소개
이 섹션에서는 Python 의 내부 객체 모델에 대한 자세한 내용을 소개하고 메모리 관리, 복사 및 타입 검사와 관련된 몇 가지 사항을 논의합니다.
할당 (Assignment)
Python 의 많은 연산은 값을 할당하거나 저장하는 것과 관련이 있습니다.
a = value ## Assignment to a variable
s[n] = value ## Assignment to a list
s.append(value) ## Appending to a list
d['key'] = value ## Adding to a dictionary
주의 사항: 할당 연산은 절대로 할당되는 값의 복사본을 만들지 않습니다. 모든 할당은 단순히 참조 복사 (또는 선호하는 경우 포인터 복사) 입니다.
할당 예시
다음 코드 조각을 고려해 보겠습니다.
a = [1,2,3]
b = a
c = [a,b]
기본 메모리 연산의 그림입니다. 이 예제에서는 [1,2,3] 리스트 객체가 하나만 있지만, 이에 대한 네 개의 서로 다른 참조가 있습니다.
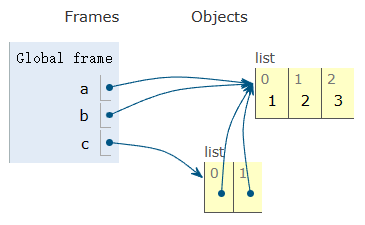
이는 값을 수정하면 모든 참조에 영향을 미친다는 것을 의미합니다.
>>> a.append(999)
>>> a
[1,2,3,999]
>>> b
[1,2,3,999]
>>> c
[[1,2,3,999], [1,2,3,999]]
>>>
원래 리스트의 변경 사항이 다른 모든 곳에 어떻게 나타나는지 확인하세요 (이런!). 이는 복사본이 전혀 만들어지지 않았기 때문입니다. 모든 것이 동일한 것을 가리키고 있습니다.
값 재할당
값을 재할당하는 것은 절대로 이전 값이 사용하던 메모리를 덮어쓰지 않습니다.
a = [1,2,3]
b = a
a = [4,5,6]
print(a) ## [4, 5, 6]
print(b) ## [1, 2, 3] Holds the original value
기억하세요: 변수는 메모리 위치가 아닌 이름입니다.
몇 가지 위험 요소
이 공유에 대해 모르면 언젠가는 스스로 발등을 찍게 될 것입니다. 전형적인 시나리오입니다. 자신의 개인적인 복사본이라고 생각하고 일부 데이터를 수정했는데, 실수로 프로그램의 다른 부분에서 일부 데이터가 손상됩니다.
주석: 이것이 기본 데이터 유형 (int, float, string) 이 불변 (읽기 전용) 인 이유 중 하나입니다.
동일성 (Identity) 과 참조 (References)
두 값이 정확히 동일한 객체인지 확인하려면 is 연산자를 사용하십시오.
>>> a = [1,2,3]
>>> b = a
>>> a is b
True
>>>
is는 객체 동일성 (정수) 을 비교합니다. 동일성은 id()를 사용하여 얻을 수 있습니다.
>>> id(a)
3588944
>>> id(b)
3588944
>>>
참고: 객체를 확인할 때는 거의 항상 ==를 사용하는 것이 좋습니다. is의 동작은 종종 예상치 못한 결과를 보입니다.
>>> a = [1,2,3]
>>> b = a
>>> c = [1,2,3]
>>> a is b
True
>>> a is c
False
>>> a == c
True
>>>
얕은 복사 (Shallow copies)
리스트와 딕셔너리에는 복사 방법이 있습니다.
>>> a = [2,3,[100,101],4]
>>> b = list(a) ## Make a copy
>>> a is b
False
새로운 리스트이지만, 리스트 항목은 공유됩니다.
>>> a[2].append(102)
>>> b[2]
[100,101,102]
>>>
>>> a[2] is b[2]
True
>>>
예를 들어, 내부 리스트 [100, 101, 102]가 공유되고 있습니다. 이것을 얕은 복사라고 합니다. 다음은 그림입니다.
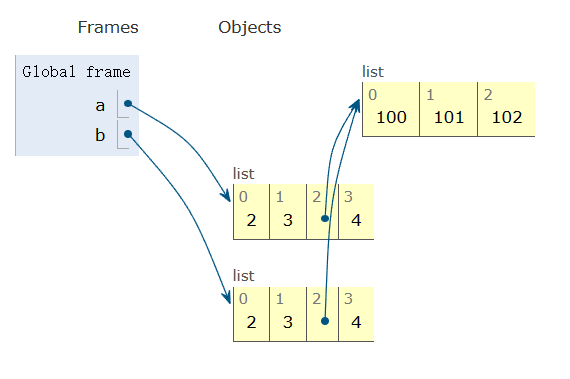
깊은 복사 (Deep copies)
때로는 객체와 그 안에 포함된 모든 객체의 복사본을 만들어야 할 필요가 있습니다. 이를 위해 copy 모듈을 사용할 수 있습니다.
>>> a = [2,3,[100,101],4]
>>> import copy
>>> b = copy.deepcopy(a)
>>> a[2].append(102)
>>> b[2]
[100,101]
>>> a[2] is b[2]
False
>>>
이름, 값, 타입 (Names, Values, Types)
변수 이름은 타입을 가지지 않습니다. 그것은 단지 이름일 뿐입니다. 하지만, 값은 근본적인 타입을 가지고 있습니다.
>>> a = 42
>>> b = 'Hello World'
>>> type(a)
<type 'int'>
>>> type(b)
<type 'str'>
type()은 그것이 무엇인지 알려줍니다. 타입 이름은 일반적으로 값을 해당 타입으로 생성하거나 변환하는 함수로 사용됩니다.
타입 검사 (Type Checking)
객체가 특정 타입인지 확인하는 방법.
if isinstance(a, list):
print('a is a list')
여러 가능한 타입 중 하나를 확인하는 방법.
if isinstance(a, (list,tuple)):
print('a is a list or tuple')
*주의: 타입 검사를 과도하게 사용하지 마십시오. 이는 과도한 코드 복잡성을 초래할 수 있습니다. 일반적으로, 다른 사용자가 코드를 사용할 때 흔히 저지르는 실수를 방지할 수 있는 경우에만 수행하는 것이 좋습니다.
모든 것은 객체 (Everything is an object)
숫자, 문자열, 리스트, 함수, 예외, 클래스, 인스턴스 등은 모두 객체입니다. 이는 이름을 지정할 수 있는 모든 객체가 데이터로 전달되고, 컨테이너에 배치되는 등, 어떠한 제약 없이 사용될 수 있음을 의미합니다. 특별한 종류의 객체는 없습니다. 때로는 모든 객체가 "일급 객체 (first-class)"라고 말하기도 합니다.
간단한 예시:
>>> import math
>>> items = [abs, math, ValueError ]
>>> items
[<built-in function abs>,
<module 'math' (builtin)>,
<type 'exceptions.ValueError'>]
>>> items[0](-45)
45
>>> items[1].sqrt(2)
1.4142135623730951
>>> try:
x = int('not a number')
except items[2]:
print('Failed!')
Failed!
>>>
여기서 items는 함수, 모듈 및 예외를 포함하는 리스트입니다. 원래 이름 대신 리스트의 항목을 직접 사용할 수 있습니다.
items[0](-45) ## abs
items[1].sqrt(2) ## math
except items[2]: ## ValueError
큰 힘에는 책임이 따릅니다. 그렇게 할 수 있다고 해서 반드시 해야 하는 것은 아닙니다.
이 일련의 연습에서는 일급 객체에서 비롯되는 몇 가지 강력한 기능에 대해 살펴봅니다.
연습 문제 2.24: 일급 데이터 (First-class Data)
portfolio.csv 파일에서 다음과 같은 열로 구성된 데이터를 읽습니다.
name,shares,price
"AA",100,32.20
"IBM",50,91.10
...
이전 코드에서는 csv 모듈을 사용하여 파일을 읽었지만, 여전히 수동적인 타입 변환을 수행해야 했습니다. 예를 들어:
for row in rows:
name = row[0]
shares = int(row[1])
price = float(row[2])
이러한 종류의 변환은 몇 가지 리스트 기본 연산을 사용하여 더 영리하게 수행할 수도 있습니다.
각 열을 적절한 타입으로 변환하는 데 사용할 변환 함수의 이름을 포함하는 Python 리스트를 만드십시오.
>>> types = [str, int, float]
>>>
이 리스트를 생성할 수 있는 이유는 Python 의 모든 것이 일급 (first-class) 이기 때문입니다. 따라서 함수 리스트를 원한다면 괜찮습니다. 생성한 리스트의 항목은 값 x를 주어진 타입으로 변환하는 함수입니다 (예: str(x), int(x), float(x)).
이제 위 파일에서 데이터 행을 읽어보세요.
>>> import csv
>>> f = open('portfolio.csv')
>>> rows = csv.reader(f)
>>> headers = next(rows)
>>> row = next(rows)
>>> row
['AA', '100', '32.20']
>>>
알려진 바와 같이, 이 행은 타입이 잘못되어 계산을 수행하기에 충분하지 않습니다. 예를 들어:
>>> row[1] * row[2]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: can't multiply sequence by non-int of type 'str'
>>>
그러나 데이터는 types에 지정한 타입과 짝을 이룰 수 있습니다. 예를 들어:
>>> types[1]
<type 'int'>
>>> row[1]
'100'
>>>
값 중 하나를 변환해 보세요.
>>> types[1](row[1]) ## Same as int(row[1])
100
>>>
다른 값을 변환해 보세요.
>>> types[2](row[2]) ## Same as float(row[2])
32.2
>>>
변환된 값으로 계산을 시도해 보세요.
>>> types[1](row[1])*types[2](row[2])
3220.0000000000005
>>>
열 타입을 필드와 함께 zip 하고 결과를 살펴보세요.
>>> r = list(zip(types, row))
>>> r
[(<type 'str'>, 'AA'), (<type 'int'>, '100'), (<type 'float'>,'32.20')]
>>>
이것이 타입 변환과 값을 짝지었다는 것을 알 수 있습니다. 예를 들어, int는 값 '100'과 짝을 이룹니다.
zip 된 리스트는 모든 값에 대해 하나씩 변환을 수행하려는 경우 유용합니다. 다음을 시도해 보세요.
>>> converted = []
>>> for func, val in zip(types, row):
converted.append(func(val))
...
>>> converted
['AA', 100, 32.2]
>>> converted[1] * converted[2]
3220.0000000000005
>>>
위 코드에서 무슨 일이 일어나고 있는지 이해했는지 확인하십시오. 루프에서 func 변수는 타입 변환 함수 중 하나입니다 (예: str, int 등) 그리고 val 변수는 'AA', '100'과 같은 값 중 하나입니다. 표현식 func(val)은 값을 변환합니다 (일종의 타입 캐스트).
위 코드는 단일 리스트 컴프리헨션으로 압축할 수 있습니다.
>>> converted = [func(val) for func, val in zip(types, row)]
>>> converted
['AA', 100, 32.2]
>>>
연습 문제 2.25: 딕셔너리 만들기 (Making dictionaries)
dict() 함수가 키 이름과 값의 시퀀스가 있는 경우 딕셔너리를 쉽게 만들 수 있다는 것을 기억하십니까? 열 헤더에서 딕셔너리를 만들어 봅시다.
>>> headers
['name', 'shares', 'price']
>>> converted
['AA', 100, 32.2]
>>> dict(zip(headers, converted))
{'price': 32.2, 'name': 'AA', 'shares': 100}
>>>
물론, 리스트 컴프리헨션 (list-comprehension) 실력이 있다면, 딕셔너리 컴프리헨션 (dict-comprehension) 을 사용하여 전체 변환을 한 단계로 수행할 수 있습니다.
>>> { name: func(val) for name, func, val in zip(headers, types, row) }
{'price': 32.2, 'name': 'AA', 'shares': 100}
>>>
연습 문제 2.26: 전체 그림 (The Big Picture)
이 연습 문제의 기술을 사용하여 거의 모든 열 지향 데이터 파일의 필드를 Python 딕셔너리로 쉽게 변환하는 문을 작성할 수 있습니다.
단지 예시를 위해, 다음과 같이 다른 데이터 파일에서 데이터를 읽는다고 가정해 봅시다.
>>> f = open('dowstocks.csv')
>>> rows = csv.reader(f)
>>> headers = next(rows)
>>> row = next(rows)
>>> headers
['name', 'price', 'date', 'time', 'change', 'open', 'high', 'low', 'volume']
>>> row
['AA', '39.48', '6/11/2007', '9:36am', '-0.18', '39.67', '39.69', '39.45', '181800']
>>>
비슷한 트릭을 사용하여 필드를 변환해 봅시다.
>>> types = [str, float, str, str, float, float, float, float, int]
>>> converted = [func(val) for func, val in zip(types, row)]
>>> record = dict(zip(headers, converted))
>>> record
{'volume': 181800, 'name': 'AA', 'price': 39.48, 'high': 39.69,
'low': 39.45, 'time': '9:36am', 'date': '6/11/2007', 'open': 39.67,
'change': -0.18}
>>> record['name']
'AA'
>>> record['price']
39.48
>>>
보너스: date 항목을 (6, 11, 2007)와 같은 튜플로 추가로 구문 분석하도록 이 예제를 어떻게 수정하시겠습니까?
이 연습 문제에서 수행한 작업을 숙고하는 데 시간을 할애하십시오. 이러한 아이디어는 나중에 다시 살펴볼 것입니다.
요약 (Summary)
축하합니다! 객체 (Objects) 랩을 완료했습니다. LabEx 에서 더 많은 랩을 연습하여 실력을 향상시킬 수 있습니다.