
소개
scikit-learn 첫 번째 실습에 오신 것을 환영합니다! scikit-learn 은 Python 을 위한 가장 인기 있고 강력한 오픈 소스 머신러닝 라이브러리 중 하나입니다. NumPy, SciPy, matplotlib 을 기반으로 구축되어 데이터 마이닝 및 데이터 분석을 위한 광범위한 도구를 제공합니다.
이 과정을 시작하기 전에 기본적인 Python 프로그래밍 기술을 갖추고 시스템 PATH 에 Python 이 올바르게 설정되어 있는지 확인해야 합니다. 아직 Python 을 배우지 않았다면, 저희의 Python 학습 경로에서 시작할 수 있습니다. 또한, scikit-learn 작업을 위한 필수 선행 조건인 NumPy 와 Pandas 가 설치되어 있어야 합니다. 이러한 라이브러리를 배워야 한다면, 저희의 NumPy 학습 경로와 Pandas 학습 경로를 탐색해 보세요.
이 실습에서는 LabEx 환경에서 scikit-learn 을 시작하는 기본적인 단계를 배우게 됩니다. 설치 확인, 모듈 가져오기, scikit-learn 의 내장 데이터셋 중 하나를 로드하는 과정을 살펴보겠습니다. 이를 통해 향후 머신러닝 실험을 위해 환경이 올바르게 구성되었는지 확인할 수 있습니다.
pip install scikit-learn 을 사용하여 scikit-learn 설치
이 단계에서는 scikit-learn 라이브러리를 설치하는 방법에 대해 설명합니다. 로컬 머신에서 일반적인 Python 환경에서는 pip (Python 의 패키지 설치 프로그램) 를 사용하여 새 라이브러리를 설치합니다. scikit-learn 을 설치하는 명령은 다음과 같습니다.
pip install scikit-learn
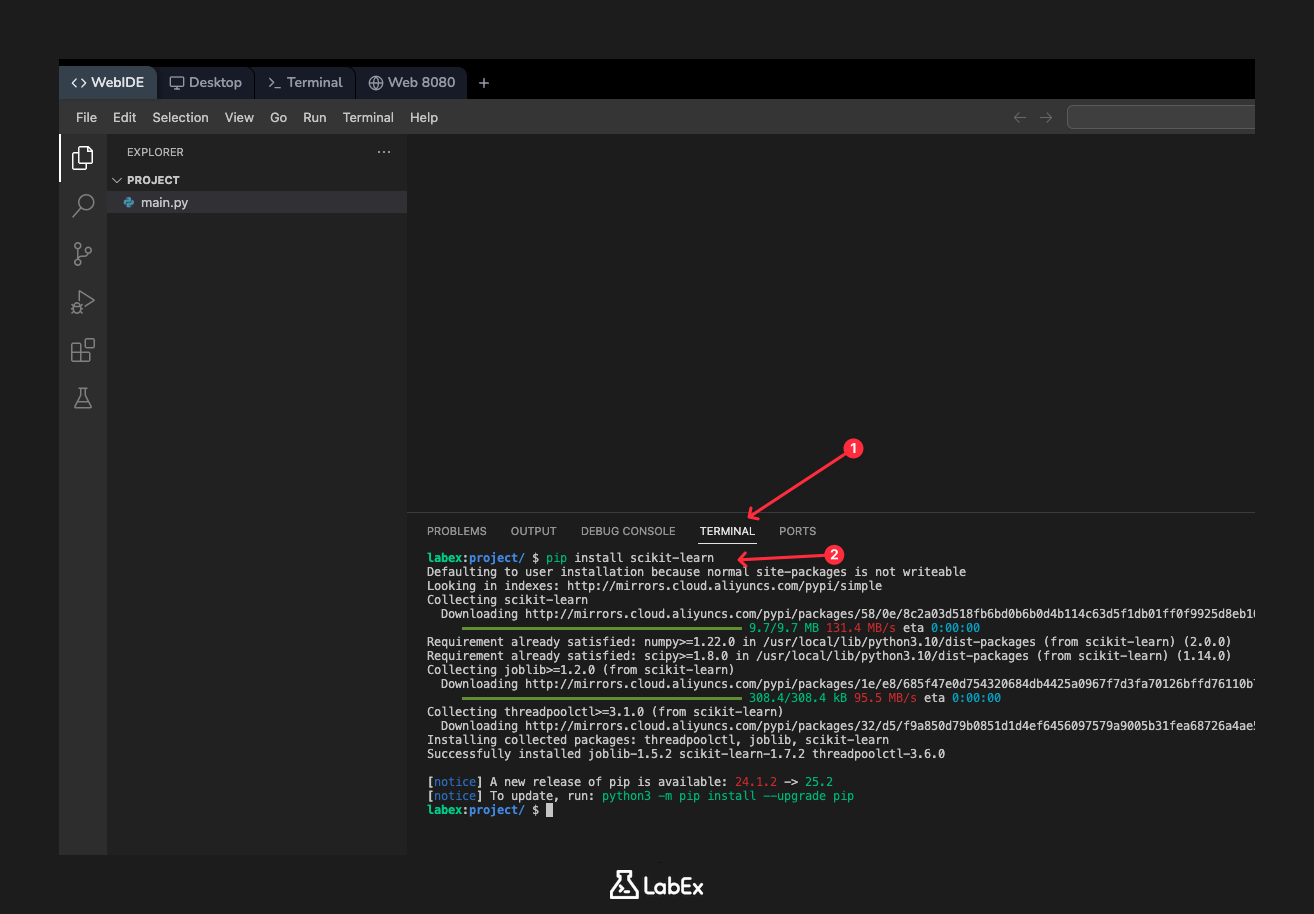
하지만 학습 경험을 더욱 원활하게 하기 위해 LabEx 환경에는 scikit-learn 과 그 종속성이 미리 설치되어 있습니다. 따라서 여기서는 설치 명령을 실행할 필요가 없습니다. 참고용으로 보여드리는 것이므로, 자신의 컴퓨터에 scikit-learn 을 설정하는 방법을 알 수 있습니다.
이제 라이브러리 사용을 시작하기 위해 다음 단계로 넘어가겠습니다.
from sklearn import datasets 를 사용하여 scikit-learn 가져오기
이 단계에서는 scikit-learn 라이브러리와 상호 작용하기 위한 첫 번째 Python 코드를 작성합니다. Python 에서 라이브러리의 함수나 객체를 사용하려면 먼저 스크립트로 가져와야 합니다.
Scikit-learn 에는 인기 있는 참조 데이터셋을 로드하고 가져오는 유틸리티를 포함하는 datasets라는 모듈이 있습니다. 나중에 사용할 이 모듈을 가져오겠습니다.
먼저 WebIDE 왼쪽의 파일 탐색기에서 main.py 파일을 찾습니다. 클릭하여 편집기에서 엽니다. 이제 main.py 파일에 다음 코드 줄을 추가합니다.
from sklearn import datasets
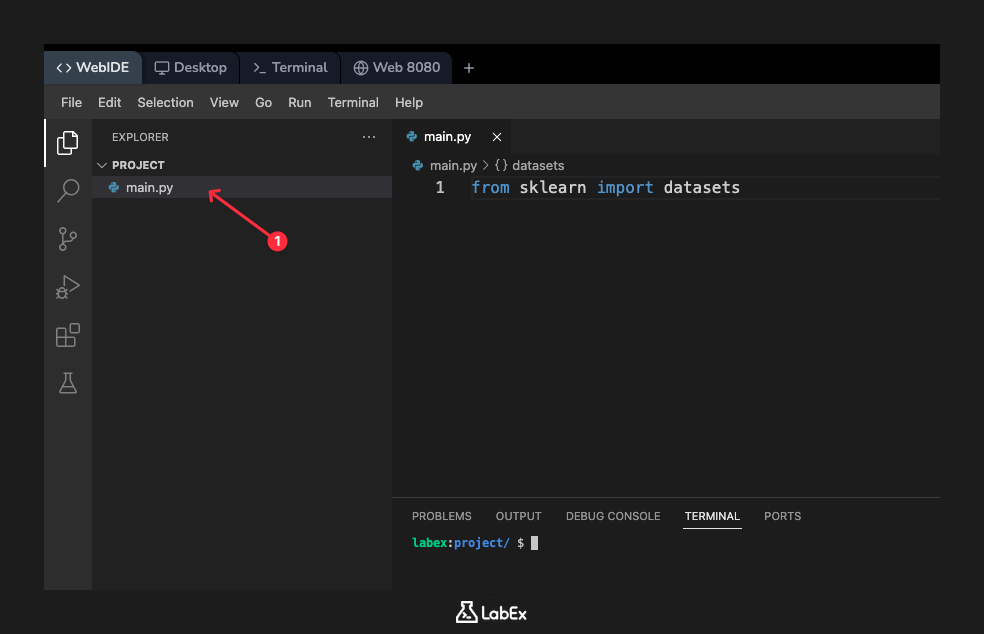
이 줄은 Python 에게 sklearn 라이브러리를 찾아서 그 안의 datasets 모듈을 가져오도록 지시하여, 해당 함수들을 사용할 수 있게 합니다. 코드를 추가한 후 파일을 저장합니다. 다음 단계에서 더 많은 코드를 추가하고 스크립트를 실행할 것입니다.
sklearn.__version__으로 설치 확인
이 단계에서는 scikit-learn 의 버전 번호를 확인하여 scikit-learn 이 올바르게 설치되고 접근 가능한지 확인할 것입니다. 이는 라이브러리가 환경에 올바르게 설정되었는지 확인하는 일반적인 방법입니다. 모든 scikit-learn 설치에는 이 정보가 포함된 특별한 속성인 __version__이 있습니다.
버전을 출력하기 위해 main.py 파일에 코드를 추가해 보겠습니다. 최상위 sklearn 패키지 자체도 가져와야 합니다. main.py 파일을 다음과 같이 수정하세요.
import sklearn
from sklearn import datasets
print(sklearn.__version__)
이제 이 스크립트를 실행해 보겠습니다. WebIDE 에서 터미널을 엽니다 (일반적으로 + 아이콘이나 "Terminal" 메뉴를 찾을 수 있습니다). 터미널은 /home/labex/project 디렉터리에서 열릴 것이며, 다음 명령을 실행합니다.
python3 main.py
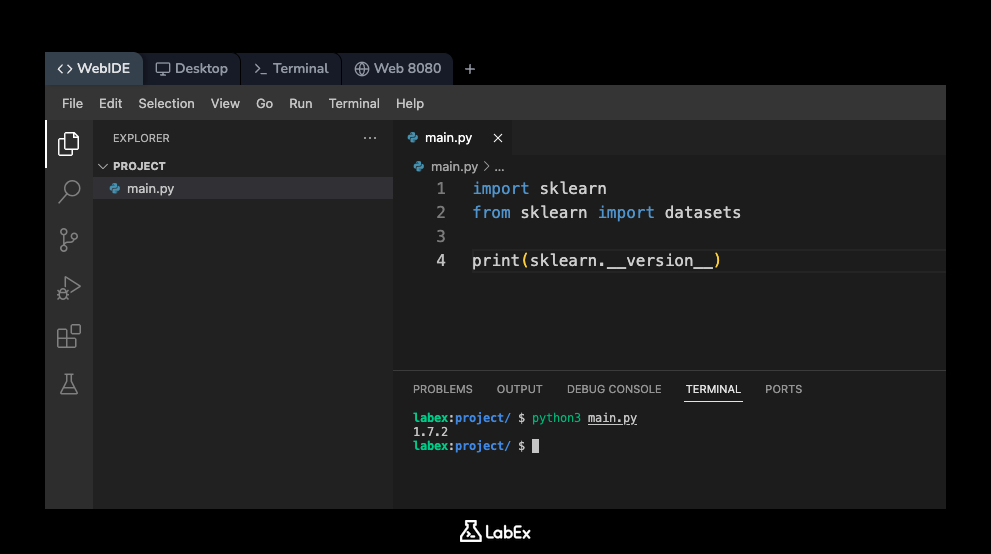
설치된 scikit-learn 버전이 콘솔에 출력되는 것을 볼 수 있습니다. 출력은 다음과 유사할 것입니다 (정확한 버전 번호는 다를 수 있습니다).
1.x.x
이를 통해 Python 이 scikit-learn 라이브러리를 성공적으로 가져와 사용할 수 있음을 확인할 수 있습니다.
datasets.load_iris() 를 사용하여 샘플 데이터셋 로드
이 단계에서는 이전에 가져온 datasets 모듈을 사용하여 샘플 데이터셋을 로드할 것입니다. Scikit-learn 에는 외부 웹사이트에서 다운로드할 필요가 없는 몇 가지 작고 표준적인 데이터셋이 포함되어 있습니다. 이는 시작하고 알고리즘을 테스트하는 데 유용합니다.
머신러닝 분야에서 고전적이고 매우 유명한 데이터셋인 Iris 데이터셋을 로드할 것입니다. 이 데이터셋은 세 가지 다른 종의 150 개 붓꽃 측정값을 포함합니다.
이를 로드하기 위해 datasets.load_iris() 함수를 사용합니다. main.py 파일을 수정하여 데이터셋을 로드하고 iris라는 변수에 저장해 보겠습니다. 또한 데이터셋이 로드되었음을 확인하기 위해 print 문을 추가할 것입니다.
main.py 파일을 다음 내용으로 업데이트하세요.
import sklearn
from sklearn import datasets
## Load the iris dataset
iris = datasets.load_iris()
print("Iris dataset loaded successfully.")
제안: 위의 코드를 코드 편집기에 복사한 다음 각 코드 줄을 주의 깊게 읽어 기능을 이해할 수 있습니다. 추가 설명이 필요한 경우 "코드 설명" 버튼 👆을 클릭할 수 있습니다. Labby 와 상호 작용하여 개인화된 도움을 받을 수 있습니다.
파일을 저장하고 터미널에서 다시 실행합니다.
python3 main.py
이제 출력은 다음과 같아야 합니다.
Iris dataset loaded successfully.
이는 load_iris() 함수가 오류 없이 실행되었으며 데이터셋이 이제 스크립트 내의 iris 변수에서 사용 가능함을 나타냅니다.
print(iris.keys()) 로 데이터셋 키 출력
이 단계에서는 방금 로드한 Iris 데이터셋의 구조를 살펴볼 것입니다. load_iris()에서 반환된 객체는 Python 사전과 유사한 Bunch 객체입니다. 이 객체에는 데이터셋을 설명하는 키와 값이 포함되어 있습니다.
어떤 정보가 사용 가능한지 확인하기 위해 .keys() 메서드를 사용하여 키를 출력할 수 있습니다. 이렇게 하면 데이터 자체, 대상 레이블, 설명 이름과 같은 데이터셋의 모든 구성 요소를 볼 수 있습니다.
main.py 파일을 수정하여 iris 객체의 키를 출력합니다. 최종 스크립트는 다음과 같아야 합니다.
import sklearn
from sklearn import datasets
## Load the iris dataset
iris = datasets.load_iris()
## Print the keys of the dataset
print(iris.keys())
파일을 저장하고 터미널에서 마지막으로 한 번 더 실행합니다.
python3 main.py
출력에는 데이터셋 객체의 다른 부분이 표시됩니다.
dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names', 'filename', 'data_module'])
가장 중요한 키에 대한 간략한 설명은 다음과 같습니다.
data: 특징 데이터 (꽃 측정값) 를 포함하는 배열입니다.target: 레이블 (각 꽃의 종) 을 포함하는 배열입니다.feature_names: 특징의 이름입니다 (예: 'sepal length (cm)').target_names: 대상 종의 이름입니다 (예: 'setosa').DESCR: 데이터셋에 대한 전체 설명입니다.
이러한 키를 출력함으로써 데이터셋을 성공적으로 로드하고 검사했으며, 기본 설정 프로세스를 완료했습니다.
요약
축하합니다! scikit-learn 환경 설정 및 확인에 대한 이 소개 랩을 성공적으로 완료했습니다.
이 랩에서는 다음을 배웠습니다.
- scikit-learn 설치 프로세스 이해하기.
- 라이브러리 버전을 확인하여 성공적인 설정을 확인하기.
- scikit-learn 라이브러리에서 모듈 가져오기.
- 내장 샘플 데이터셋인 Iris 데이터셋 로드하기.
- scikit-learn 데이터셋 객체의 기본 구조 검사하기.
이제 scikit-learn 에서 제공하는 강력한 도구를 사용하여 데이터 전처리, 모델 훈련 및 평가를 탐색할 더 흥미로운 랩으로 진행할 준비가 되었습니다.


