
소개
이 튜토리얼에서는 Python 의 defaultdict 데이터 구조를 살펴보겠습니다. 이는 표준 딕셔너리의 강력한 변형으로, 누락된 키를 우아하게 처리합니다. 특히, 기본값이 0 인 defaultdict를 생성하는 방법을 배우고, 이는 Python 프로그램에서 값을 계산하고 누적하는 데 특히 유용합니다.
이 랩을 마치면 defaultdict가 무엇인지, 기본값 0 으로 defaultdict를 생성하는 방법, 그리고 실용적인 시나리오에서 이를 적용하여 더 우아하고 오류에 강한 코드를 작성하는 방법을 이해하게 될 것입니다.
일반 딕셔너리의 문제점 이해
defaultdict에 대해 알아보기 전에, defaultdict가 해결하는 일반 딕셔너리의 제한 사항을 먼저 이해해 보겠습니다.
KeyError 문제
Python 에서 표준 딕셔너리 (dict) 는 키 - 값 쌍을 저장하는 데 사용됩니다. 그러나 일반 딕셔너리에 존재하지 않는 키에 접근하려고 하면 Python 은 KeyError를 발생시킵니다.
이 문제를 보여주는 간단한 예제를 만들어 보겠습니다.
- 편집기에서
regular_dict_demo.py라는 새 파일을 만듭니다.
## 과일 개수를 세기 위한 일반 딕셔너리 생성
fruit_counts = {}
## 'apple'의 개수를 증가시키려고 시도
try:
fruit_counts['apple'] += 1
except KeyError:
print("KeyError: 'apple' 키가 딕셔너리에 존재하지 않습니다")
## 일반 딕셔너리로 이 작업을 수행하는 올바른 방법
if 'banana' in fruit_counts:
fruit_counts['banana'] += 1
else:
fruit_counts['banana'] = 1
print(f"과일 개수: {fruit_counts}")
- 터미널에서 스크립트를 실행합니다.
python3 regular_dict_demo.py
다음과 유사한 출력을 볼 수 있습니다.
KeyError: 'apple' 키가 딕셔너리에 존재하지 않습니다
과일 개수: {'banana': 1}
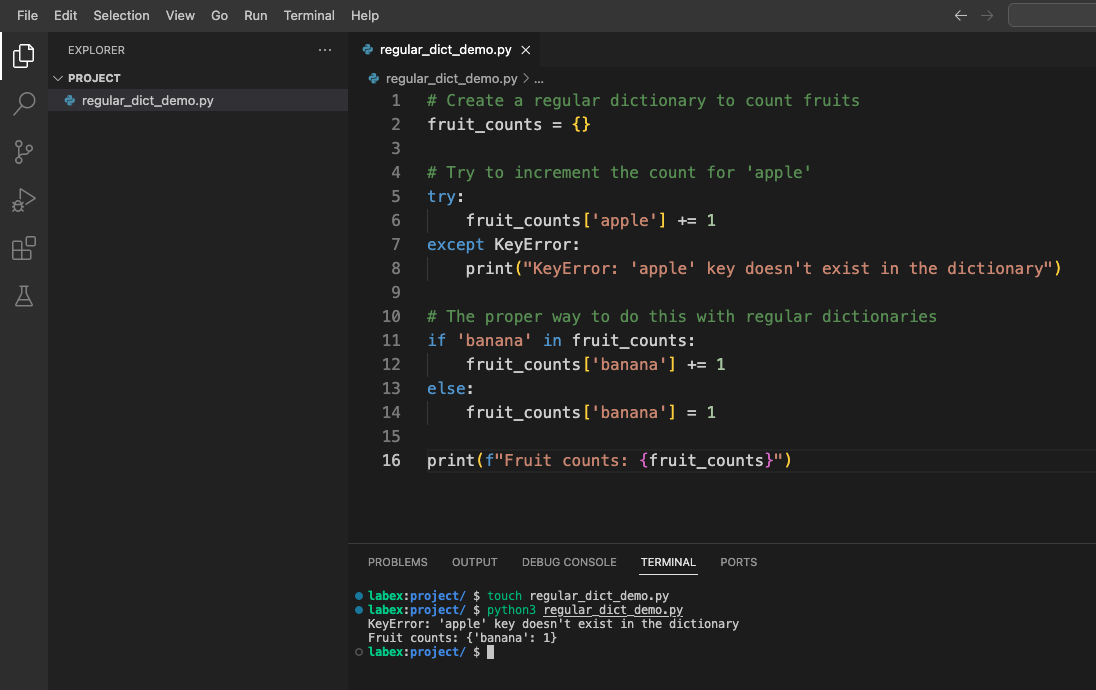
보시다시피, 존재하지 않는 키의 개수를 증가시키려고 하면 오류가 발생합니다. 일반적인 해결 방법은 키에 접근하기 전에 키가 존재하는지 확인하는 것이며, 이는 더 장황한 코드로 이어집니다.
이때 defaultdict가 등장합니다. defaultdict는 접근 시 기본값으로 키를 생성하여 누락된 키를 자동으로 처리합니다.
기본값 0 을 가진 defaultdict 소개
이제 일반 딕셔너리의 문제점을 이해했으므로, defaultdict를 사용하여 이를 해결하는 방법을 알아보겠습니다.
defaultdict 란 무엇인가요?
defaultdict는 Python 의 내장 dict 클래스의 하위 클래스로, 첫 번째 인수로 함수 ( "default factory"라고 함) 를 받습니다. 존재하지 않는 키에 접근하면 defaultdict는 default factory 함수가 반환하는 값으로 해당 키를 자동으로 생성합니다.
기본값 0 으로 defaultdict 생성하기
누락된 키에 대해 기본값 0 을 제공하는 defaultdict를 만들어 보겠습니다.
- 편집기에서
default_dict_zero.py라는 새 파일을 만듭니다.
## 먼저 collections 모듈에서 defaultdict 클래스를 import 합니다.
from collections import defaultdict
## 방법 1: int 를 default factory 로 사용
## 인자 없이 호출된 int() 함수는 0 을 반환합니다.
counter = defaultdict(int)
print("counter 의 초기 상태:", dict(counter))
## 아직 존재하지 않는 키에 접근합니다.
print("'apple'의 값 (전):", counter['apple'])
## 개수를 증가시킵니다.
counter['apple'] += 1
counter['apple'] += 1
counter['banana'] += 1
print("'apple'의 값 (후):", counter['apple'])
print("연산 후 딕셔너리:", dict(counter))
## 방법 2: 람다 함수 사용 (대안적 접근 방식)
counter2 = defaultdict(lambda: 0)
print("\n람다 함수 사용:")
print("'cherry'의 값 (전):", counter2['cherry'])
counter2['cherry'] += 5
print("'cherry'의 값 (후):", counter2['cherry'])
print("연산 후 딕셔너리:", dict(counter2))
- 터미널에서 스크립트를 실행합니다.
python3 default_dict_zero.py
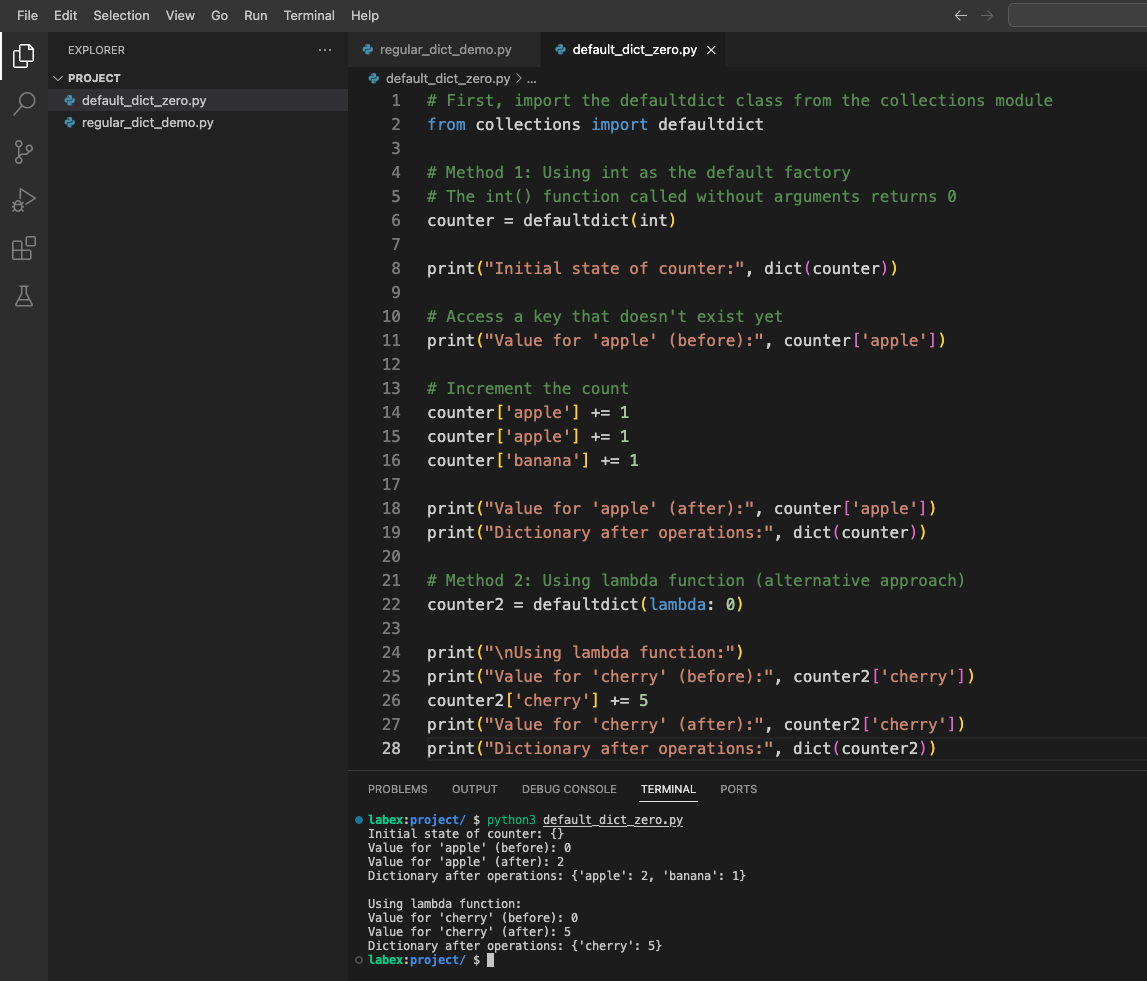
다음과 유사한 출력을 볼 수 있습니다.
counter의 초기 상태: {}
'apple'의 값 (전): 0
'apple'의 값 (후): 2
연산 후 딕셔너리: {'apple': 2, 'banana': 1}
람다 함수 사용:
'cherry'의 값 (전): 0
'cherry'의 값 (후): 5
연산 후 딕셔너리: {'cherry': 5}
작동 방식
defaultdict(int)를 생성할 때, Python 에게 int() 함수를 default factory 로 사용하도록 지시하는 것입니다. 인자 없이 호출되면 int()는 0 을 반환하며, 이는 누락된 키의 기본값이 됩니다.
마찬가지로, 호출 시 단순히 0 을 반환하는 람다 함수 lambda: 0을 사용할 수 있습니다.
이전에 존재하지 않던 키의 값을 직접 접근하고 증가시킬 수 있으며, 오류가 발생하지 않는 것을 확인하세요.
실용적인 사용 사례: 단어 빈도수 세기
기본값 0 을 가진 defaultdict의 가장 일반적인 응용 프로그램 중 하나는 빈도수 세기입니다. 이 실용적인 사용 사례를 보여주기 위해 단어 빈도수 카운터를 구현해 보겠습니다.
- 편집기에서
word_counter.py라는 새 파일을 만듭니다.
from collections import defaultdict
def count_word_frequencies(text):
## 기본값 0 으로 defaultdict 생성
word_counts = defaultdict(int)
## 텍스트를 단어로 분할하고 소문자로 변환
words = text.lower().split()
## 각 단어를 정리 (구두점 제거) 하고 발생 횟수를 셉니다.
for word in words:
## 일반적인 구두점 제거
clean_word = word.strip('.,!?:;()"\'')
if clean_word: ## 빈 문자열 건너뛰기
word_counts[clean_word] += 1
return word_counts
## 샘플 텍스트로 함수 테스트
sample_text = """
Python is amazing! Python is easy to learn, and Python is very powerful.
With Python, you can create web applications, analyze data, build games,
and automate tasks. Python's syntax is clear and readable.
"""
word_frequencies = count_word_frequencies(sample_text)
## 결과 출력
print("단어 빈도수:")
for word, count in sorted(word_frequencies.items()):
print(f" {word}: {count}")
## 가장 흔한 단어 찾기
print("\n가장 흔한 단어:")
sorted_words = sorted(word_frequencies.items(), key=lambda x: x[1], reverse=True)
for word, count in sorted_words[:5]: ## 상위 5 개 단어
print(f" {word}: {count}")
- 터미널에서 스크립트를 실행합니다.
python3 word_counter.py
다음과 유사한 출력을 볼 수 있습니다.
단어 빈도수:
amazing: 1
analyze: 1
and: 3
applications: 1
automate: 1
build: 1
can: 1
clear: 1
create: 1
data: 1
easy: 1
games: 1
is: 4
learn: 1
powerful: 1
python: 4
python's: 1
readable: 1
syntax: 1
tasks: 1
to: 1
very: 1
web: 1
with: 1
you: 1
가장 흔한 단어:
python: 4
is: 4
and: 3
amazing: 1
easy: 1
작동 방식
- 기본값 0 으로 단어 개수를 저장하기 위해
defaultdict(int)를 생성합니다. - 텍스트의 각 단어를 처리하고 구두점을 정리합니다.
word_counts[word] += 1을 사용하여 각 단어의 개수를 간단히 증가시킵니다.- 처음 나타나는 단어의 경우 기본값 0 이 자동으로 할당됩니다.
이 접근 방식은 존재 여부를 확인하는 일반 딕셔너리를 사용하는 것보다 훨씬 더 깔끔하고 효율적입니다.
기본값 0 을 가진 defaultdict 사용의 장점
- 코드 단순화: 증가시키기 전에 키가 존재하는지 확인할 필요가 없습니다.
- 코드 라인 수 감소: 상용구 키 존재 확인을 제거합니다.
- 오류 감소: 잠재적인 KeyError 예외를 제거합니다.
- 가독성 향상: 계산 로직을 더 명확하고 간결하게 만듭니다.
기본값 0 을 가진 defaultdict는 다음과 같이 계산 또는 값 누적이 필요한 모든 작업에 특히 유용합니다.
- 빈도 분석
- 히스토그램
- 범주별 데이터 집계
- 로그 또는 데이터 세트에서 발생 횟수 추적
성능 비교: defaultdict vs. 일반 dict
일반적인 계산 작업에 대해 기본값 0 을 가진 defaultdict와 일반 딕셔너리의 성능을 비교해 보겠습니다. 이를 통해 어떤 경우에 무엇을 선택해야 하는지 이해하는 데 도움이 됩니다.
- 편집기에서
performance_comparison.py라는 새 파일을 만듭니다.
import time
from collections import defaultdict
def count_with_regular_dict(data):
"""일반 딕셔너리를 사용하여 빈도수를 계산합니다."""
counts = {}
for item in data:
if item in counts:
counts[item] += 1
else:
counts[item] = 1
return counts
def count_with_defaultdict(data):
"""기본값 0 을 가진 defaultdict 를 사용하여 빈도수를 계산합니다."""
counts = defaultdict(int)
for item in data:
counts[item] += 1
return counts
## 테스트 데이터 생성 - 0 과 99 사이의 난수 목록
import random
random.seed(42) ## 재현 가능한 결과를 위해
data = [random.randint(0, 99) for _ in range(1000000)]
## 일반 딕셔너리 방식의 시간 측정
start_time = time.time()
result1 = count_with_regular_dict(data)
regular_dict_time = time.time() - start_time
## defaultdict 방식의 시간 측정
start_time = time.time()
result2 = count_with_defaultdict(data)
defaultdict_time = time.time() - start_time
## 결과 출력
print(f"일반 딕셔너리 시간: {regular_dict_time:.4f} 초")
print(f"defaultdict 시간: {defaultdict_time:.4f} 초")
print(f"defaultdict 는 {regular_dict_time/defaultdict_time:.2f}배 빠릅니다")
## 두 방법이 동일한 결과를 제공하는지 확인
assert dict(result2) == result1, "계산 결과가 일치하지 않습니다!"
print("\n두 방법 모두 동일한 개수를 생성했습니다 ✓")
## 개수의 샘플 출력
print("\n샘플 개수 (처음 5 개 항목):")
for i, (key, value) in enumerate(sorted(result1.items())):
if i >= 5:
break
print(f" Number {key}: {value} occurrences")
- 터미널에서 스크립트를 실행합니다.
python3 performance_comparison.py
다음과 유사한 출력을 볼 수 있습니다.
일반 딕셔너리 시간: 0.1075 초
defaultdict 시간: 0.0963 초
defaultdict는 1.12배 빠릅니다
두 방법 모두 동일한 개수를 생성했습니다 ✓
샘플 개수 (처음 5개 항목):
Number 0: 10192 occurrences
Number 1: 9949 occurrences
Number 2: 9929 occurrences
Number 3: 9881 occurrences
Number 4: 9922 occurrences
참고: 정확한 시간 결과는 시스템에 따라 다를 수 있습니다.
결과 분석
성능 비교 결과 defaultdict가 일반 딕셔너리보다 계산 작업에서 일반적으로 더 빠르다는 것을 보여줍니다. 그 이유는 다음과 같습니다.
- 키 존재 여부 확인 (
if key in dictionary) 이 필요하지 않습니다. - 항목당 딕셔너리 조회의 수를 줄입니다.
- 코드를 단순화하여 Python 인터프리터의 최적화를 유도할 수 있습니다.
성능상의 이점 외에도 defaultdict는 다음과 같은 장점을 제공합니다.
- 코드 단순성: 코드가 더 간결하고 읽기 쉽습니다.
- 인지 부하 감소: 누락된 키의 경우를 처리하는 것을 기억할 필요가 없습니다.
- 버그 발생 기회 감소: 코드가 적을수록 오류 발생 기회가 줄어듭니다.
이러한 이유로 기본값 0 을 가진 defaultdict는 Python 에서 계산 작업, 빈도 분석 및 기타 누적 작업에 매우 적합합니다.
요약
이 랩에서는 Python 의 defaultdict와 기본값 0 으로 사용하는 방법에 대해 배웠습니다. 다룬 내용을 요약해 보겠습니다.
- 존재하지 않는 키에 접근할 때
KeyError를 발생시키는 일반 딕셔너리의 제한 사항을 확인했습니다. defaultdict(int)와defaultdict(lambda: 0)을 사용하여 기본값 0 으로defaultdict를 만드는 방법을 배웠습니다.- 단어 빈도수 카운터를 구현하여 실용적인 사용 사례를 탐구했습니다.
defaultdict와 일반 딕셔너리의 성능을 비교해 본 결과,defaultdict가 더 편리할 뿐만 아니라 계산 작업에서도 더 빠르다는 것을 확인했습니다.
기본값 0 을 가진 defaultdict는 Python 에서 계산, 누적 및 빈도 분석을 단순화하는 강력한 도구입니다. 누락된 키를 자동으로 처리하여 코드를 더 깔끔하고 효율적이며 오류 발생 가능성을 줄여줍니다.
이 패턴은 일반적으로 다음과 같은 경우에 사용됩니다.
- 데이터 처리 및 분석
- 자연어 처리
- 로그 분석
- 게임 개발 (점수 시스템용)
- 카운터 또는 누산기가 관련된 모든 시나리오
기본값 0 을 가진 defaultdict를 마스터함으로써 더 우아하고 효율적인 코드를 작성하는 데 도움이 되는 중요한 도구를 Python 프로그래밍 도구 상자에 추가했습니다.


