
소개
이 랩에서는 PostgreSQL 테이블 생성과 데이터 유형을 탐구합니다. 목표는 테이블 구조를 정의하고 데이터 무결성을 보장하는 데 중요한 정수, 텍스트, 날짜, 부울과 같은 기본적인 데이터 유형을 이해하는 것입니다.
psql을 사용하여 PostgreSQL 데이터베이스에 연결하고, SERIAL을 사용하여 기본 키가 있는 테이블을 생성하며, NOT NULL 및 UNIQUE와 같은 기본적인 제약 조건을 추가합니다. 그런 다음 테이블 구조를 검사하고 INTEGER, SMALLINT, TEXT, VARCHAR(n), 및 CHAR(n)과 같은 다양한 데이터 유형의 사용법을 보여주기 위해 데이터를 삽입합니다.
PostgreSQL 데이터 유형 탐색
이 단계에서는 PostgreSQL 에서 사용할 수 있는 몇 가지 기본적인 데이터 유형을 탐구합니다. 데이터 유형을 이해하는 것은 테이블 구조를 정의하고 데이터 무결성을 보장하는 데 매우 중요합니다. 정수, 텍스트, 날짜, 부울과 같은 일반적인 유형을 다룰 것입니다.
먼저, PostgreSQL 데이터베이스에 연결해 보겠습니다. 터미널을 열고 psql 명령을 사용하여 postgres 사용자로 postgres 데이터베이스에 연결합니다. postgres 사용자는 기본 슈퍼유저이므로, 먼저 sudo를 사용하여 해당 사용자로 전환해야 할 수 있습니다.
sudo -u postgres psql
이제 PostgreSQL 대화형 터미널에 접속됩니다. postgres=#와 같은 프롬프트가 표시됩니다.
이제 몇 가지 기본 데이터 유형을 살펴보겠습니다.
1. 정수 유형:
PostgreSQL 은 다양한 범위를 가진 여러 정수 유형을 제공합니다. 가장 일반적인 유형은 INTEGER (또는 INT) 및 SMALLINT입니다.
INTEGER: 대부분의 정수 값에 대한 일반적인 선택입니다.SMALLINT: 공간을 절약하기 위해 더 작은 정수 값에 사용됩니다.
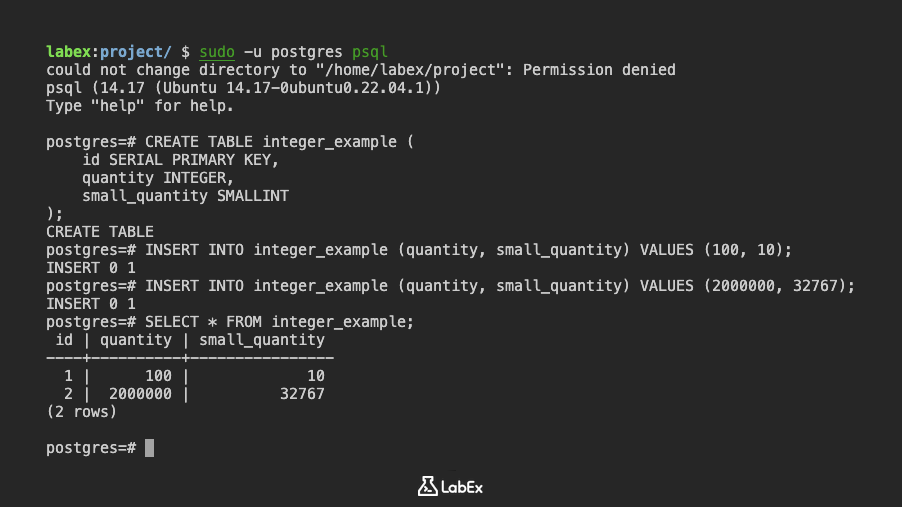
이러한 유형을 시연하기 위해 간단한 테이블을 만들어 보겠습니다.
CREATE TABLE integer_example (
id SERIAL PRIMARY KEY,
quantity INTEGER,
small_quantity SMALLINT
);
여기서 SERIAL은 일련의 정수를 자동으로 생성하는 특수한 유형으로, 기본 키에 적합합니다.
이제 데이터를 삽입합니다.
INSERT INTO integer_example (quantity, small_quantity) VALUES (100, 10);
INSERT INTO integer_example (quantity, small_quantity) VALUES (2000000, 32767);
다음 명령을 사용하여 데이터를 볼 수 있습니다.
SELECT * FROM integer_example;
출력:
id | quantity | small_quantity
----+----------+----------------
1 | 100 | 10
2 | 2000000 | 32767
(2 rows)
2. 텍스트 유형:
PostgreSQL 은 텍스트 저장을 위해 TEXT, VARCHAR(n), 및 CHAR(n)을 제공합니다.
TEXT: 무제한 길이의 가변 길이 문자열을 저장합니다.VARCHAR(n): 최대 길이가n인 가변 길이 문자열을 저장합니다.CHAR(n): 길이가n인 고정 길이 문자열을 저장합니다. 문자열이 짧으면 공백으로 채워집니다.
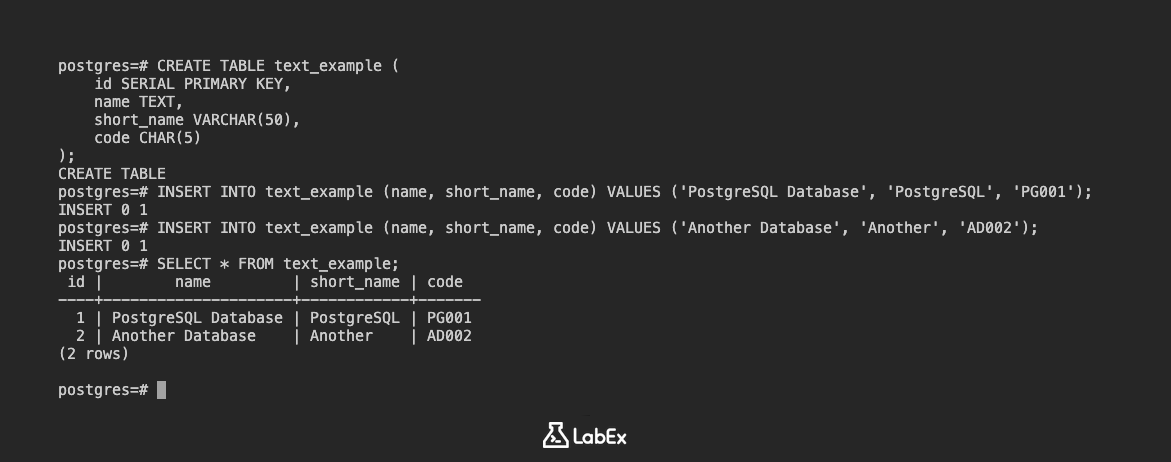
다른 테이블을 만들어 보겠습니다.
CREATE TABLE text_example (
id SERIAL PRIMARY KEY,
name TEXT,
short_name VARCHAR(50),
code CHAR(5)
);
데이터를 삽입합니다.
INSERT INTO text_example (name, short_name, code) VALUES ('PostgreSQL Database', 'PostgreSQL', 'PG001');
INSERT INTO text_example (name, short_name, code) VALUES ('Another Database', 'Another', 'AD002');
데이터를 봅니다.
SELECT * FROM text_example;
출력:
id | name | short_name | code
----+--------------------+------------+-------
1 | PostgreSQL Database | PostgreSQL | PG001
2 | Another Database | Another | AD002
(2 rows)
3. 날짜 및 시간 유형:
PostgreSQL 은 날짜 및 시간 값을 처리하기 위해 DATE, TIME, TIMESTAMP, 및 TIMESTAMPTZ를 제공합니다.
DATE: 날짜 (년, 월, 일) 만 저장합니다.TIME: 시간 (시, 분, 초) 만 저장합니다.TIMESTAMP: 시간대 정보 없이 날짜와 시간을 모두 저장합니다.TIMESTAMPTZ: 시간대 정보와 함께 날짜와 시간을 모두 저장합니다.
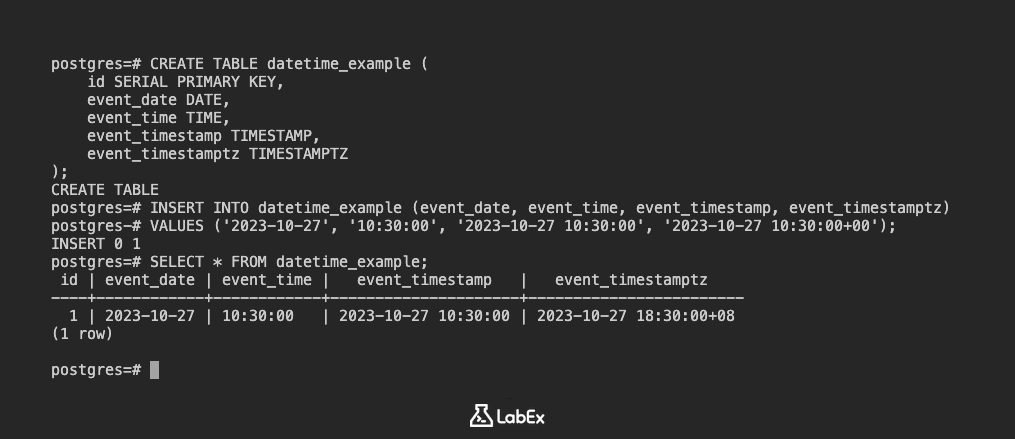
테이블을 만듭니다.
CREATE TABLE datetime_example (
id SERIAL PRIMARY KEY,
event_date DATE,
event_time TIME,
event_timestamp TIMESTAMP,
event_timestamptz TIMESTAMPTZ
);
데이터를 삽입합니다.
INSERT INTO datetime_example (event_date, event_time, event_timestamp, event_timestamptz)
VALUES ('2023-10-27', '10:30:00', '2023-10-27 10:30:00', '2023-10-27 10:30:00+00');
데이터를 봅니다.
SELECT * FROM datetime_example;
출력:
id | event_date | event_time | event_timestamp | event_timestamptz
----+------------+------------+---------------------+----------------------------
1 | 2023-10-27 | 10:30:00 | 2023-10-27 10:30:00 | 2023-10-27 10:30:00+00
(1 row)
4. 부울 유형:
BOOLEAN 유형은 true/false 값을 저장합니다.
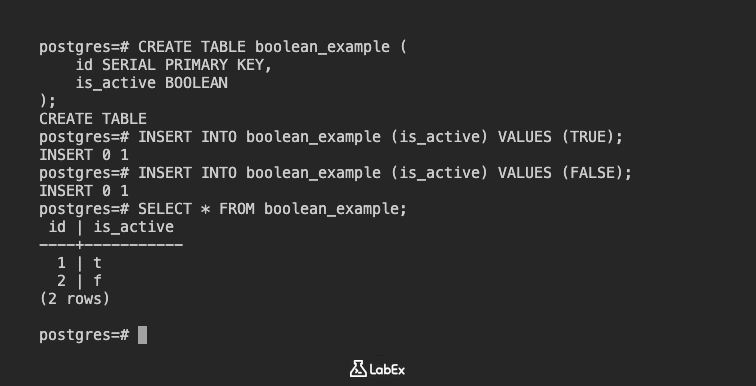
테이블을 만듭니다.
CREATE TABLE boolean_example (
id SERIAL PRIMARY KEY,
is_active BOOLEAN
);
데이터를 삽입합니다.
INSERT INTO boolean_example (is_active) VALUES (TRUE);
INSERT INTO boolean_example (is_active) VALUES (FALSE);
데이터를 봅니다.
SELECT * FROM boolean_example;
출력:
id | is_active
----+-----------
1 | t
2 | f
(2 rows)
마지막으로, psql 터미널을 종료합니다.
\q
이제 PostgreSQL 의 몇 가지 기본적인 데이터 유형을 탐구했습니다. 이러한 데이터 유형은 강력하고 잘 정의된 데이터베이스 스키마를 만들기 위한 구성 요소입니다.
기본 키를 사용하여 테이블 생성
이 단계에서는 PostgreSQL 에서 기본 키로 테이블을 생성하는 방법을 배웁니다. 기본 키는 테이블의 각 행을 고유하게 식별하는 열 또는 열 집합입니다. 고유성을 강제하며 데이터 무결성 및 테이블 간의 관계에 중요한 요소로 작용합니다.
먼저, PostgreSQL 데이터베이스에 연결해 보겠습니다. 터미널을 열고 psql 명령을 사용하여 postgres 사용자로 postgres 데이터베이스에 연결합니다.
sudo -u postgres psql
이제 PostgreSQL 대화형 터미널에 접속됩니다.
기본 키 이해
기본 키는 다음과 같은 특징을 가지고 있습니다.
- 고유한 값을 포함해야 합니다.
NULL값을 포함할 수 없습니다.- 테이블은 하나의 기본 키만 가질 수 있습니다.
기본 키로 테이블 생성
테이블을 생성할 때 기본 키를 정의하는 두 가지 일반적인 방법이 있습니다.
열 정의 내에서
PRIMARY KEY제약 조건 사용:CREATE TABLE products ( product_id SERIAL PRIMARY KEY, product_name VARCHAR(100), price DECIMAL(10, 2) );이 예에서
product_id는PRIMARY KEY제약 조건을 사용하여 기본 키로 정의됩니다.SERIAL키워드는product_id에 대한 고유한 정수 값을 생성하기 위해 시퀀스를 자동으로 생성합니다.PRIMARY KEY제약 조건을 별도로 사용:CREATE TABLE customers ( customer_id INT, first_name VARCHAR(50), last_name VARCHAR(50), PRIMARY KEY (customer_id) );여기서는
PRIMARY KEY제약 조건이 별도로 정의되어customer_id열이 기본 키임을 지정합니다.
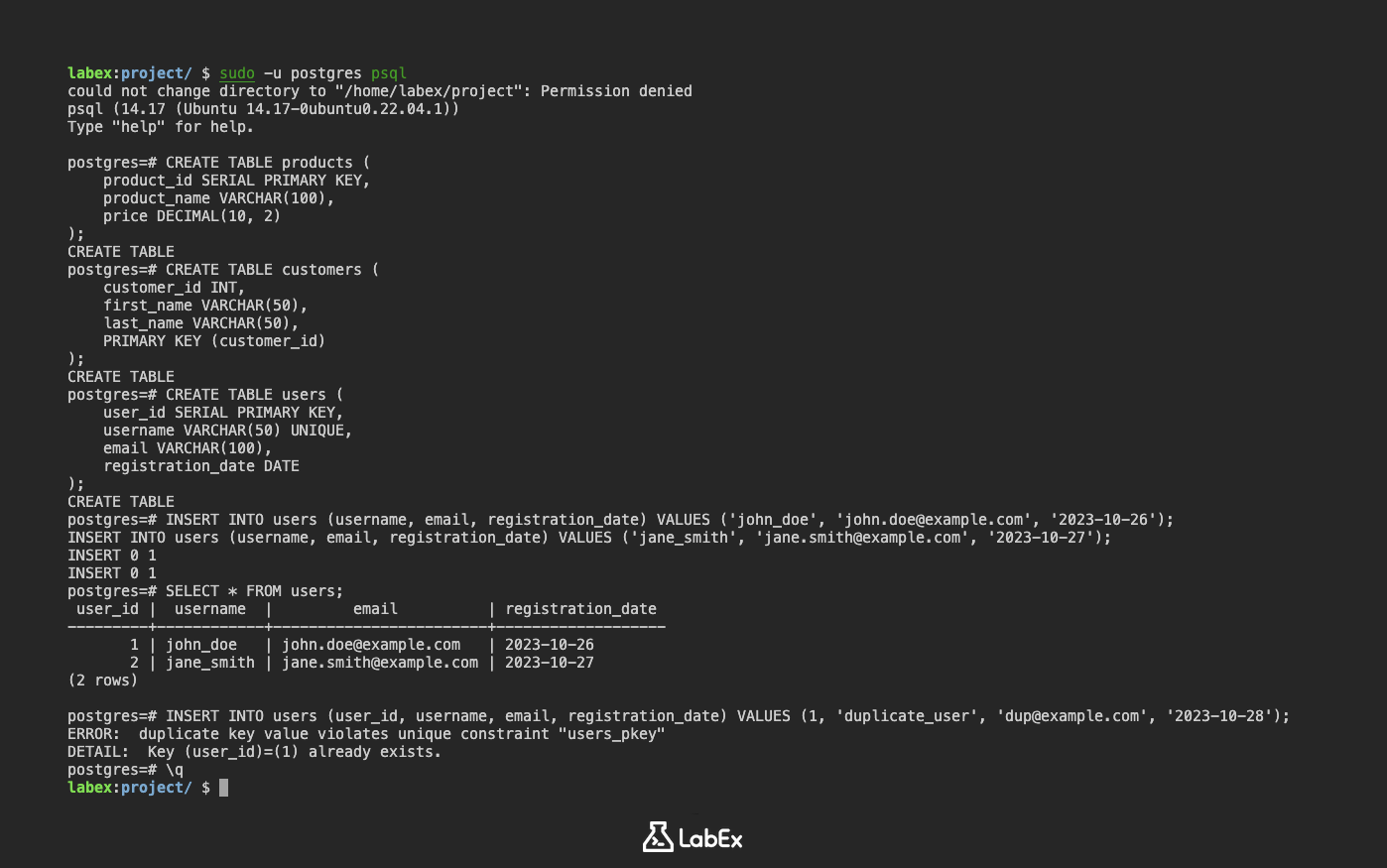
예시: 기본 키가 있는 users 테이블 생성
자동 ID 생성을 위해 SERIAL 유형을 사용하여 기본 키가 있는 users 테이블을 만들어 보겠습니다.
CREATE TABLE users (
user_id SERIAL PRIMARY KEY,
username VARCHAR(50) UNIQUE,
email VARCHAR(100),
registration_date DATE
);
이 테이블에서:
user_id는SERIAL을 사용하여 자동으로 생성되는 기본 키입니다.username은 각 사용자에 대한 고유한 사용자 이름입니다.email은 사용자의 이메일 주소입니다.registration_date는 사용자가 등록한 날짜입니다.
이제 users 테이블에 데이터를 삽입해 보겠습니다.
INSERT INTO users (username, email, registration_date) VALUES ('john_doe', 'john.doe@example.com', '2023-10-26');
INSERT INTO users (username, email, registration_date) VALUES ('jane_smith', 'jane.smith@example.com', '2023-10-27');
다음 명령을 사용하여 데이터를 볼 수 있습니다.
SELECT * FROM users;
출력:
user_id | username | email | registration_date
---------+------------+---------------------+---------------------
1 | john_doe | john.doe@example.com | 2023-10-26
2 | jane_smith | jane.smith@example.com | 2023-10-27
(2 rows)
중복 기본 키를 삽입하려고 시도
중복 기본 키가 있는 행을 삽입하려고 하면 PostgreSQL 에서 오류가 발생합니다.
INSERT INTO users (user_id, username, email, registration_date) VALUES (1, 'duplicate_user', 'dup@example.com', '2023-10-28');
출력:
ERROR: duplicate key value violates unique constraint "users_pkey"
DETAIL: Key (user_id)=(1) already exists.
이는 기본 키 제약 조건이 작동하여 중복 값을 방지하는 것을 보여줍니다.
마지막으로, psql 터미널을 종료합니다.
\q
이제 기본 키로 테이블을 성공적으로 생성하고 고유성을 강제하는 방법을 확인했습니다. 이는 데이터베이스 설계의 기본 개념입니다.
기본 제약 조건 추가 (NOT NULL, UNIQUE)
이 단계에서는 PostgreSQL 에서 테이블에 기본 제약 조건을 추가하는 방법을 배웁니다. 제약 조건은 데이터 무결성 및 일관성을 적용하는 규칙입니다. NOT NULL 및 UNIQUE의 두 가지 기본적인 제약 조건에 중점을 둘 것입니다.
먼저, PostgreSQL 데이터베이스에 연결해 보겠습니다. 터미널을 열고 psql 명령을 사용하여 postgres 사용자로 postgres 데이터베이스에 연결합니다.
sudo -u postgres psql
이제 PostgreSQL 대화형 터미널에 접속됩니다.
제약 조건 이해
제약 조건은 테이블에 삽입할 수 있는 데이터 유형을 제한하는 데 사용됩니다. 이를 통해 데이터베이스의 데이터 정확성과 신뢰성을 보장합니다.
1. NOT NULL 제약 조건
NOT NULL 제약 조건은 열이 NULL 값을 포함할 수 없도록 합니다. 이 제약 조건은 테이블의 모든 행에 필수적인 특정 정보가 있을 때 유용합니다.
2. UNIQUE 제약 조건
UNIQUE 제약 조건은 열의 모든 값이 고유하도록 합니다. 이 제약 조건은 사용자 이름 또는 이메일 주소 (기본 키 외) 와 같이 고유 식별자 또는 값을 가져야 하는 열에 유용합니다.
테이블 생성 중 제약 조건 추가
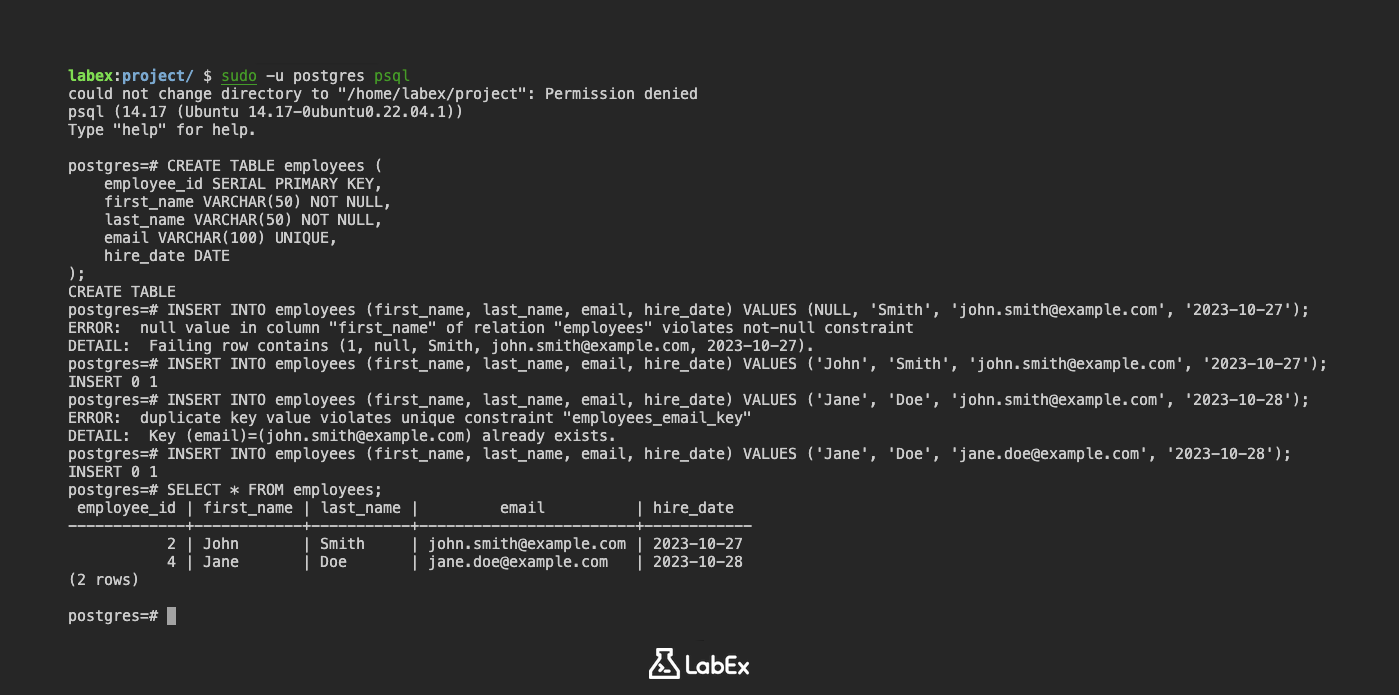
테이블을 생성할 때 제약 조건을 추가할 수 있습니다. NOT NULL 및 UNIQUE 제약 조건이 있는 employees라는 테이블을 만들어 보겠습니다.
CREATE TABLE employees (
employee_id SERIAL PRIMARY KEY,
first_name VARCHAR(50) NOT NULL,
last_name VARCHAR(50) NOT NULL,
email VARCHAR(100) UNIQUE,
hire_date DATE
);
이 테이블에서:
employee_id는 기본 키입니다.first_name및last_name은NOT NULL로 선언되어 모든 직원에 대해 값을 가져야 함을 의미합니다.email은UNIQUE로 선언되어 각 직원이 고유한 이메일 주소를 갖도록 합니다.
이제 이러한 제약 조건을 위반하는 데이터를 삽입해 보겠습니다.
NOT NULL 열에 NULL 값을 삽입하려고 시도:
INSERT INTO employees (first_name, last_name, email, hire_date) VALUES (NULL, 'Smith', 'john.smith@example.com', '2023-10-27');
출력:
ERROR: null value in column "first_name" of relation "employees" violates not-null constraint
DETAIL: Failing row contains (1, null, Smith, john.smith@example.com, 2023-10-27).
이 오류는 NOT NULL 제약 조건 때문에 first_name 열에 NULL 값을 삽입할 수 없음을 나타냅니다.
UNIQUE 열에 중복 값을 삽입하려고 시도:
먼저, 유효한 행을 삽입합니다.
INSERT INTO employees (first_name, last_name, email, hire_date) VALUES ('John', 'Smith', 'john.smith@example.com', '2023-10-27');
이제 동일한 이메일로 다른 행을 삽입해 보겠습니다.
INSERT INTO employees (first_name, last_name, email, hire_date) VALUES ('Jane', 'Doe', 'john.smith@example.com', '2023-10-28');
출력:
ERROR: duplicate key value violates unique constraint "employees_email_key"
DETAIL: Key (email)=(john.smith@example.com) already exists.
이 오류는 UNIQUE 제약 조건 때문에 중복 이메일 주소를 삽입할 수 없음을 나타냅니다.
유효한 데이터 삽입:
INSERT INTO employees (first_name, last_name, email, hire_date) VALUES ('Jane', 'Doe', 'jane.doe@example.com', '2023-10-28');
데이터를 봅니다.
SELECT * FROM employees;
출력:
employee_id | first_name | last_name | email | hire_date
-------------+------------+-----------+---------------------+------------
1 | John | Smith | john.smith@example.com | 2023-10-27
2 | Jane | Doe | jane.doe@example.com | 2023-10-28
(2 rows)
마지막으로, psql 터미널을 종료합니다.
\q
이제 NOT NULL 및 UNIQUE 제약 조건으로 테이블을 성공적으로 생성하고 데이터 무결성을 적용하는 방법을 확인했습니다.
테이블 구조 검사
이 단계에서는 PostgreSQL 에서 테이블의 구조를 검사하는 방법을 배웁니다. 열 이름, 데이터 유형, 제약 조건 및 인덱스를 포함하여 테이블의 구조를 이해하는 것은 데이터를 효과적으로 쿼리하고 조작하는 데 필수적입니다.
먼저, PostgreSQL 데이터베이스에 연결해 보겠습니다. 터미널을 열고 psql 명령을 사용하여 postgres 사용자로 postgres 데이터베이스에 연결합니다.
sudo -u postgres psql
이제 PostgreSQL 대화형 터미널에 접속됩니다.
\d 명령
psql에서 테이블 구조를 검사하는 주요 도구는 \d (describe, 설명) 명령입니다. 이 명령은 다음을 포함하여 테이블에 대한 자세한 정보를 제공합니다.
- 열 이름 및 데이터 유형
- 제약 조건 (기본 키, 고유 제약 조건, not-null 제약 조건)
- 인덱스
employees 테이블 검사
이전 단계에서 생성한 employees 테이블의 구조를 검사해 보겠습니다.
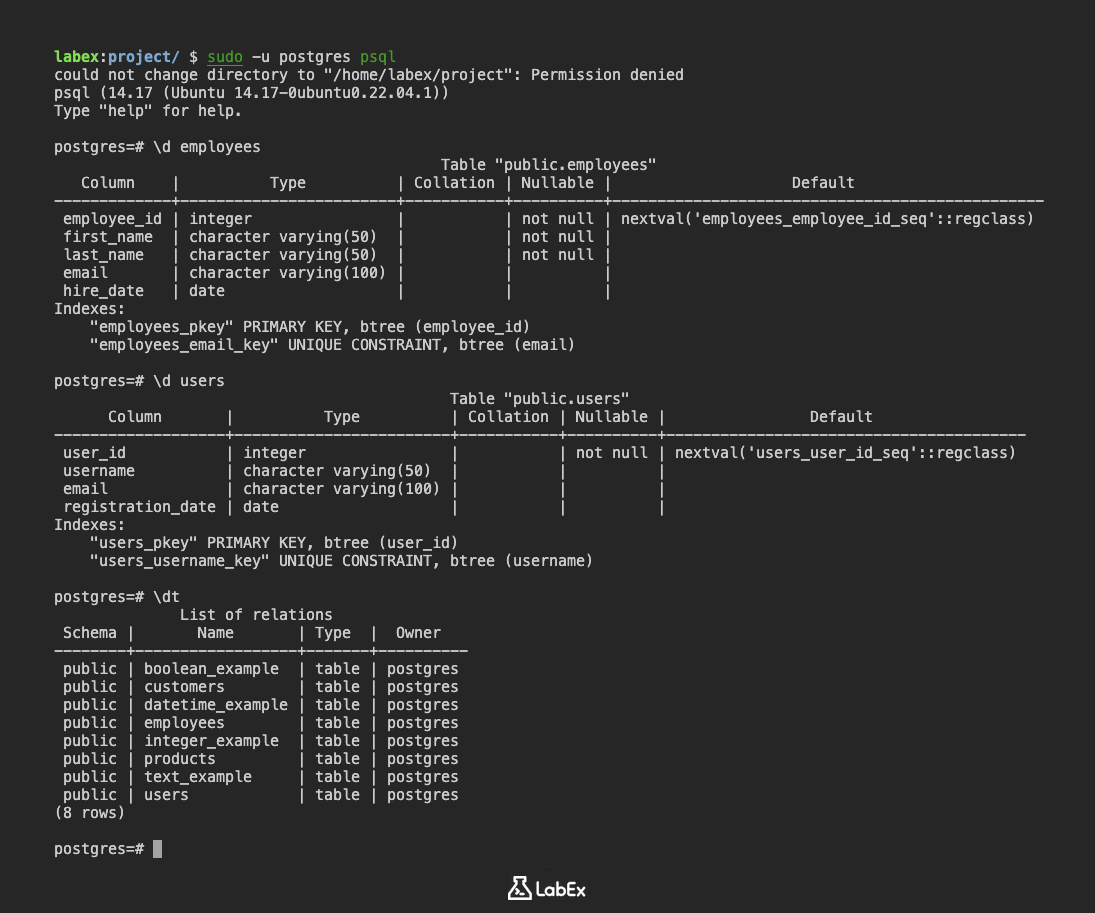
\d employees
출력:
Table "public.employees"
Column | Type | Collation | Nullable | Default
-------------+------------------------+-----------+----------+------------------------------------------------
employee_id | integer | | not null | nextval('employees_employee_id_seq'::regclass)
first_name | character varying(50) | | not null |
last_name | character varying(50) | | not null |
email | character varying(100) | | |
hire_date | date | | |
Indexes:
"employees_pkey" PRIMARY KEY, btree (employee_id)
"employees_email_key" UNIQUE CONSTRAINT, btree (email)
출력은 다음 정보를 제공합니다.
- Table "public.employees": 테이블 이름과 스키마를 나타냅니다.
- Column: 열 이름 (
employee_id,first_name,last_name,email,hire_date) 을 나열합니다. - Type: 각 열의 데이터 유형 (
integer,character varying,date) 을 보여줍니다. - Nullable: 열이
NULL값을 포함할 수 있는지 여부를 나타냅니다 (not null또는 공백). - Default: 열의 기본값 (있는 경우) 을 보여줍니다.
- Indexes: 기본 키 (
employees_pkey) 및email열의 고유 제약 조건 (employees_email_key) 을 포함하여 테이블에 정의된 인덱스를 나열합니다.
다른 테이블 검사
\d 명령을 사용하여 데이터베이스의 모든 테이블을 검사할 수 있습니다. 예를 들어, 2 단계에서 생성된 users 테이블을 검사하려면 다음을 수행합니다.
\d users
출력:
Table "public.users"
Column | Type | Collation | Nullable | Default
-------------------+------------------------+-----------+----------+----------------------------------------
user_id | integer | | not null | nextval('users_user_id_seq'::regclass)
username | character varying(50) | | |
email | character varying(100) | | |
registration_date | date | | |
Indexes:
"users_pkey" PRIMARY KEY, btree (user_id)
"users_username_key" UNIQUE CONSTRAINT, btree (username)
모든 테이블 나열
현재 데이터베이스의 모든 테이블을 나열하려면 \dt 명령을 사용할 수 있습니다.
\dt
출력 (생성한 테이블에 따라 다름):
List of relations
Schema | Name | Type | Owner
--------+------------------+-------+----------
public | boolean_example | table | postgres
public | customers | table | postgres
public | datetime_example | table | postgres
public | employees | table | postgres
public | integer_example | table | postgres
public | products | table | postgres
public | text_example | table | postgres
public | users | table | postgres
(8 rows)
마지막으로, psql 터미널을 종료합니다.
\q
이제 \d 및 \dt 명령을 사용하여 PostgreSQL 에서 테이블의 구조를 검사하는 방법을 배웠습니다. 이는 데이터베이스를 이해하고 작업하기 위한 기본적인 기술입니다.
요약
이 랩에서는 정수와 텍스트에 중점을 두고 기본적인 PostgreSQL 데이터 유형을 살펴보았습니다. 정수 값을 저장하기 위해 INTEGER 및 SMALLINT에 대해 배우고, 다양한 범위와 사용 사례를 이해했습니다. 또한 가변 길이 문자열과 고정 길이 문자열의 차이점을 파악하면서 텍스트 데이터를 처리하기 위해 TEXT, VARCHAR(n), CHAR(n)을 검토했습니다.
또한, 기본 키 시퀀스를 자동으로 생성하기 위해 SERIAL을 사용하는 것을 포함하여 이러한 데이터 유형을 사용하여 테이블을 생성하는 연습을 했습니다. 테이블에 샘플 데이터를 삽입하고 SELECT 문을 사용하여 데이터를 확인하여 실제 데이터베이스 컨텍스트에서 이러한 데이터 유형이 어떻게 작동하는지에 대한 이해를 굳혔습니다.

