
소개
이 랩에서는 Python 에서 가장 인기 있는 데이터 시각화 라이브러리 중 하나인 Matplotlib 을 사용하여 히스토그램을 생성하고 사용자 정의하는 방법을 배웁니다. 히스토그램은 수치형 데이터셋의 분포를 시각화하는 강력한 도구입니다. 숫자를 범위 ("빈" 또는 "구간") 로 그룹화하고 각 빈에 속하는 데이터 포인트의 빈도를 표시합니다.
다음 단계를 진행합니다:
- NumPy 를 사용하여 샘플 데이터를 생성합니다.
- 기본 히스토그램을 생성합니다.
- 빈의 개수를 사용자 정의합니다.
- 히스토그램 막대의 색상 및 테두리 스타일을 변경합니다.
- 확률 밀도를 표시하도록 히스토그램을 정규화합니다.
이 랩이 끝나면 데이터 분석 프로젝트를 위한 유익하고 시각적으로 매력적인 히스토그램을 생성할 수 있게 됩니다. 모든 플롯은 이미지 파일로 저장되며, LabEx WebIDE 에서 직접 확인할 수 있습니다.
numpy.random 을 사용하여 샘플 데이터 생성
이 단계에서는 히스토그램을 플로팅하는 데 사용할 샘플 데이터 세트를 생성합니다. Python 의 과학 컴퓨팅을 위한 기본 패키지인 NumPy 라이브러리를 사용할 것입니다. NumPy 는 고성능 다차원 배열 객체와 이러한 배열 작업을 위한 도구를 제공합니다.
정규 분포 (또는 가우시안 분포) 를 따르는 데이터를 생성하기 위해 numpy.random.normal() 함수를 사용할 것입니다. 이는 많은 실제 시나리오에서 발견되는 일반적인 데이터 분포 유형입니다.
먼저 WebIDE 왼쪽의 파일 탐색기에서 main.py 파일을 엽니다. 그런 다음 다음 코드를 추가합니다. 이 코드는 numpy 라이브러리를 가져오고 평균이 0 이고 표준 편차가 1 인 1000 개의 난수를 생성합니다.
import numpy as np
## 평균 (loc) 0, 표준 편차 (scale) 1 인 정규 분포에서 1000 개의 데이터 포인트 생성
data = np.random.normal(loc=0, scale=1, size=1000)
print("Sample data generated successfully.")
스크립트를 실행하려면 WebIDE 에서 터미널을 열고 (Terminal -> New Terminal) 다음 명령을 실행합니다. 작업 디렉토리는 이미 /home/labex/project입니다.
python3 main.py
터미널에서 확인 메시지가 표시됩니다.
Sample data generated successfully.
스크립트의 data 변수에는 이제 1000 개의 숫자로 구성된 배열이 포함되어 있으며, 다음 단계에서 시각화할 준비가 되었습니다.
plt.hist(data) 를 사용하여 히스토그램 플로팅
이 단계에서는 첫 번째 히스토그램을 생성합니다. 플로팅을 위한 간단한 인터페이스를 제공하는 matplotlib.pyplot 모듈을 사용할 것입니다. 이 모듈은 관례적으로 plt라는 별칭으로 가져옵니다.
히스토그램 생성의 핵심 함수는 plt.hist()입니다. 가장 간단한 형태로, 플로팅하려는 데이터 배열이라는 단일 인수를 받습니다.
비대화형 환경에 있으므로 plt.show()로 플롯을 직접 표시할 수 없습니다. 대신 plt.savefig()를 사용하여 플롯을 파일로 저장해야 합니다.
이전 단계의 데이터 생성 코드에 Matplotlib 플로팅 로직을 추가하여 main.py 파일을 업데이트합니다.
import numpy as np
import matplotlib.pyplot as plt
## 샘플 데이터 생성
data = np.random.normal(loc=0, scale=1, size=1000)
## 히스토그램 생성
plt.hist(data)
## 플롯을 파일로 저장
plt.savefig('/home/labex/project/histogram.png')
print("Basic histogram saved to histogram.png")
이제 터미널에서 스크립트를 다시 실행합니다.
python3 main.py
다음과 같은 출력이 표시됩니다.
Basic histogram saved to histogram.png
왼쪽 파일 탐색기에 histogram.png라는 새 파일이 나타납니다. 이 파일을 두 번 클릭하여 첫 번째 히스토그램을 열어봅니다. 생성한 난수의 빈도 분포를 보여줍니다.
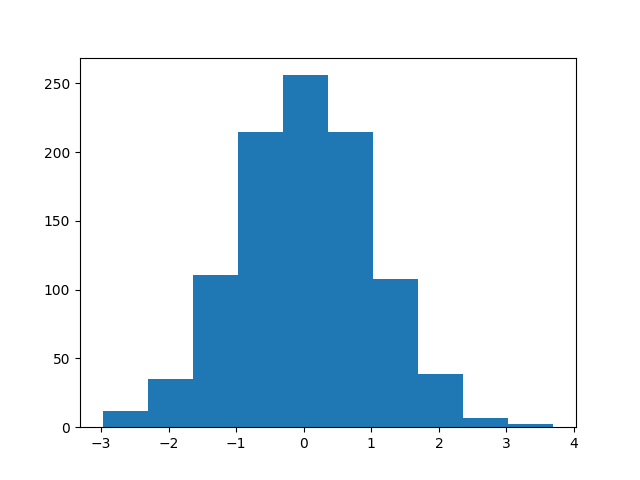
bins 매개변수를 사용하여 bin 개수 설정
이 단계에서는 빈 (bin) 개수를 설정하여 히스토그램의 세분화 수준을 제어하는 방법을 배웁니다. "빈 (bin)"은 데이터 범위를 나타내는 구간입니다. 빈의 개수는 분포 해석 방식에 상당한 영향을 미칠 수 있습니다. 빈이 너무 적으면 중요한 세부 정보가 숨겨질 수 있고, 너무 많으면 노이즈가 많은 플롯이 생성될 수 있습니다.
Matplotlib 의 plt.hist() 함수에는 빈 개수를 지정할 수 있는 bins 매개변수가 있습니다. 기본적으로 Matplotlib 은 합리적인 개수를 선택하지만, 종종 이를 조정해야 할 필요가 있습니다.
이전 플롯과 비교하기 위해 코드를 수정하여 30 개의 빈을 가진 히스토그램을 생성해 보겠습니다. 또한 새 파일인 histogram_bins.png에 저장하겠습니다.
main.py 파일을 다음과 같이 업데이트합니다.
import numpy as np
import matplotlib.pyplot as plt
## 샘플 데이터 생성
data = np.random.normal(loc=0, scale=1, size=1000)
## 30 개의 빈으로 히스토그램 생성
plt.hist(data, bins=30)
## 새 파일에 플롯 저장
plt.savefig('/home/labex/project/histogram_bins.png')
print("Histogram with 30 bins saved to histogram_bins.png")
터미널에서 스크립트를 실행합니다.
python3 main.py
출력은 다음과 같습니다.
Histogram with 30 bins saved to histogram_bins.png
이제 파일 탐색기에서 histogram_bins.png를 찾아 엽니다. 첫 번째 히스토그램과 비교해 보세요. 막대가 더 좁아져 데이터 분포를 더 자세히 볼 수 있다는 것을 알 수 있습니다.
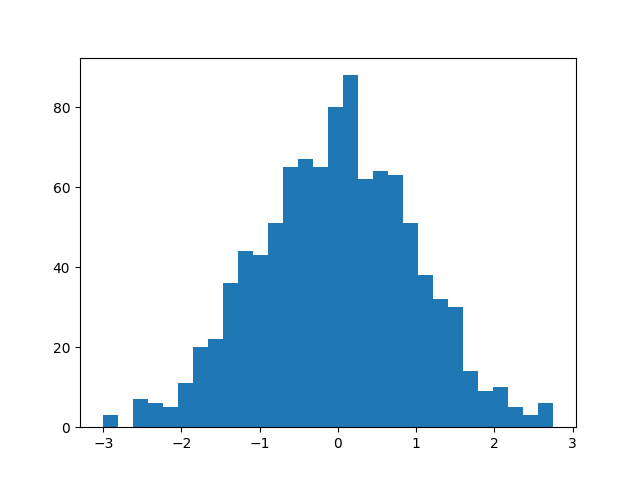
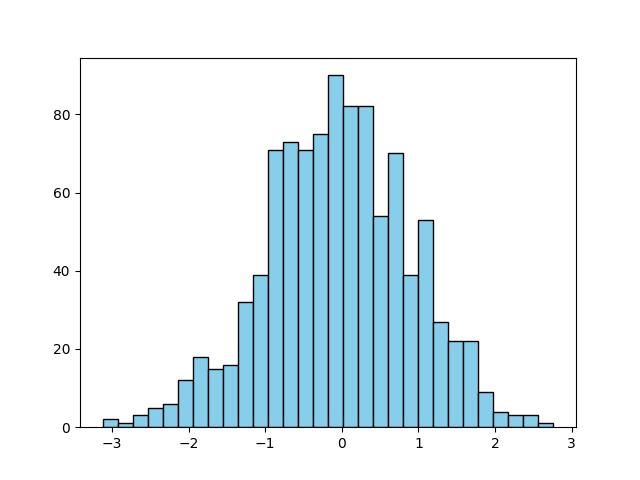
히스토그램 색상 및 edgecolor 사용자 지정
이 단계에서는 히스토그램의 시각적 모양을 사용자 지정합니다. 잘 스타일링된 플롯은 읽기 쉽고 더 전문적입니다. plt.hist() 함수는 막대 채우기를 위한 color와 막대 테두리를 위한 edgecolor를 포함하여 스타일링을 위한 여러 매개변수를 제공합니다.
막대 색상을 하늘색으로 변경하고 검은색 테두리를 추가하여 각 빈을 더 명확하게 구분해 보겠습니다.
이러한 새 매개변수를 포함하도록 main.py 파일을 수정합니다. 이 사용자 지정 플롯을 histogram_color.png에 저장합니다.
import numpy as np
import matplotlib.pyplot as plt
## 샘플 데이터 생성
data = np.random.normal(loc=0, scale=1, size=1000)
## 30 개의 빈, 사용자 지정 색상 및 테두리 색상으로 히스토그램 생성
plt.hist(data, bins=30, color='skyblue', edgecolor='black')
## 새 파일에 플롯 저장
plt.savefig('/home/labex/project/histogram_color.png')
print("Styled histogram saved to histogram_color.png")
터미널에서 스크립트를 실행합니다.
python3 main.py
다음 메시지가 표시됩니다.
Styled histogram saved to histogram_color.png
새로 생성된 histogram_color.png 파일을 엽니다. 하늘색 막대와 뚜렷한 검은색 윤곽선이 있는 훨씬 더 세련된 히스토그램을 볼 수 있습니다.
density=True 를 사용하여 히스토그램 정규화
이 단계에서는 정규화된 히스토그램을 만드는 방법을 배웁니다. 기본적으로 히스토그램의 y 축은 각 빈에 있는 데이터 포인트의 개수를 나타냅니다. 그러나 때로는 분포를 확률 밀도 (probability density) 로 보는 것이 더 유용할 수 있습니다. 정규화된 히스토그램에서는 모든 막대의 총 면적이 1 이 되도록 각 막대의 높이가 조정됩니다.
이는 plt.hist() 함수에서 density 매개변수를 True로 설정하여 달성할 수 있습니다. 또한 플롯을 자체 설명적으로 만들기 위해 레이블과 제목을 추가하는 것이 좋습니다.
스크립트를 업데이트하여 정규화된 히스토그램을 만들고 설명적인 레이블을 추가해 보겠습니다.
import numpy as np
import matplotlib.pyplot as plt
## 샘플 데이터 생성
data = np.random.normal(loc=0, scale=1, size=1000)
## 정규화된 히스토그램 생성
plt.hist(data, bins=30, color='skyblue', edgecolor='black', density=True)
## 제목 및 레이블 추가
plt.title('Normalized Histogram of Sample Data')
plt.xlabel('Value')
plt.ylabel('Probability Density')
## 새 파일에 플롯 저장
plt.savefig('/home/labex/project/histogram_normalized.png')
print("Normalized histogram saved to histogram_normalized.png")
스크립트의 최종 버전을 실행합니다.
python3 main.py
출력은 다음과 같습니다.
Normalized histogram saved to histogram_normalized.png
histogram_normalized.png를 엽니다. 이제 y 축 값이 훨씬 작아진 것을 알 수 있습니다. 이 값들은 실제 개수가 아니라 확률 밀도를 나타냅니다. 분포의 전반적인 모양은 동일하게 유지되지만, 이제 스케일이 표준화되어 다른 크기의 데이터셋 분포를 비교하는 데 유용합니다.
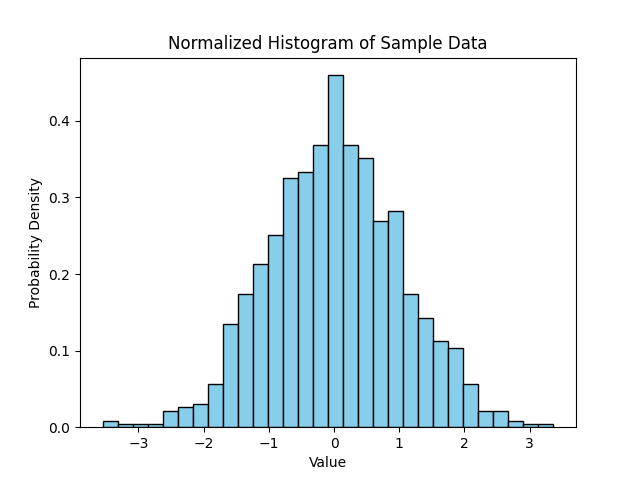
요약
이 랩을 완료하신 것을 축하드립니다! Python 의 Matplotlib 을 사용하여 히스토그램을 생성하고 사용자 지정하는 필수 기술을 익혔습니다.
이 랩에서는 다음을 수행했습니다.
numpy.random.normal()을 사용하여 샘플 데이터를 생성했습니다.plt.hist()로 기본 히스토그램을 플로팅했습니다.bins매개변수를 사용하여 빈의 개수를 제어했습니다.color및edgecolor매개변수로 히스토그램을 스타일링했습니다.density=True를 사용하여 정규화된 확률 밀도 히스토그램을 생성했습니다.- 더 나은 맥락을 위해 플롯에 제목과 레이블을 추가했습니다.
히스토그램은 데이터 탐색 및 분석의 기본 도구입니다. 여기서 배운 기술을 통해 자신의 데이터셋 분포를 효과적으로 시각화할 수 있습니다. Matplotlib 의 다른 매개변수 및 플롯 유형으로 계속 실험해 보세요.


