
소개
scikit-learn 과 함께하는 머신러닝의 세계에 오신 것을 환영합니다! 모든 머신러닝 프로젝트에서 가장 중요하고 첫 번째 단계는 데이터를 로드하고 이해하는 것입니다. Python 에서 강력하고 사용자 친화적인 머신러닝 라이브러리인 scikit-learn 은 시작하는 데 도움이 되는 여러 내장 데이터셋을 제공합니다.
이 실습에서는 유명한 Iris 꽃 데이터셋을 다룰 것입니다. 이 데이터셋을 로드하는 방법, 구조를 검사하는 방법, 특징 데이터와 타겟 레이블에 접근하는 방법, 그리고 마지막으로 데이터의 분포를 처음으로 살펴보기 위한 간단한 시각화를 만드는 방법을 배우게 됩니다. 이 기초 지식은 모든 신진 데이터 과학자 또는 머신러닝 엔지니어에게 필수적입니다.
datasets.load_iris() 로 Iris 데이터셋 로드하기
이 단계에서는 scikit-learn 의 내장 데이터셋 중 하나를 로드하는 방법을 배웁니다. sklearn.datasets 모듈의 load_iris() 함수를 사용할 것입니다. 이 함수는 Python 딕셔너리와 유사한 "Bunch" 객체를 반환하며, 데이터셋과 해당 메타데이터를 포함합니다.
먼저 화면 왼쪽의 파일 탐색기에서 main.py 파일을 엽니다. 모든 코드는 이 파일에 작성할 것입니다.
이제 필요한 모듈을 가져오고 데이터셋을 로드하기 위해 다음 코드를 main.py에 추가합니다.
from sklearn import datasets
## Iris 데이터셋 로드
iris = datasets.load_iris()
이 코드는 datasets 모듈을 가져오고 load_iris() 함수를 호출하여 결과 데이터셋 객체를 iris라는 변수에 저장합니다.
스크립트를 실행하려면 WebIDE 에서 터미널을 열고 (메뉴에서 "Terminal" -> "New Terminal"을 사용할 수 있습니다) 다음 명령을 실행합니다. 현재 디렉토리는 이미 ~/project입니다.
python3 main.py
아무런 출력도 보이지 않을 것이며, 이는 예상된 결과입니다. 데이터를 iris 변수에 로드했지만, 스크립트가 아직 아무것도 출력하도록 요청하지 않았습니다. 다음 단계에서는 이 iris 객체의 내용을 탐색할 것입니다.
iris.data 를 사용하여 데이터 배열 접근하기
이 단계에서는 데이터셋의 핵심인 특징 데이터에 접근합니다. 우리가 생성한 iris 객체는 data라는 속성을 포함하고 있으며, 이 속성은 각 꽃의 측정값으로 구성된 NumPy 배열을 담고 있습니다. 각 행은 샘플 (꽃) 을 나타내고, 각 열은 특징 (측정값) 을 나타냅니다.
main.py 파일을 수정하여 이 데이터 배열을 출력하고 어떻게 보이는지 확인해 봅시다.
main.py 파일을 다음 코드로 업데이트하세요:
from sklearn import datasets
## Iris 데이터셋 로드
iris = datasets.load_iris()
## 데이터 배열 출력
print(iris.data)
이제 터미널에서 스크립트를 다시 실행합니다:
python3 main.py
터미널에 많은 숫자로 이루어진 배열이 출력되는 것을 볼 수 있습니다. 이것이 데이터셋에 있는 150 개의 모든 꽃 샘플에 대한 특징 데이터입니다. 각 샘플은 4 개의 특징을 가지고 있습니다.
[[5.1 3.5 1.4 0.2]
[4.9 3. 1.4 0.2]
[4.7 3.2 1.3 0.2]
...
[6.5 3. 5.2 2. ]
[6.2 3.4 5.4 2.3]
[5.9 3. 5.1 1.8]]
iris.target 를 사용하여 타겟 배열 접근하기
이 단계에서는 데이터셋의 각 샘플에 대한 레이블에 접근합니다. 지도 학습 (supervised machine learning) 에서 이러한 레이블을 "타겟 (target)"이라고 합니다. iris 객체는 이를 target 속성에 저장합니다. Iris 데이터셋의 경우, 타겟은 각 꽃의 종 (species) 을 나타냅니다.
종은 정수로 인코딩됩니다: 세토사 (setosa) 는 0, 버시컬러 (versicolor) 는 1, 버지니카 (virginica) 는 2입니다. iris.target 속성은 iris.data의 각 샘플에 해당하는 정수를 포함하는 NumPy 배열입니다.
main.py를 수정하여 타겟 배열을 출력해 봅시다.
from sklearn import datasets
## Iris 데이터셋 로드
iris = datasets.load_iris()
## 타겟 배열 출력
print(iris.target)
터미널에서 스크립트를 실행합니다:
python3 main.py
출력에는 150 개의 꽃 각각에 대한 종을 나타내는 0, 1, 2 로 이루어진 배열이 표시됩니다.
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]
iris.feature_names 로 특성 이름 탐색하기
이 단계에서는 iris.data 배열의 열이 실제로 무엇을 나타내는지 알아보는 방법을 배웁니다. 네 가지 특징이 있다는 것은 알지만, 데이터 배열 자체만으로는 그 이름이 명확하지 않습니다. iris 객체는 이러한 이름을 feature_names 속성에 편리하게 저장합니다.
이는 데이터를 이해하고 해석하는 데 매우 유용합니다. main.py를 수정하여 이러한 특징 이름을 출력해 봅시다.
main.py 파일을 업데이트하세요:
from sklearn import datasets
## Iris 데이터셋 로드
iris = datasets.load_iris()
## 특징 이름 출력
print(iris.feature_names)
이제 터미널에서 스크립트를 실행합니다:
python3 main.py
출력은 문자열 리스트로, iris.data의 네 개 열 각각에 대한 이름을 제공합니다.
['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
이제 네 가지 특징이 각각 꽃받침 길이 (sepal length), 꽃받침 너비 (sepal width), 꽃잎 길이 (petal length), 꽃잎 너비 (petal width) 에 해당하며, 모두 센티미터 (cm) 단위임을 알 수 있습니다.
matplotlib.pyplot.scatter(iris.data[:, 0], iris.data[:, 1]) 를 사용하여 데이터 시각화하기
이 마지막 단계에서는 두 특징 간의 관계를 보기 위한 간단한 데이터 시각화를 수행합니다. 시각화는 데이터 탐색의 핵심 부분입니다. Python 에서 인기 있는 플로팅 도구인 matplotlib 라이브러리를 사용하여 산점도 (scatter plot) 를 생성할 것입니다.
첫 번째 특징 (꽃받침 길이) 과 두 번째 특징 (꽃받침 너비) 을 플로팅할 것입니다. 데이터에서 이러한 열을 선택하기 위해 NumPy 슬라이싱을 사용합니다:
iris.data[:, 0]은 모든 행 (:) 과 첫 번째 열 (0) 을 선택합니다.iris.data[:, 1]은 모든 행 (:) 과 두 번째 열 (1) 을 선택합니다.
이 환경에 이상적이지 않은 화면에 플롯을 표시하는 대신, iris_plot.png라는 이미지 파일로 저장할 것입니다.
main.py 파일을 다음 코드로 업데이트하세요:
from sklearn import datasets
import matplotlib.pyplot as plt
## Iris 데이터셋 로드
iris = datasets.load_iris()
## 처음 두 특징을 플로팅합니다: 꽃받침 길이 vs 꽃받침 너비
X = iris.data[:, :2]
y = iris.target
plt.scatter(X[:, 0], X[:, 1])
plt.xlabel('Sepal Length (cm)')
plt.ylabel('Sepal Width (cm)')
plt.title('Sepal Length vs Sepal Width')
## 플롯을 파일로 저장
plt.savefig('iris_plot.png')
print("Plot saved to iris_plot.png")
터미널에서 스크립트를 실행합니다:
python3 main.py
확인 메시지가 표시됩니다.
Plot saved to iris_plot.png
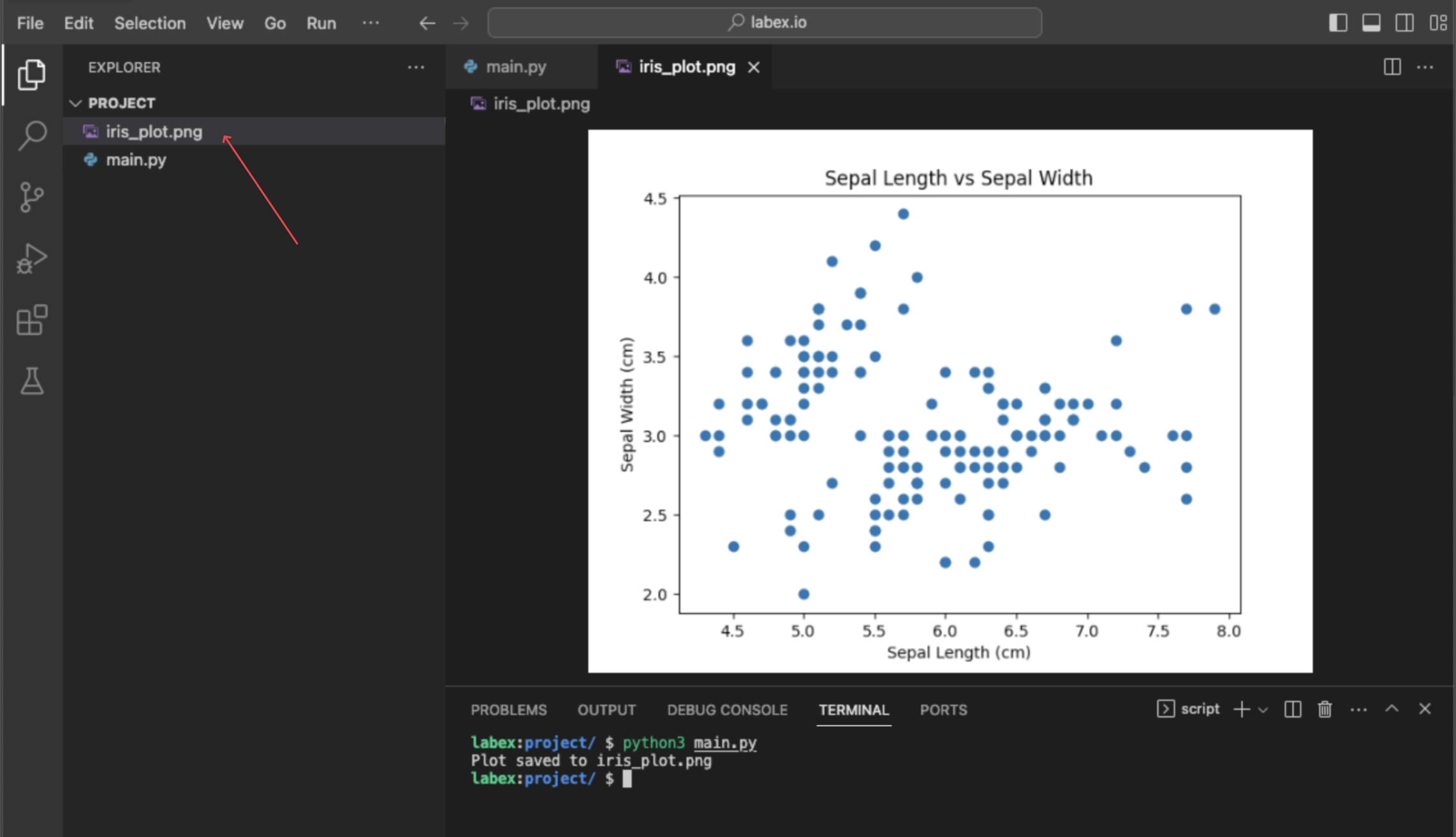
이 명령은 플롯을 직접 표시하지는 않지만, ~/project 디렉토리에 iris_plot.png라는 새 파일을 생성합니다. 왼쪽 파일 탐색기에서 이 파일을 더블 클릭하여 산점도를 볼 수 있습니다.
요약
이 랩을 완료하신 것을 축하드립니다! scikit-learn 으로 데이터 처리의 첫 단계를 성공적으로 밟으셨습니다.
이 랩에서는 다음을 배웠습니다:
sklearn.datasets.load_iris()를 사용하여 내장 데이터셋을 로드하는 방법..data속성을 사용하여 특징 행렬에 접근하는 방법..target속성을 사용하여 타겟 레이블에 접근하는 방법..feature_names속성을 검사하여 특징의 의미를 이해하는 방법.matplotlib으로 산점도를 생성하고 파일로 저장하여 기본적인 데이터 시각화를 수행하는 방법.
이러한 기본적인 기술은 더 고급 머신러닝 작업을 위한 구성 요소입니다. 이제 다른 데이터셋을 탐색하고 자신만의 머신러닝 모델 구축을 시작할 준비가 되었습니다.


