot correct predictions
correct_mask = correct_predictions
scatter2_correct = axes[1].scatter(X_test[correct_mask, 0], X_test[correct_mask, 1],
c=y_test[correct_mask], cmap='viridis', alpha=0.7, s=50, marker='o')
## Plot incorrect predictions with different marker
incorrect_mask = ~correct_predictions
if np.any(incorrect_mask):
scatter2_incorrect = axes[1].scatter(X_test[incorrect_mask, 0], X_test[incorrect_mask, 1],
c=test_predictions[incorrect_mask], cmap='viridis',
alpha=0.7, s=80, marker='x', edgecolors='red', linewidths=2)
axes[1].set_xlabel('Sepal Length (cm)')
axes[1].set_ylabel('Sepal Width (cm)')
axes[1].set_title('Test Data: Predictions vs Actual\n(correct=●, incorrect=✕)')
## Create legend
legend_elements = [plt.Line2D([0], [0], marker='o', color='w', markerfacecolor='gray', markersize=8, label='Correct'),
plt.Line2D([0], [0], marker='x', color='red', markersize=8, label='Incorrect')]
axes[1].legend(handles=legend_elements)
plt.tight_layout()
plt.savefig('knn_classification_results.png', dpi=150, bbox_inches='tight')
print("Visualization saved to knn_classification_results.png")
## Additional: Show prediction accuracy
accuracy = np.mean(correct_predictions) * 100
print(f"Model Accuracy: {accuracy:.1f}%")
업데이트된 스크립트를 실행하세요.
python3 main.py
다음과 같은 출력을 포함하여 보게 될 것입니다.
... (previous output) ...
Visualization saved to knn_classification_results.png
Model Accuracy: 100.0%
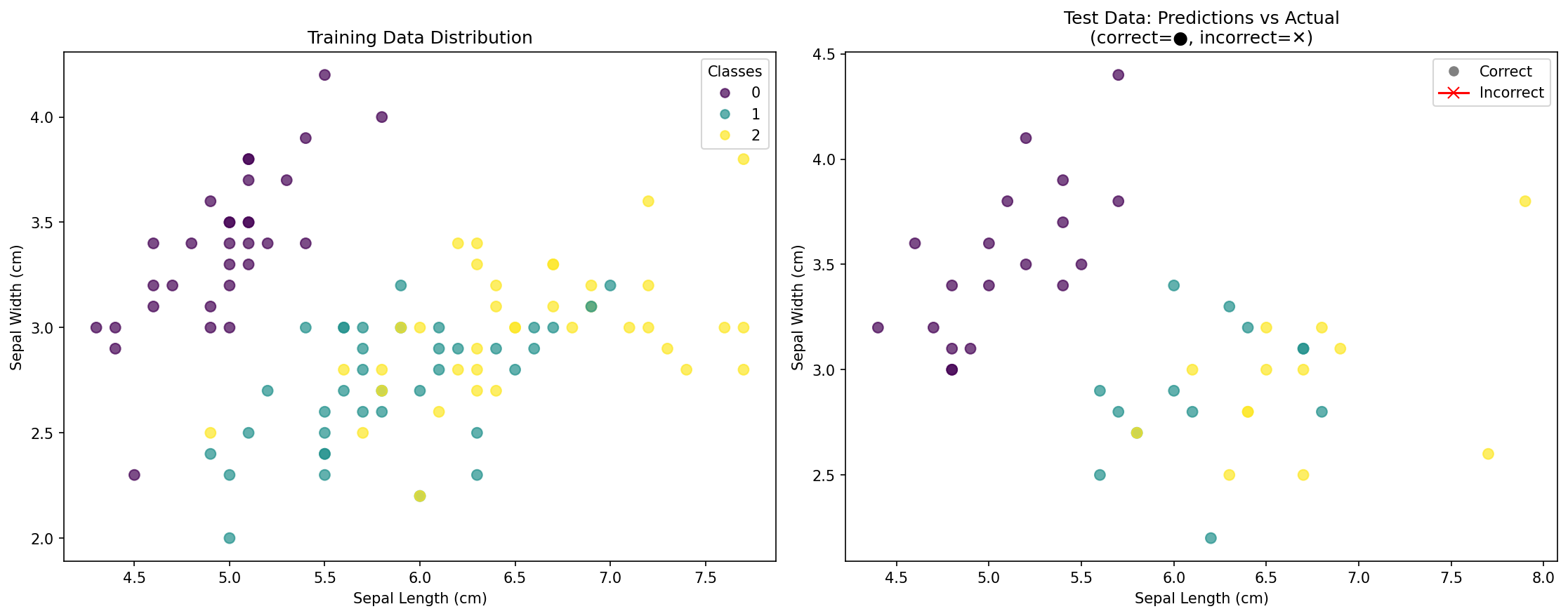
시각화 내용:
- 왼쪽 플롯: 실제 종별로 색상이 지정된 훈련 데이터 포인트의 분포
- 오른쪽 플롯: 테스트 데이터 포인트 표시:
- 원 (●): 올바르게 분류된 포인트
- 십자 (✕): 잘못 분류된 포인트 (있는 경우)
- 정확도 점수: 올바른 예측의 전체 백분율
이 시각화는 다음을 이해하는 데 도움이 됩니다.
- 특성 공간에서 클래스가 어떻게 분포하는지
- 모델이 과적합 (overfitting) 되었는지 또는 일반화를 잘 하고 있는지
- 분류에 어려움을 겪을 수 있는 영역
- KNN 모델의 효과를 시각적으로 확인
요약
이 랩을 완료하신 것을 축하드립니다! scikit-learn 을 사용하여 K-Nearest Neighbors 분류 모델을 성공적으로 구축하고 훈련했습니다. 지도 학습 (supervised machine learning) 프로젝트의 기본 워크플로우를 배웠으며, 여기에는 다음이 포함됩니다.
sklearn.datasets를 사용하여 데이터셋 로드하기.train_test_split으로 데이터를 훈련 세트와 테스트 세트로 분할하기.- 분류기 초기화하기, 이 경우
KNeighborsClassifier. .fit()메서드를 사용하여 훈련 데이터로 모델 훈련하기..predict()메서드를 사용하여 새롭고 보지 못한 데이터에 대한 예측하기.- 모델 성능 및 결정 패턴을 이해하기 위해 결과 시각화하기.
이 과정은 많은 머신러닝 작업의 기초를 형성합니다. 여기에서 정확도 (accuracy), 정밀도 (precision), 재현율 (recall) 과 같은 지표를 사용하여 모델 성능을 보다 공식적으로 평가하는 방법을 탐색하거나, n_neighbors의 다른 값을 실험하여 결과에 미치는 영향을 확인할 수 있습니다. 또한 결정 경계 (decision boundaries) 를 시각화하거나 KNN 분류기에서 다른 거리 측정 기준 (distance metrics) 을 사용해 볼 수도 있습니다.


