
소개
이 랩에서는 PostgreSQL 에서 데이터 필터링 및 간단한 쿼리를 수행하는 방법을 배우게 됩니다. 먼저 PostgreSQL 데이터베이스에 연결하고 샘플 employees 테이블과 데이터를 생성하는 것으로 시작합니다.
그런 다음, 이 랩에서는 WHERE 절을 사용하여 특정 조건에 따라 데이터를 필터링하고, 패턴 매칭을 위해 LIKE를 사용하며, ORDER BY를 사용하여 결과를 정렬하고, LIMIT 및 OFFSET을 사용하여 반환되는 행의 수를 제한하는 방법을 안내합니다.
WHERE 절을 사용하여 데이터 필터링
이 단계에서는 PostgreSQL 에서 WHERE 절을 사용하여 특정 조건에 따라 데이터를 필터링하는 방법을 배우게 됩니다. WHERE 절은 여러분의 기준을 충족하는 행만 검색할 수 있게 해주는 강력한 도구입니다.
시작하기 전에 PostgreSQL 데이터베이스에 연결해 보겠습니다. LabEx VM 에서 터미널을 엽니다. 기본 Xfce 터미널을 사용할 수 있습니다.
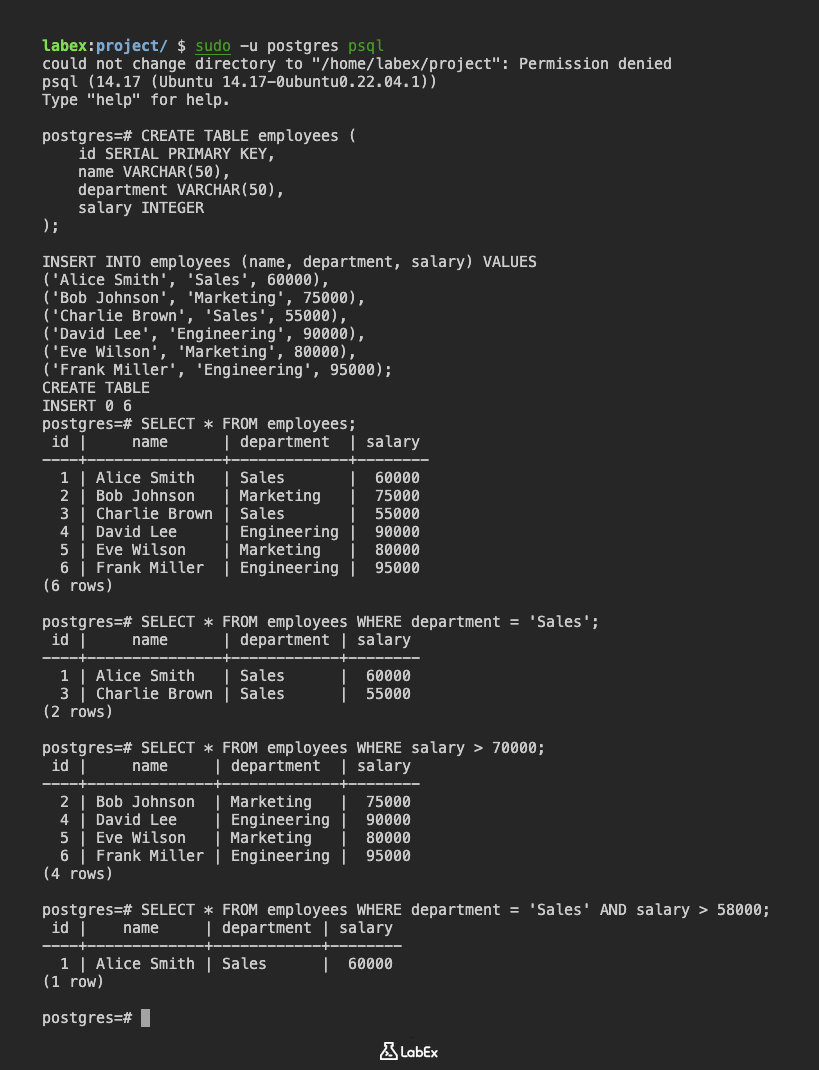
먼저, psql 명령을 사용하여 PostgreSQL 데이터베이스에 연결합니다. postgres 사용자로 postgres 데이터베이스에 연결합니다. 명령을 실행하려면 sudo를 사용해야 할 수도 있습니다.
sudo -u postgres psql
이제 PostgreSQL 프롬프트 (postgres=#) 가 표시됩니다.
이제 employees라는 샘플 테이블을 생성하고 데이터를 삽입해 보겠습니다. 이 테이블은 ID, 이름, 부서 및 급여를 포함한 직원 정보를 저장합니다.
CREATE TABLE employees (
id SERIAL PRIMARY KEY,
name VARCHAR(50),
department VARCHAR(50),
salary INTEGER
);
INSERT INTO employees (name, department, salary) VALUES
('Alice Smith', 'Sales', 60000),
('Bob Johnson', 'Marketing', 75000),
('Charlie Brown', 'Sales', 55000),
('David Lee', 'Engineering', 90000),
('Eve Wilson', 'Marketing', 80000),
('Frank Miller', 'Engineering', 95000);
테이블이 생성되고 올바르게 채워졌는지 확인하려면 다음 SQL 쿼리를 실행합니다.
SELECT * FROM employees;
다음과 유사한 출력이 표시됩니다.
id | name | department | salary
----+-----------------+-------------+--------
1 | Alice Smith | Sales | 60000
2 | Bob Johnson | Marketing | 75000
3 | Charlie Brown | Sales | 55000
4 | David Lee | Engineering | 90000
5 | Eve Wilson | Marketing | 80000
6 | Frank Miller | Engineering | 95000
(6 rows)
이제 WHERE 절을 사용하여 데이터를 필터링해 보겠습니다. 'Sales' 부서에서 근무하는 직원만 검색하려는 경우 다음 쿼리를 사용할 수 있습니다.
SELECT * FROM employees WHERE department = 'Sales';
이 쿼리는 department 열이 'Sales'와 같은 행만 반환합니다. 출력은 다음과 같아야 합니다.
id | name | department | salary
----+-----------------+------------+--------
1 | Alice Smith | Sales | 60000
3 | Charlie Brown | Sales | 55000
(2 rows)
WHERE 절에서는 >, <, >=, <=, <>와 같은 다른 비교 연산자도 사용할 수 있습니다. 예를 들어, 급여가 70000 보다 큰 직원을 검색하려면 다음 쿼리를 사용할 수 있습니다.
SELECT * FROM employees WHERE salary > 70000;
출력은 다음과 같아야 합니다.
id | name | department | salary
----+-----------------+-------------+--------
2 | Bob Johnson | Marketing | 75000
4 | David Lee | Engineering | 90000
5 | Eve Wilson | Marketing | 80000
6 | Frank Miller | Engineering | 95000
(4 rows)
AND 및 OR과 같은 논리 연산자를 사용하여 여러 조건을 결합할 수도 있습니다. 예를 들어, 'Sales' 부서에서 근무하고 급여가 58000 보다 큰 직원을 검색하려면 다음 쿼리를 사용할 수 있습니다.
SELECT * FROM employees WHERE department = 'Sales' AND salary > 58000;
출력은 다음과 같아야 합니다.
id | name | department | salary
----+---------------+------------+--------
1 | Alice Smith | Sales | 60000
(1 row)
마지막으로, psql 셸을 종료합니다.
\q
그러면 labex 사용자의 터미널로 돌아갑니다.
LIKE 를 사용하여 패턴 매칭
이 단계에서는 PostgreSQL 에서 패턴 매칭을 위해 LIKE 연산자를 사용하는 방법을 배우게 됩니다. LIKE 연산자를 사용하면 특정 패턴과 일치하는 데이터를 검색할 수 있으며, 이는 정확한 값을 모르는 경우에 특히 유용합니다.
먼저, PostgreSQL 데이터베이스에 연결해 보겠습니다. LabEx VM 에서 터미널을 엽니다.
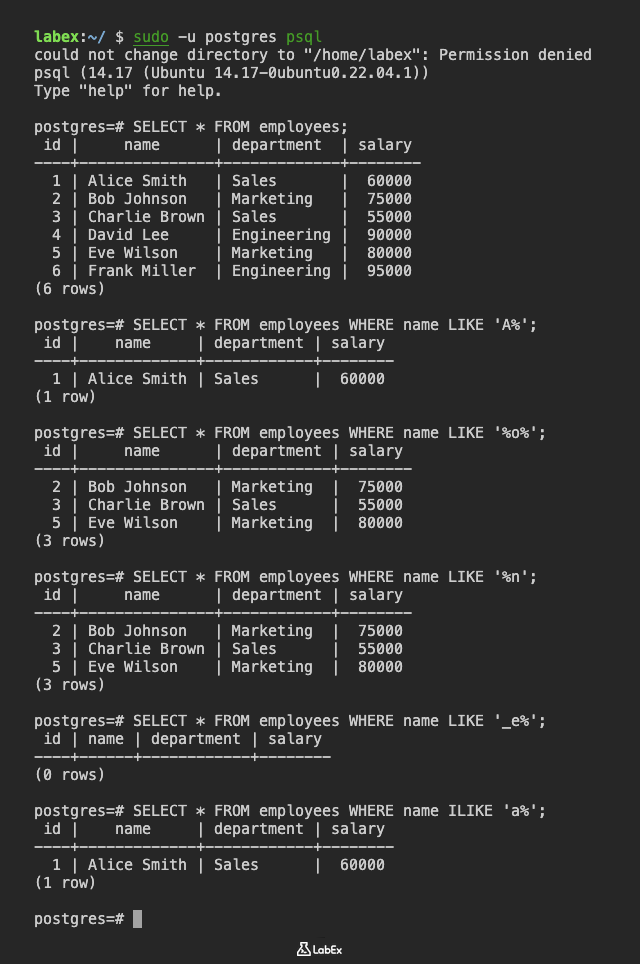
psql 명령을 사용하여 PostgreSQL 데이터베이스에 연결합니다.
sudo -u postgres psql
이제 PostgreSQL 프롬프트 (postgres=#) 가 표시됩니다.
이전 단계에서 생성된 employees 테이블을 계속 사용합니다. 아직 생성하지 않았다면, 이전 단계를 참조하여 테이블을 생성하고 데이터를 삽입하십시오.
employees 테이블의 데이터를 검토해 보겠습니다.
SELECT * FROM employees;
이전과 같이 직원 데이터가 표시됩니다.
LIKE 연산자는 지정된 패턴과 일치하는 행을 찾기 위해 WHERE 절에서 사용됩니다. 패턴에는 와일드카드 문자를 포함할 수 있습니다.
%: 0 개 이상의 문자를 나타냅니다._: 단일 문자를 나타냅니다.
예를 들어, 이름이 'A'로 시작하는 모든 직원을 찾으려면 다음 쿼리를 사용할 수 있습니다.
SELECT * FROM employees WHERE name LIKE 'A%';
이 쿼리는 name 열이 'A'로 시작하는 모든 행을 반환합니다. 출력은 다음과 같아야 합니다.
id | name | department | salary
----+---------------+------------+--------
1 | Alice Smith | Sales | 60000
(1 row)
이름에 문자 'o'가 포함된 모든 직원을 찾으려면 다음 쿼리를 사용할 수 있습니다.
SELECT * FROM employees WHERE name LIKE '%o%';
이 쿼리는 name 열에 문자 'o'가 포함된 모든 행을 반환합니다. 출력은 다음과 같아야 합니다.
id | name | department | salary
----+-----------------+-------------+--------
2 | Bob Johnson | Marketing | 75000
3 | Charlie Brown | Sales | 55000
5 | Eve Wilson | Marketing | 80000
(3 rows)
이름이 'n'으로 끝나는 모든 직원을 찾으려면 다음 쿼리를 사용할 수 있습니다.
SELECT * FROM employees WHERE name LIKE '%n';
이 쿼리는 name 열이 'n'으로 끝나는 모든 행을 반환합니다. 출력은 다음과 같아야 합니다.
id | name | department | salary
----+---------------+------------+--------
2 | Bob Johnson | Marketing | 75000
3 | Charlie Brown | Sales | 55000
5 | Eve Wilson | Marketing | 80000
(3 rows)
_ 와일드카드를 사용하여 단일 문자를 일치시킬 수도 있습니다. 예를 들어, 이름의 두 번째와 세 번째 문자가 'e '인 모든 직원을 찾으려면 다음 쿼리를 사용할 수 있습니다.
SELECT * FROM employees WHERE name LIKE '_e%';
이 쿼리는 name 열의 두 번째 문자가 'e'인 모든 행을 반환합니다. 출력은 다음과 같아야 합니다.
id | name | department | salary
----+------+------------+--------
(0 rows)
LIKE 연산자는 대소문자를 구분합니다. 대소문자를 구분하지 않는 검색을 수행하려면 ILIKE 연산자를 사용할 수 있습니다. 예를 들어:
SELECT * FROM employees WHERE name ILIKE 'a%';
이 쿼리는 name 열이 'a' 또는 'A'로 시작하는 모든 행을 반환합니다.
마지막으로, psql 셸을 종료합니다.
\q
그러면 labex 사용자의 터미널로 돌아갑니다.
ORDER BY 를 사용하여 데이터 정렬
이 단계에서는 PostgreSQL 에서 ORDER BY 절을 사용하여 데이터를 정렬하는 방법을 배우게 됩니다. ORDER BY 절을 사용하면 하나 이상의 열을 기준으로 쿼리 결과 집합을 오름차순 또는 내림차순으로 정렬할 수 있습니다.
먼저, PostgreSQL 데이터베이스에 연결해 보겠습니다. LabEx VM 에서 터미널을 엽니다.
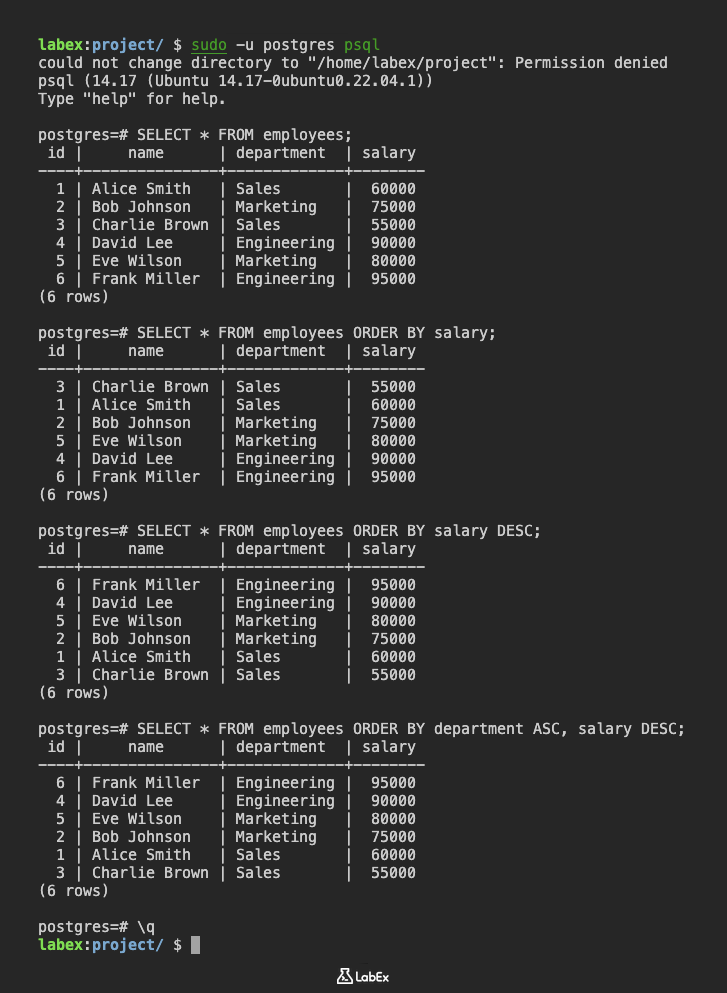
psql 명령을 사용하여 PostgreSQL 데이터베이스에 연결합니다.
sudo -u postgres psql
이제 PostgreSQL 프롬프트 (postgres=#) 가 표시됩니다.
이전 단계에서 생성된 employees 테이블을 계속 사용합니다. 아직 생성하지 않았다면, 이전 단계를 참조하여 테이블을 생성하고 데이터를 삽입하십시오.
employees 테이블의 데이터를 검토해 보겠습니다.
SELECT * FROM employees;
이전과 같이 직원 데이터가 표시됩니다.
ORDER BY 절은 쿼리 결과 집합을 정렬하는 데 사용됩니다. 기본적으로 ORDER BY 절은 데이터를 오름차순으로 정렬합니다.
예를 들어, 급여를 기준으로 직원을 오름차순으로 정렬하려면 다음 쿼리를 사용할 수 있습니다.
SELECT * FROM employees ORDER BY salary;
이 쿼리는 employees 테이블의 모든 행을 salary 열을 기준으로 오름차순으로 정렬하여 반환합니다. 출력은 다음과 같아야 합니다.
id | name | department | salary
----+-----------------+-------------+--------
3 | Charlie Brown | Sales | 55000
1 | Alice Smith | Sales | 60000
2 | Bob Johnson | Marketing | 75000
5 | Eve Wilson | Marketing | 80000
4 | David Lee | Engineering | 90000
6 | Frank Miller | Engineering | 95000
(6 rows)
데이터를 내림차순으로 정렬하려면 열 이름 뒤에 DESC 키워드를 사용할 수 있습니다. 예를 들어, 급여를 기준으로 직원을 내림차순으로 정렬하려면 다음 쿼리를 사용할 수 있습니다.
SELECT * FROM employees ORDER BY salary DESC;
이 쿼리는 employees 테이블의 모든 행을 salary 열을 기준으로 내림차순으로 정렬하여 반환합니다. 출력은 다음과 같아야 합니다.
id | name | department | salary
----+-----------------+-------------+--------
6 | Frank Miller | Engineering | 95000
4 | David Lee | Engineering | 90000
5 | Eve Wilson | Marketing | 80000
2 | Bob Johnson | Marketing | 75000
1 | Alice Smith | Sales | 60000
3 | Charlie Brown | Sales | 55000
(6 rows)
여러 열을 기준으로 데이터를 정렬할 수도 있습니다. 예를 들어, 부서를 오름차순으로 정렬한 다음 급여를 내림차순으로 정렬하려면 다음 쿼리를 사용할 수 있습니다.
SELECT * FROM employees ORDER BY department ASC, salary DESC;
이 쿼리는 먼저 department 열을 기준으로 오름차순으로 데이터를 정렬합니다. 각 부서 내에서 데이터는 salary 열을 기준으로 내림차순으로 정렬됩니다. 출력은 다음과 같아야 합니다.
id | name | department | salary
----+---------------+-------------+--------
6 | Frank Miller | Engineering | 95000
4 | David Lee | Engineering | 90000
5 | Eve Wilson | Marketing | 80000
2 | Bob Johnson | Marketing | 75000
1 | Alice Smith | Sales | 60000
3 | Charlie Brown | Sales | 55000
(6 rows)
마지막으로, psql 셸을 종료합니다.
\q
그러면 labex 사용자의 터미널로 돌아갑니다.
LIMIT 및 OFFSET 으로 결과 제한
이 단계에서는 PostgreSQL 에서 쿼리에서 반환되는 행 수를 제한하고 특정 수의 행을 건너뛰기 위해 각각 LIMIT 및 OFFSET 절을 사용하는 방법을 배우게 됩니다. 이러한 절은 페이지 매김을 구현하거나 특정 하위 집합의 데이터를 검색하는 데 유용합니다.
먼저, PostgreSQL 데이터베이스에 연결해 보겠습니다. LabEx VM 에서 터미널을 엽니다.
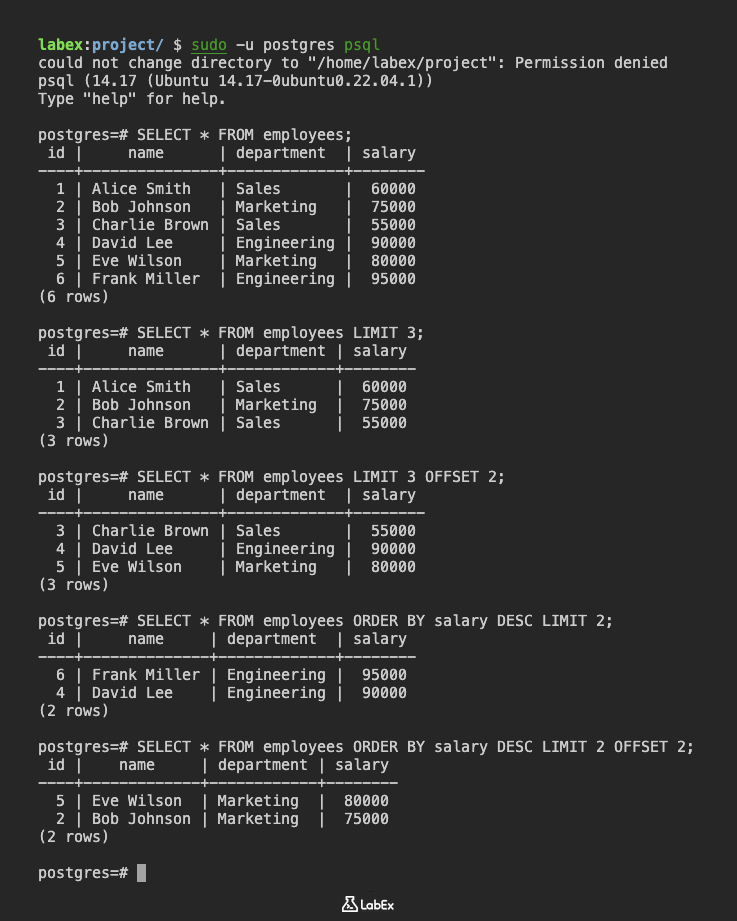
psql 명령을 사용하여 PostgreSQL 데이터베이스에 연결합니다.
sudo -u postgres psql
이제 PostgreSQL 프롬프트 (postgres=#) 가 표시됩니다.
이전 단계에서 생성된 employees 테이블을 계속 사용합니다. 아직 생성하지 않았다면, 이전 단계를 참조하여 테이블을 생성하고 데이터를 삽입하십시오.
employees 테이블의 데이터를 검토해 보겠습니다.
SELECT * FROM employees;
이전과 같이 직원 데이터가 표시됩니다.
LIMIT 절은 쿼리에서 반환되는 행 수를 제한하는 데 사용됩니다. 예를 들어, 처음 3 명의 직원만 검색하려면 다음 쿼리를 사용할 수 있습니다.
SELECT * FROM employees LIMIT 3;
이 쿼리는 employees 테이블에서 처음 3 개의 행을 반환합니다. 출력은 다음과 같아야 합니다.
id | name | department | salary
----+-----------------+-------------+--------
1 | Alice Smith | Sales | 60000
2 | Bob Johnson | Marketing | 75000
3 | Charlie Brown | Sales | 55000
(3 rows)
OFFSET 절은 행을 반환하기 전에 특정 수의 행을 건너뛰는 데 사용됩니다. 페이지 매김을 구현하기 위해 LIMIT 절과 함께 자주 사용됩니다. 예를 들어, 처음 2 명을 건너뛴 후 다음 3 명의 직원을 검색하려면 다음 쿼리를 사용할 수 있습니다.
SELECT * FROM employees LIMIT 3 OFFSET 2;
이 쿼리는 처음 2 개의 행을 건너뛴 다음 employees 테이블에서 다음 3 개의 행을 반환합니다. 출력은 다음과 같아야 합니다.
id | name | department | salary
----+-----------------+-------------+--------
3 | Charlie Brown | Sales | 55000
4 | David Lee | Engineering | 90000
5 | Eve Wilson | Marketing | 80000
(3 rows)
LIMIT 및 OFFSET을 ORDER BY 절과 결합할 수도 있습니다. 예를 들어, 급여가 가장 높은 2 명의 직원을 검색하려면 다음 쿼리를 사용할 수 있습니다.
SELECT * FROM employees ORDER BY salary DESC LIMIT 2;
이 쿼리는 먼저 급여를 기준으로 직원을 내림차순으로 정렬한 다음 처음 2 개의 행을 반환합니다. 출력은 다음과 같아야 합니다.
id | name | department | salary
----+-----------------+-------------+--------
6 | Frank Miller | Engineering | 95000
4 | David Lee | Engineering | 90000
(2 rows)
급여가 3 번째 및 4 번째로 높은 직원을 검색하려면 다음 쿼리를 사용할 수 있습니다.
SELECT * FROM employees ORDER BY salary DESC LIMIT 2 OFFSET 2;
이 쿼리는 먼저 급여를 기준으로 직원을 내림차순으로 정렬하고, 처음 2 개의 행을 건너뛴 다음 다음 2 개의 행을 반환합니다. 출력은 다음과 같아야 합니다.
id | name | department | salary
----+-----------------+-------------+--------
5 | Eve Wilson | Marketing | 80000
2 | Bob Johnson | Marketing | 75000
(2 rows)
마지막으로, psql 셸을 종료합니다.
\q
그러면 labex 사용자의 터미널로 돌아갑니다.
요약
이 랩에서는 psql 명령을 사용하여 PostgreSQL 데이터베이스에 연결하고 ID, 이름, 부서 및 급여 열이 있는 샘플 employees 테이블을 생성하는 것으로 시작했습니다. 그런 다음 직원 데이터를 테이블에 채우고 SELECT 쿼리를 사용하여 내용을 확인했습니다.
초점은 특정 조건을 기반으로 데이터를 필터링하기 위해 WHERE 절을 사용하는 것이었습니다. 이를 통해 정의된 기준을 충족하는 행만 검색할 수 있으며, employees 테이블에서 대상 데이터를 검색할 수 있습니다.

