
소개
이 실습에서는 MySQL 인덱스와 성능 최적화 기법에 대해 배우게 됩니다. 이 실습은 데이터베이스 쿼리 성능 향상을 위해 인덱스를 생성하고 관리하는 데 중점을 둡니다.
먼저 users 테이블을 생성하고 샘플 데이터를 삽입합니다. 그런 다음 username 열에 단일 열 인덱스를 생성하고 생성 확인 방법을 배웁니다. 또한 EXPLAIN을 사용하여 쿼리 계획을 분석하고, 다중 열 쿼리를 위한 복합 인덱스를 추가하고, 사용되지 않는 인덱스를 제거하여 데이터베이스 효율성을 유지하는 방법을 다룹니다.
테이블에 단일 열 인덱스 생성
이 단계에서는 MySQL 에서 단일 열 인덱스를 생성하는 방법을 배우게 됩니다. 인덱스는 데이터베이스 쿼리 성능을 향상시키는 데 매우 중요하며, 특히 대규모 테이블을 다룰 때 더욱 그렇습니다. 열에 대한 인덱스는 데이터베이스가 전체 테이블을 스캔하지 않고도 해당 열의 특정 값과 일치하는 행을 빠르게 찾을 수 있도록 합니다.
인덱스 이해하기
인덱스를 책의 색인과 같다고 생각하면 됩니다. 특정 주제를 찾기 위해 책 전체를 읽는 대신, 색인을 사용하여 관련 페이지를 빠르게 찾을 수 있습니다. 마찬가지로 데이터베이스 인덱스는 데이터베이스 엔진이 특정 행을 빠르게 찾는 데 도움이 됩니다.
테이블 생성
먼저 인덱스 생성을 시연하기 위해 users라는 간단한 테이블을 생성해 보겠습니다. LabEx VM 에서 터미널을 엽니다. 바탕 화면의 Xfce Terminal 바로 가기를 사용할 수 있습니다.
루트 사용자로 MySQL 서버에 연결합니다.
sudo mysql -u root
먼저 이 실습을 위한 데이터베이스를 생성하고 선택합니다.
CREATE DATABASE lab_db;
USE lab_db;
이제 users 테이블을 생성합니다.
CREATE TABLE users (
id INT AUTO_INCREMENT PRIMARY KEY,
username VARCHAR(255) NOT NULL,
email VARCHAR(255) NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
이 SQL 문은 id, username, email, created_at 열을 가진 users라는 테이블을 생성합니다. id 열은 기본 키로 설정되고 자동 증가합니다.
users 테이블에 샘플 데이터를 삽입해 보겠습니다.
INSERT INTO users (username, email) VALUES
('john_doe', 'john.doe@example.com'),
('jane_smith', 'jane.smith@example.com'),
('peter_jones', 'peter.jones@example.com');
단일 열 인덱스 생성
이제 username 열에 인덱스를 생성해 보겠습니다. 이렇게 하면 사용자 이름으로 사용자를 검색하는 쿼리가 더 빨라집니다.
CREATE INDEX idx_username ON users (username);
이 문은 users 테이블의 username 열에 idx_username이라는 인덱스를 생성합니다.
인덱스 확인
SHOW INDEXES 명령을 사용하여 인덱스가 생성되었는지 확인할 수 있습니다.
SHOW INDEXES FROM users;
출력에는 방금 생성한 idx_username 인덱스를 포함하여 users 테이블의 인덱스에 대한 세부 정보가 표시됩니다. Key_name이 idx_username이고 Column_name이 username인 행을 볼 수 있어야 합니다.
+-------+------------+--------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Ignored |
+-------+------------+--------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+
| users | 0 | PRIMARY | 1 | id | A | 3 | NULL | NULL | | BTREE | | | NO |
| users | 1 | idx_username | 1 | username | A | 3 | NULL | NULL | | BTREE | | | NO |
+-------+------------+--------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+
이제 테이블에 단일 열 인덱스를 성공적으로 생성했습니다. 이렇게 하면 인덱싱된 열을 기준으로 데이터를 필터링하는 쿼리의 성능이 향상됩니다.
EXPLAIN 을 사용하여 쿼리 계획 분석
이 단계에서는 MySQL 의 EXPLAIN 문을 사용하여 쿼리 실행 계획을 분석하는 방법을 배우게 됩니다. 쿼리 계획을 이해하는 것은 성능 병목 현상을 식별하고 쿼리를 최적화하는 데 필수적입니다.
쿼리 계획이란 무엇인가요?
쿼리 계획은 데이터베이스 엔진이 쿼리를 실행하는 데 사용하는 로드맵입니다. 테이블에 액세스하는 순서, 사용되는 인덱스, 데이터를 검색하는 데 적용되는 알고리즘을 설명합니다. 쿼리 계획을 분석함으로써 데이터베이스가 쿼리를 어떻게 실행하는지 이해하고 개선할 부분을 식별할 수 있습니다.
EXPLAIN 문 사용하기
EXPLAIN 문은 MySQL 이 쿼리를 실행하는 방법에 대한 정보를 제공합니다. 관련된 테이블, 사용된 인덱스, 조인 순서 및 쿼리 성능을 이해하는 데 도움이 되는 기타 세부 정보를 보여줍니다.
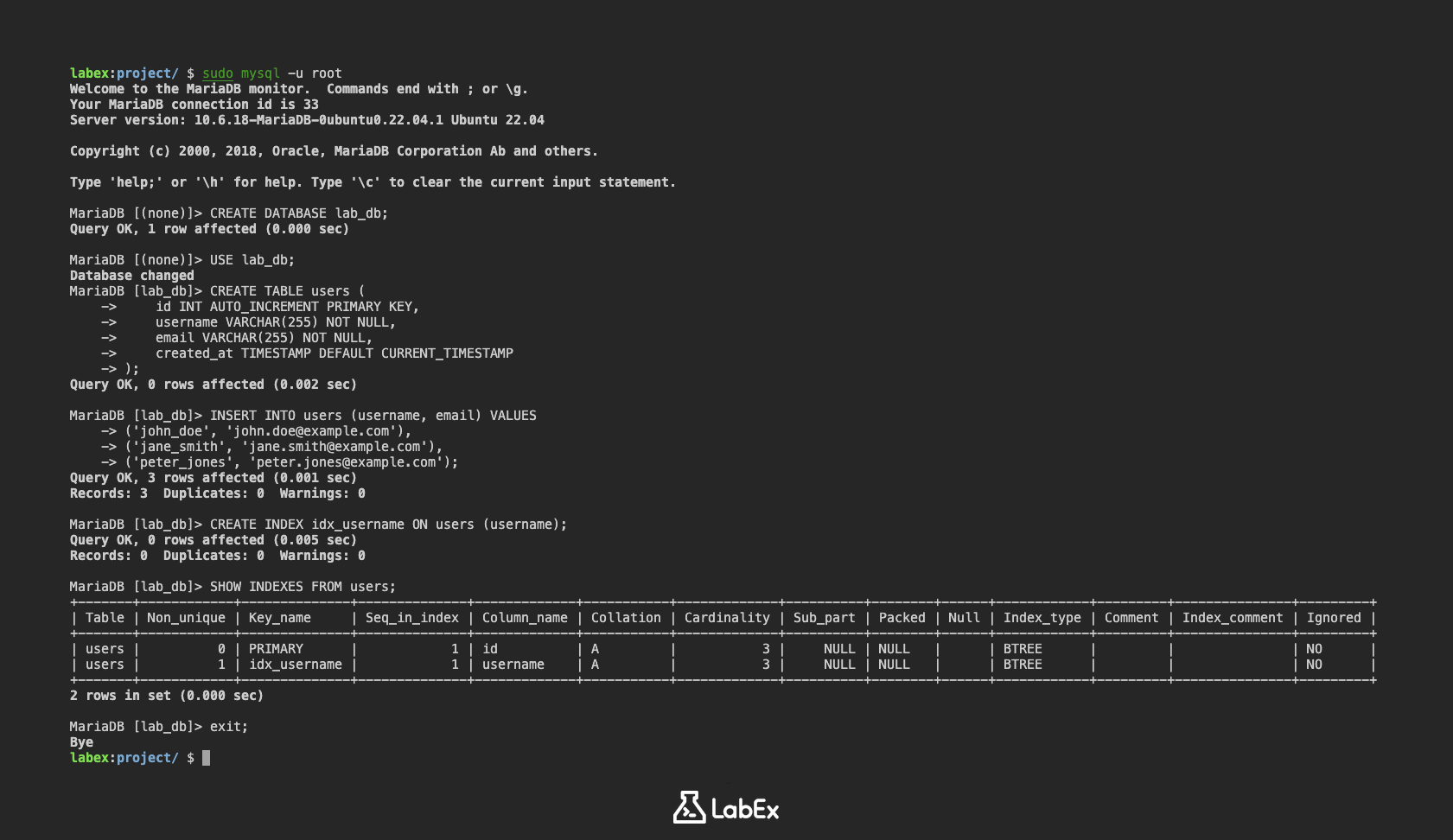
이제 EXPLAIN을 사용하여 간단한 쿼리를 분석해 보겠습니다.
EXPLAIN SELECT * FROM users WHERE username = 'john_doe';
EXPLAIN 문의 출력은 여러 열로 구성된 테이블입니다. 다음은 가장 중요한 열에 대한 설명입니다.
id: SELECT 문의 ID 입니다.select_type: SELECT 쿼리의 유형입니다 (예:SIMPLE,PRIMARY,SUBQUERY).table: 액세스되는 테이블입니다.type: 조인 유형입니다. 이것은 가장 중요한 열 중 하나입니다. 일반적인 값은 다음과 같습니다.system: 테이블에 행이 하나만 있습니다.const: 테이블에 일치하는 행이 최대 하나 있으며, 쿼리 시작 시 읽힙니다.eq_ref: 이전 테이블의 행 조합에 대해 이 테이블에서 한 행이 읽힙니다. 이는 인덱싱된 열에 조인할 때 사용됩니다.ref: 이전 테이블의 행 조합에 대해 이 테이블에서 일치하는 모든 행이 읽힙니다. 이는 인덱싱된 열에 조인할 때 사용됩니다.range: 인덱스를 사용하여 지정된 범위 내의 행만 검색합니다.index: 전체 인덱스 스캔이 수행됩니다.ALL: 전체 테이블 스캔이 수행됩니다. 이것은 가장 비효율적인 유형입니다.
possible_keys: MySQL 이 테이블에서 행을 찾기 위해 사용할 수 있는 인덱스입니다.key: MySQL 이 실제로 사용한 인덱스입니다.key_len: MySQL 이 사용한 키의 길이입니다.ref: 인덱스와 비교되는 열 또는 상수입니다.rows: MySQL 이 쿼리를 실행하기 위해 검사해야 할 것으로 추정하는 행의 수입니다.Extra: MySQL 이 쿼리를 실행하는 방법에 대한 추가 정보입니다. 일반적인 값은 다음과 같습니다.Using index: 쿼리는 인덱스만 사용하여 만족될 수 있습니다.Using where: MySQL 은 테이블에 액세스한 후 행을 필터링해야 합니다.Using temporary: MySQL 은 쿼리를 실행하기 위해 임시 테이블을 생성해야 합니다.Using filesort: MySQL 은 테이블에 액세스한 후 행을 정렬해야 합니다.
EXPLAIN 출력 해석하기
SELECT * FROM users WHERE username = 'john_doe' 쿼리의 경우 EXPLAIN 출력은 다음과 유사해야 합니다.
+------+-------------+-------+------+---------------+--------------+---------+-------+------+-----------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+-------+------+---------------+--------------+---------+-------+------+-----------------------+
| 1 | SIMPLE | users | ref | idx_username | idx_username | 767 | const | 1 | Using index condition |
+------+-------------+-------+------+---------------+--------------+---------+-------+------+-----------------------+
이 예시에서:
type은ref이며, 이는 MySQL 이 인덱스를 사용하여 일치하는 행을 찾고 있음을 의미합니다.possible_keys와key모두idx_username을 표시하며, 이는 이전 단계에서 생성한idx_username인덱스를 사용하고 있음을 의미합니다.rows는1이며, 이는 MySQL 이 쿼리를 실행하기 위해 단 하나의 행만 검사하면 될 것으로 추정함을 의미합니다.
인덱스가 없는 쿼리 분석하기
이제 인덱스를 사용하지 않는 쿼리를 분석해 보겠습니다. 먼저 users 테이블에 city라는 새 열을 추가해 보겠습니다.
ALTER TABLE users ADD COLUMN city VARCHAR(255);
이제 city로 검색하는 쿼리에 대해 EXPLAIN을 실행해 보겠습니다. 아직 city 열에 데이터를 추가하지 않았으므로 행 중 하나를 업데이트해 보겠습니다.
UPDATE users SET city = 'New York' WHERE username = 'john_doe';
이제 EXPLAIN 문을 다시 실행합니다.
EXPLAIN SELECT * FROM users WHERE city = 'New York';
출력은 다음과 같을 수 있습니다.
+------+-------------+-------+------+---------------+------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+-------+------+---------------+------+---------+------+------+-------------+
| 1 | SIMPLE | users | ALL | NULL | NULL | NULL | NULL | 3 | Using where |
+------+-------------+-------+------+---------------+------+---------+------+------+-------------+
이 예시에서:
type은ALL이며, 이는 MySQL 이 전체 테이블 스캔을 수행하고 있음을 의미합니다.possible_keys와key는 모두NULL이며, 이는 MySQL 이 어떤 인덱스도 사용하고 있지 않음을 의미합니다.rows는3이며, 이는 MySQL 이 쿼리를 실행하기 위해 테이블의 모든 3 개 행을 검사해야 할 것으로 추정함을 의미합니다.Extra는Using where를 표시하며, 이는 MySQL 이 테이블에 액세스한 후 행을 필터링해야 함을 의미합니다.
이는 쿼리가 최적화되지 않았으며 city 열에 대한 인덱스의 이점을 얻을 수 있음을 나타냅니다.
다중 열 쿼리를 위한 복합 인덱스 추가
이 단계에서는 MySQL 에서 복합 인덱스를 생성하는 방법을 배우게 됩니다. 복합 인덱스는 테이블의 두 개 이상의 열에 대한 인덱스입니다. 여러 열을 기준으로 데이터를 필터링하는 쿼리의 성능을 크게 향상시킬 수 있습니다.
복합 인덱스란 무엇인가요?
복합 인덱스는 여러 열을 포함하는 인덱스입니다. 쿼리에서 WHERE 절에 여러 열을 자주 사용하는 경우 유용합니다. 복합 인덱스에서 열의 순서는 중요합니다. 쿼리의 WHERE 절에 열이 동일한 순서로 지정될 때 인덱스가 가장 효과적입니다.
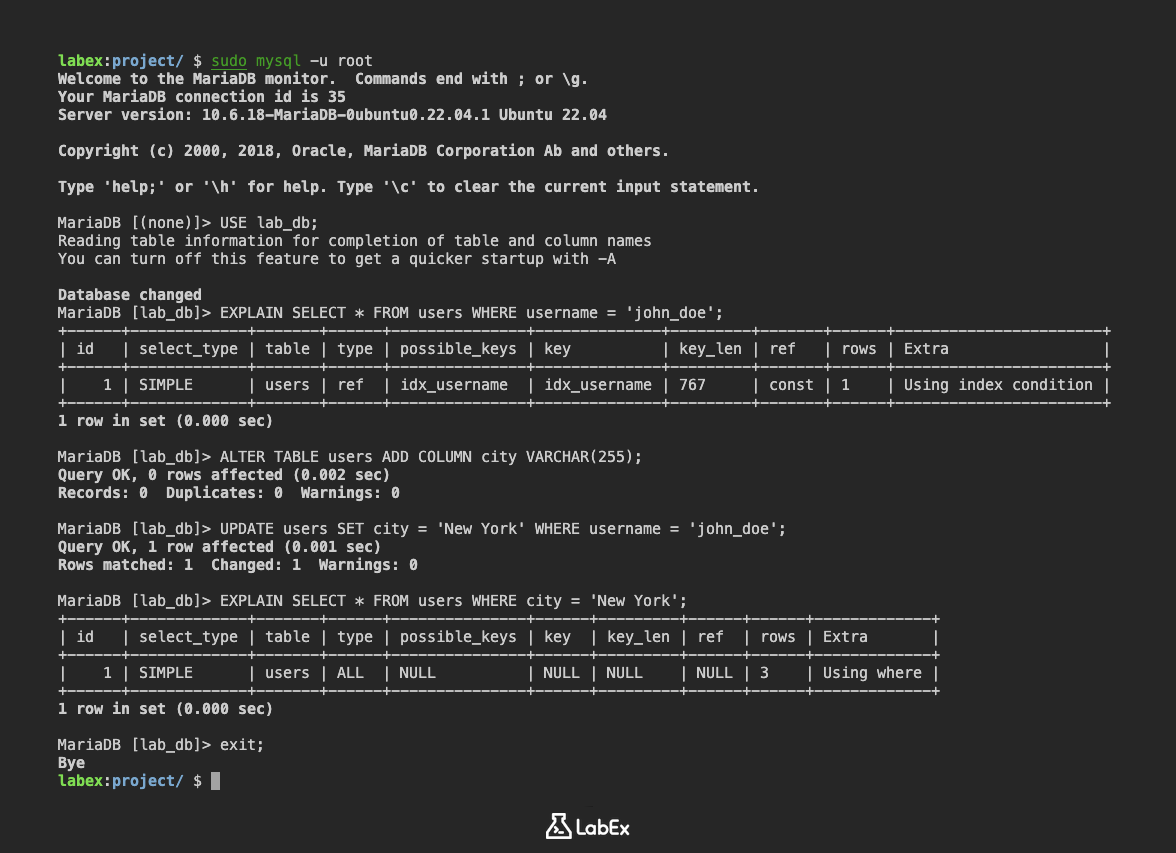
다른 도시를 포함하여 users 테이블에 더 많은 데이터를 추가해 보겠습니다.
INSERT INTO users (username, email, city) VALUES
('alice_brown', 'alice.brown@example.com', 'Los Angeles'),
('bob_davis', 'bob.davis@example.com', 'Chicago'),
('charlie_wilson', 'charlie.wilson@example.com', 'New York'),
('david_garcia', 'david.garcia@example.com', 'Los Angeles');
복합 인덱스 생성
city와 username 모두로 사용자를 필터링하는 쿼리를 자주 실행한다고 가정해 보겠습니다. 이 경우 city 및 username 열에 복합 인덱스를 생성할 수 있습니다.
CREATE INDEX idx_city_username ON users (city, username);
이 문은 users 테이블의 city 및 username 열에 idx_city_username이라는 인덱스를 생성합니다.
인덱스 확인
SHOW INDEXES 명령을 사용하여 인덱스가 생성되었는지 확인할 수 있습니다.
SHOW INDEXES FROM users;
출력에는 방금 생성한 idx_city_username 인덱스를 포함하여 users 테이블의 인덱스에 대한 세부 정보가 표시됩니다. idx_city_username에 대해 city 열과 username 열 각각에 대한 두 개의 행이 표시되어야 합니다.
+-------+------------+-------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Ignored |
+-------+------------+-------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+
| users | 0 | PRIMARY | 1 | id | A | 7 | NULL | NULL | | BTREE | | | NO |
| users | 1 | idx_username | 1 | username | A | 7 | NULL | NULL | | BTREE | | | NO |
| users | 1 | idx_city_username | 1 | city | A | 7 | NULL | NULL | YES | BTREE | | | NO |
| users | 1 | idx_city_username | 2 | username | A | 7 | NULL | NULL | | BTREE | | | NO |
+-------+------------+-------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+
복합 인덱스 사용하기
복합 인덱스의 이점을 확인하려면 EXPLAIN 명령을 사용하여 WHERE 절에 city와 username 열을 모두 사용하는 쿼리를 분석할 수 있습니다.
EXPLAIN SELECT * FROM users WHERE city = 'New York' AND username = 'charlie_wilson';
EXPLAIN 출력은 쿼리가 idx_city_username 인덱스를 사용하고 있음을 보여줍니다. 이는 데이터베이스가 전체 테이블을 스캔하지 않고 일치하는 행을 빠르게 찾을 수 있음을 의미합니다. 출력에서 possible_keys 및 key 열을 확인하십시오. 인덱스가 사용되고 있다면 이 열에서 idx_city_username을 볼 수 있습니다.
+------+-------------+-------+------+--------------------------------+--------------+---------+-------+------+------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+-------+------+--------------------------------+--------------+---------+-------+------+------------------------------------+
| 1 | SIMPLE | users | ref | idx_username,idx_city_username | idx_username | 767 | const | 1 | Using index condition; Using where |
+------+-------------+-------+------+--------------------------------+--------------+---------+-------+------+------------------------------------+
인덱스에서 열의 순서
복합 인덱스에서 열의 순서는 중요합니다. (city, username) 대신 (username, city)에 인덱스를 생성하면 city로 필터링한 다음 username으로 필터링하는 쿼리에 대해 인덱스가 덜 효과적입니다.
예를 들어, (username, city)에 인덱스가 있고 다음 쿼리를 실행한다고 가정해 보겠습니다.
EXPLAIN SELECT * FROM users WHERE city = 'New York' AND username = 'charlie_wilson';
MySQL 은 인덱스를 사용하지 않거나 부분적으로만 사용할 수 있습니다. 왜냐하면 city 열이 인덱스의 선행 열이 아니기 때문입니다.
사용하지 않는 인덱스 제거
이 단계에서는 MySQL 에서 사용되지 않는 인덱스를 제거하는 방법을 배우게 됩니다. 인덱스는 쿼리 성능을 크게 향상시킬 수 있지만, 쓰기 작업 (삽입, 업데이트, 삭제) 에 오버헤드를 추가하기도 합니다. 따라서 더 이상 사용되지 않는 인덱스를 식별하고 제거하는 것이 중요합니다.
사용되지 않는 인덱스를 제거하는 이유는 무엇인가요?
사용되지 않는 인덱스는 디스크 공간을 차지하고 쓰기 작업을 느리게 할 수 있습니다. 테이블의 데이터가 수정될 때마다 데이터베이스 엔진은 해당 테이블의 모든 인덱스도 업데이트해야 합니다. 인덱스가 어떤 쿼리에서도 사용되지 않는다면 불필요한 오버헤드만 추가하는 것입니다.
이전 단계에서 username 열에 idx_username이라는 인덱스를 생성했습니다. 쿼리 패턴을 분석한 후 이 인덱스가 더 이상 사용되지 않는다고 판단한다고 가정해 보겠습니다.
인덱스 제거
idx_username 인덱스를 제거하려면 DROP INDEX 문을 사용할 수 있습니다.
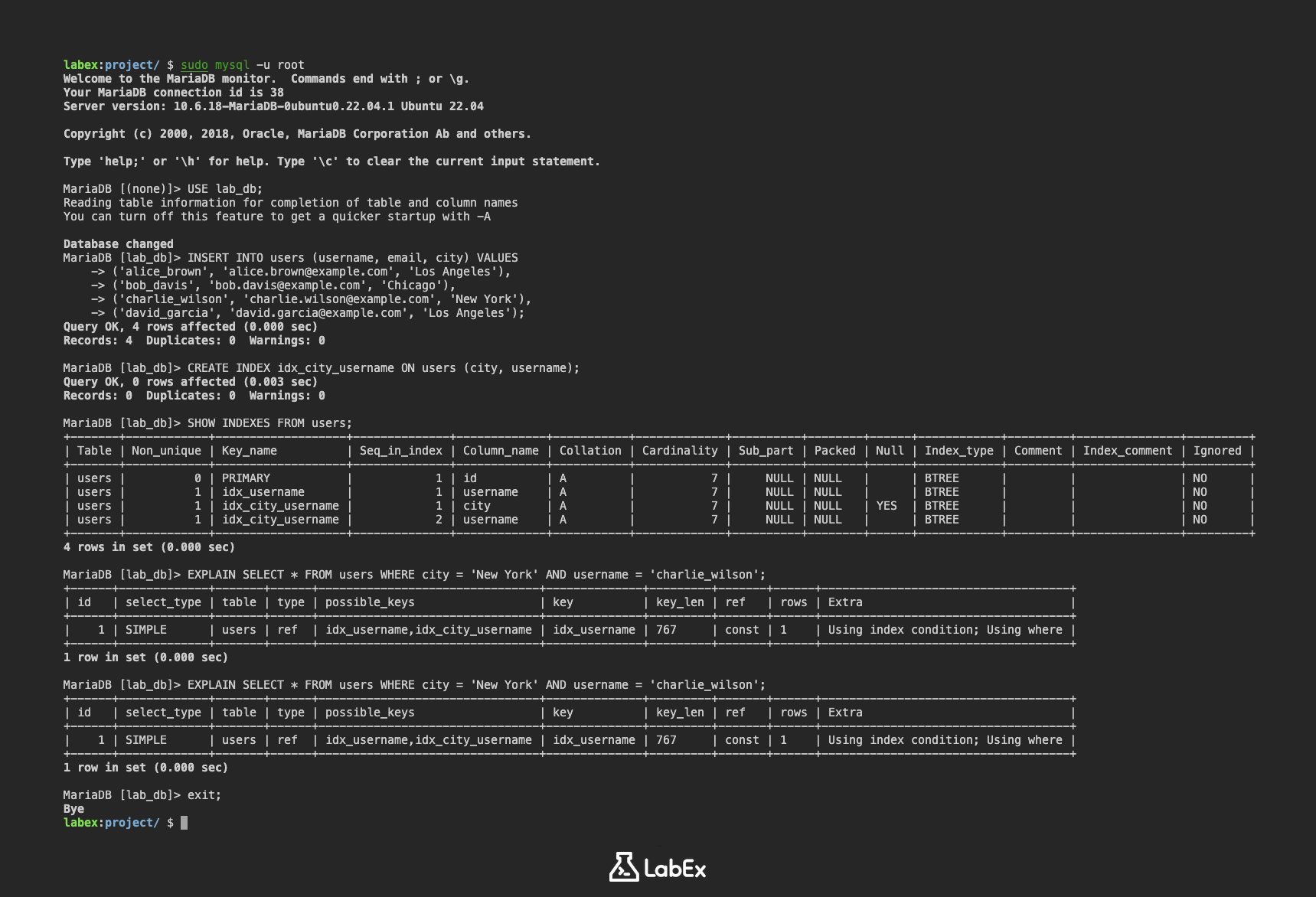
DROP INDEX idx_username ON users;
이 문은 users 테이블에서 idx_username 인덱스를 제거합니다.
인덱스 제거 확인
SHOW INDEXES 명령을 사용하여 인덱스가 제거되었는지 확인할 수 있습니다.
SHOW INDEXES FROM users;
출력에는 users 테이블의 인덱스에 대한 세부 정보가 표시됩니다. 출력에서 idx_username 인덱스가 더 이상 표시되지 않아야 합니다.
+-------+------------+-------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Ignored |
+-------+------------+-------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+
| users | 0 | PRIMARY | 1 | id | A | 7 | NULL | NULL | | BTREE | | | NO |
| users | 1 | idx_city_username | 1 | city | A | 7 | NULL | NULL | YES | BTREE | | | NO |
| users | 1 | idx_city_username | 2 | username | A | 7 | NULL | NULL | | BTREE | | | NO |
+-------+------------+-------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+
사용되지 않는 인덱스 식별
실제 시나리오에서는 사용되지 않는 인덱스를 식별하는 것이 어려울 수 있습니다. MySQL 은 이 작업을 돕기 위해 여러 도구와 기술을 제공합니다.
- MySQL Enterprise Audit: 이 기능을 사용하면 서버에서 실행된 모든 쿼리를 기록할 수 있습니다. 그런 다음 쿼리 로그를 분석하여 어떤 인덱스가 사용되고 있는지 식별할 수 있습니다.
- Performance Schema: Performance Schema 는 인덱스 사용을 포함하여 서버 성능에 대한 자세한 정보를 제공합니다.
- 타사 도구: 여러 타사 도구를 사용하여 인덱스 사용을 모니터링하고 사용되지 않는 인덱스를 식별할 수 있습니다.
정기적으로 인덱스 사용을 모니터링하고 사용되지 않는 인덱스를 제거함으로써 데이터베이스의 전반적인 성능을 향상시킬 수 있습니다.
이제 모든 단계를 완료했으므로 MySQL 콘솔을 종료합니다.
exit;
요약
이 실습에서는 쿼리 성능을 향상시키기 위해 MySQL 에서 단일 열 인덱스를 생성하는 방법을 배웠습니다. 또한 EXPLAIN 문을 사용하여 쿼리 실행 계획을 분석하고 성능 병목 현상을 식별하는 방법을 배웠습니다. 또한 다중 열 쿼리를 위한 복합 인덱스를 생성하고 데이터베이스 효율성을 유지하기 위해 사용되지 않는 인덱스를 제거하는 연습을 했습니다. 인덱스를 효과적으로 이해하고 활용하는 것은 데이터베이스 성능 최적화를 위한 기본적인 기술입니다.


