
소개
이 랩은 주로 Hadoop 의 기초에 관한 내용이며, Hadoop 소프트웨어 시스템의 아키텍처와 기본적인 배포 방법을 이해하기 위해 어느 정도의 Linux 기반을 가진 학생들을 위해 작성되었습니다.
문서에 있는 모든 예제 코드는 직접 입력하십시오. 가능한 한 복사하여 붙여넣지 마십시오. 이렇게 해야 코드에 더 익숙해질 수 있습니다. 문제가 발생하면 문서를 주의 깊게 검토하고, 그렇지 않으면 포럼에서 도움을 받거나 소통할 수 있습니다.
Hadoop 소개
Apache 2.0 라이선스 하에 출시된 Apache Hadoop 은 데이터 집약적인 분산 애플리케이션을 지원하는 오픈 소스 소프트웨어 프레임워크입니다.
Apache Hadoop 소프트웨어 라이브러리는 간단한 프로그래밍 모델을 사용하여 컴퓨팅 클러스터에서 대규모 데이터 세트를 분산 처리할 수 있도록 하는 프레임워크입니다. 단일 서버에서 수천 대의 머신까지 확장되도록 설계되었으며, 각 머신은 고가용성을 제공하기 위해 하드웨어에 의존하지 않고 로컬 컴퓨팅 및 스토리지를 제공합니다.
핵심 개념
Hadoop 프로젝트는 주로 다음 네 가지 모듈을 포함합니다.
- Hadoop Common: 다른 Hadoop 모듈을 지원하는 공용 애플리케이션입니다.
- Hadoop Distributed File System (HDFS): 애플리케이션 데이터에 대한 높은 처리량 액세스를 제공하는 분산 파일 시스템입니다.
- Hadoop YARN: 작업 스케줄링 및 클러스터 리소스 관리 프레임워크입니다.
- Hadoop MapReduce: YARN 을 기반으로 하는 대규모 데이터 세트 병렬 컴퓨팅 프레임워크입니다.
Hadoop 을 처음 접하는 사용자는 HDFS 와 MapReduce 에 집중해야 합니다. 분산 컴퓨팅 프레임워크로서 HDFS 는 데이터에 대한 프레임워크의 스토리지 요구 사항을 충족하고 MapReduce 는 데이터에 대한 프레임워크의 계산 요구 사항을 충족합니다.
다음 그림은 Hadoop 클러스터의 기본 아키텍처를 보여줍니다.
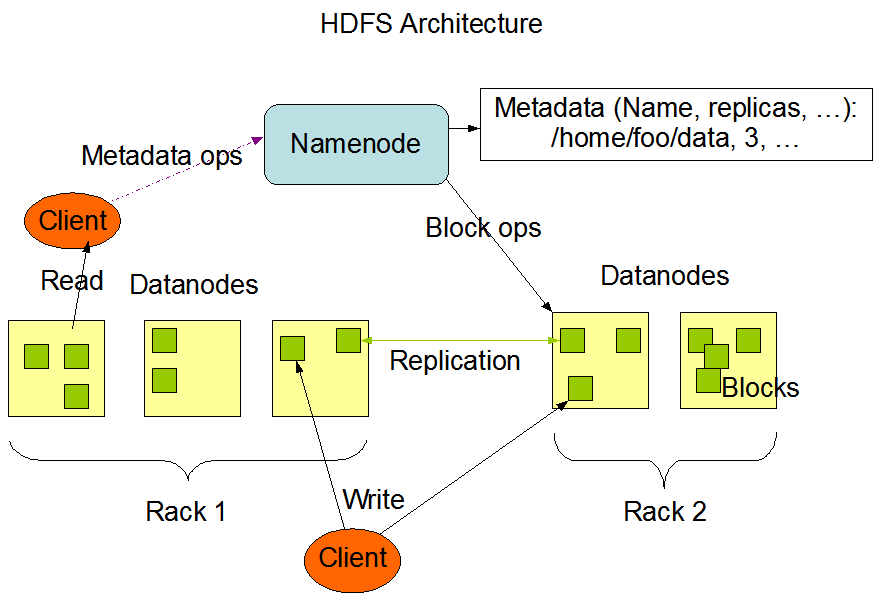
이 그림은 Hadoop 공식 웹사이트에서 인용되었습니다.
Hadoop 생태계
Facebook 이 Hadoop 을 기반으로 Hive 데이터 저장소를 파생시킨 것처럼, 커뮤니티에는 이와 관련된 많은 오픈 소스 프로젝트가 있습니다. 다음은 최근 활발하게 진행되는 프로젝트입니다.
- HBase: 대규모 테이블에 대한 구조화된 데이터 저장을 지원하는 확장 가능한 분산 데이터베이스입니다.
- Hive: 데이터 요약 및 임시 쿼리를 제공하는 데이터 저장소 인프라입니다.
- Pig: 병렬 컴퓨팅을 위한 고급 데이터 흐름 언어 및 실행 프레임워크입니다.
- ZooKeeper: 분산 애플리케이션을 위한 고성능 조정 서비스입니다.
- Spark: 데이터 ETL (추출, 변환 및 로드), 머신 러닝, 스트림 처리 및 그래픽 컴퓨팅을 지원하는 간단하고 표현력이 풍부한 프로그래밍 모델을 갖춘 빠르고 다재다능한 Hadoop 데이터 계산 엔진입니다.
이 랩에서는 Hadoop 부터 시작하여 관련 구성 요소의 기본 사용법을 소개합니다.
분산 메모리 컴퓨팅 프레임워크인 Spark는 Hadoop 시스템에서 파생되었다는 점에 주목할 가치가 있습니다. HDFS 및 YARN 과 같은 구성 요소에 대한 좋은 상속성을 가지며, Hadoop 의 기존 단점을 개선하기도 합니다.
Hadoop 과 Spark 의 사용 시나리오가 중복되는 부분에 대해 질문이 있을 수 있지만, Hadoop 의 작업 패턴과 프로그래밍 패턴을 배우는 것은 Spark 프레임워크에 대한 이해를 심화하는 데 도움이 되므로, 먼저 Hadoop 을 배우는 것이 좋습니다.
Hadoop 배포
초보자의 경우, Hadoop 버전 2.0 이후 버전 간에는 큰 차이가 없습니다. 이 섹션에서는 3.3.6 버전을 예로 들겠습니다.
Hadoop 에는 세 가지 주요 배포 패턴이 있습니다.
- Stand-alone pattern (독립형 패턴): 단일 컴퓨터에서 단일 프로세스로 실행됩니다.
- Pseudo-distributed pattern (의사 분산 패턴): 단일 컴퓨터에서 여러 프로세스로 실행됩니다. 이 패턴은 단일 노드에서 "다중 노드" 시나리오를 시뮬레이션합니다.
- Fully distributed pattern (완전 분산 패턴): 여러 컴퓨터 각각에서 단일 프로세스로 실행됩니다.
다음으로, 단일 컴퓨터에 Hadoop 3.3.6 버전을 설치합니다.
사용자 및 사용자 그룹 설정
데스크톱에서 Xfce 터미널을 두 번 클릭하여 열고 다음 명령을 입력하여 hadoop이라는 사용자를 생성합니다.
cd ~
sudo adduser hadoop
그리고 프롬프트에 따라 hadoop 사용자의 비밀번호를 입력합니다. 예를 들어, 비밀번호를 hadoop으로 설정합니다.
참고: 비밀번호를 입력할 때는 명령에 프롬프트가 표시되지 않습니다. 완료되면 Enter 키를 누르기만 하면 됩니다.
그런 다음 생성된 hadoop 사용자를 sudo 사용자 그룹에 추가하여 사용자에게 더 높은 권한을 부여합니다.
sudo usermod -G sudo hadoop
다음 명령을 입력하여 hadoop 사용자가 sudo 그룹에 추가되었는지 확인합니다.
sudo cat /etc/group | grep hadoop
다음과 같은 출력이 표시되어야 합니다.
sudo:x:27:shiyanlou,labex,hadoop
JDK 설치
이전 내용에서 언급했듯이 Hadoop 은 주로 Java 로 개발되었습니다. 따라서 실행하려면 Java 환경이 필요합니다.
Hadoop 의 각 버전은 Java 버전 요구 사항에 미묘한 차이가 있습니다. Hadoop 에 적합한 JDK 버전을 찾으려면 Hadoop Wiki 웹사이트에서 Hadoop Java Versions를 참조하십시오.
사용자를 전환합니다.
su - hadoop
터미널에서 다음 명령을 입력하여 JDK 11 버전을 설치합니다.
sudo apt update
sudo apt install openjdk-11-jdk -y
성공적으로 설치했으면 현재 Java 버전을 확인합니다.
java -version
출력을 확인합니다.
openjdk version "11.0.22" 2024-01-16
OpenJDK Runtime Environment (build 11.0.22+7-post-Ubuntu-0ubuntu222.04.1)
OpenJDK 64-Bit Server VM (build 11.0.22+7-post-Ubuntu-0ubuntu222.04.1, mixed mode, sharing)
비밀번호 없는 SSH 로그인 설정
SSH를 설치하고 구성하는 목적은 Hadoop 이 원격 관리 데몬과 관련된 스크립트를 쉽게 실행할 수 있도록 하기 위함입니다. 이러한 스크립트는 sshd 서비스를 필요로 합니다.
구성을 시작하려면 먼저 hadoop 사용자로 전환합니다. 터미널에서 다음 명령을 입력하여 전환합니다.
su hadoop
비밀번호를 입력하라는 프롬프트가 표시되면, 이전에 사용자 (hadoop) 를 생성할 때 지정한 비밀번호를 입력하십시오.
사용자 전환이 성공하면 명령 프롬프트가 위와 같이 표시됩니다. 후속 단계는 hadoop 사용자로 작업을 수행합니다.
다음으로 비밀번호 없는 SSH 로그인을 위한 키를 생성합니다.
소위 "비밀번호 없는"은 SSH 의 인증 패턴을 비밀번호 로그인에서 키 로그인으로 변경하여 Hadoop 의 각 구성 요소가 서로 액세스할 때 사용자 상호 작용을 통해 비밀번호를 입력할 필요가 없도록 하여 많은 중복 작업을 줄일 수 있도록 합니다.
먼저 사용자의 홈 디렉토리로 전환한 다음 ssh-keygen 명령을 사용하여 RSA 키를 생성합니다.
터미널에서 다음 명령을 입력하십시오.
cd /home/hadoop
ssh-keygen -t rsa
키가 저장되는 위치와 같은 정보가 나타나면 Enter 키를 눌러 기본값을 사용할 수 있습니다.
The key's randomart image is:
+---[RSA 3072]----+
| ..+. |
| . = . o |
| .o o * . |
| o .. . + o |
| = +.S. . + |
| + + +++. . |
| . B.O+. |
| o +oXo*E |
| =.+==o. |
+----[SHA256]-----+
키가 생성되면 공개 키는 사용자의 홈 디렉토리 아래 .ssh 디렉토리에 생성됩니다.
구체적인 작업은 아래 그림과 같습니다.
그런 다음 다음 명령을 계속 입력하여 생성된 공개 키를 호스트 인증 레코드에 추가합니다. authorized_keys 파일에 쓰기 권한을 부여하지 않으면 확인 중에 올바르게 수행되지 않습니다.
cat .ssh/id_rsa.pub >> .ssh/authorized_keys
chmod 600 .ssh/authorized_keys
추가가 성공적으로 완료되면 localhost에 로그인해 봅니다. 터미널에서 다음 명령을 입력하십시오.
ssh localhost
처음 로그인할 때 공개 키 지문을 확인하라는 메시지가 표시되면 yes를 입력하고 확인합니다. 그러면 다시 로그인할 때 비밀번호 없는 로그인이 됩니다.
...
Welcome to Alibaba Cloud Elastic Compute Service !
To run a command as administrator (user "root"), use "sudo <command>".
See "man sudo_root" for details.
hadoop:~$
확인 스크립트를 통과하려면 history -w를 입력하거나 터미널을 종료하여 변경 사항을 저장해야 합니다.
Hadoop 설치
이제 Hadoop 설치 패키지를 다운로드할 수 있습니다. 공식 웹사이트는 최신 버전의 Hadoop 다운로드 링크를 제공합니다. 또한 wget 명령을 사용하여 터미널에서 직접 패키지를 다운로드할 수 있습니다.
패키지를 다운로드하려면 터미널에서 다음 명령을 입력하십시오.
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz
다운로드가 완료되면 tar 명령을 사용하여 패키지를 압축 해제할 수 있습니다.
tar zxvf hadoop-3.3.6.tar.gz
sudo mv hadoop-3.3.6 hadoop
sudo chown -R hadoop:hadoop /home/hadoop
터미널에서 dirname $(dirname $(readlink -f $(which java))) 명령을 실행하여 JAVA_HOME 위치를 찾을 수 있습니다.
dirname $(readlink -f $(which java))
그런 다음 터미널에서 텍스트 편집기를 사용하여 .bashrc 파일을 엽니다.
vim /home/hadoop/.bashrc
/home/hadoop/.bashrc 파일의 끝에 다음을 추가합니다.
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
export HADOOP_HOME=/home/hadoop/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
vim 편집기를 저장하고 종료합니다. 그런 다음 터미널에서 source 명령을 입력하여 새로 추가된 환경 변수를 활성화합니다.
source /home/hadoop/.bashrc
터미널에서 hadoop version 명령을 실행하여 설치를 확인합니다.
hadoop@iZj6cgdabeniugz9ypibzxZ:~$ hadoop version
Hadoop 3.3.6
Source code repository https://github.com/apache/hadoop.git -r 1be78238728da9266a4f88195058f08fd012bf9c
Compiled by ubuntu on 2023-06-18T08:22Z
Compiled on platform linux-x86_64
Compiled with protoc 3.7.1
From source with checksum 5652179ad55f76cb287d9c633bb53bbd
This command was run using /home/hadoop/hadoop/share/hadoop/common/hadoop-common-3.3.6.jar
Pseudo-Distributed 패턴 설정
대부분의 경우 Hadoop 은 클러스터 환경에서 사용됩니다. 즉, 여러 노드에 Hadoop 을 배포해야 합니다. 동시에 Hadoop 은 여러 독립적인 Java 프로세스를 통해 다중 노드 시나리오를 시뮬레이션하여 의사 분산 패턴으로 단일 노드에서 실행될 수도 있습니다. 초기 학습 단계에서는 다양한 노드를 생성하는 데 많은 리소스를 소비할 필요가 없습니다. 따라서 이 섹션과 후속 장에서는 Hadoop "클러스터" 배포에 주로 의사 분산 패턴을 사용합니다.
디렉토리 생성
시작하려면 Hadoop 사용자의 홈 디렉토리 내에 namenode 및 datanode 디렉토리를 생성합니다. 다음 명령을 실행하여 이러한 디렉토리를 생성합니다.
rm -rf ~/hadoopdata
mkdir -p ~/hadoopdata/hdfs/{namenode,datanode}
그런 다음 Hadoop 이 의사 분산 패턴으로 실행되도록 Hadoop 의 구성 파일을 수정해야 합니다.
core-site.xml 편집
터미널에서 텍스트 편집기를 사용하여 core-site.xml 파일을 엽니다.
vim /home/hadoop/hadoop/etc/hadoop/core-site.xml
구성 파일에서 configuration 태그의 값을 다음 내용으로 수정합니다.
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
fs.defaultFS 구성 항목은 클러스터가 기본적으로 사용하는 파일 시스템의 위치를 나타내는 데 사용됩니다.
편집 후 파일을 저장하고 vim을 종료합니다.
hdfs-site.xml 편집
다른 구성 파일인 hdfs-site.xml을 엽니다.
vim /home/hadoop/hadoop/etc/hadoop/hdfs-site.xml
구성 파일에서 configuration 태그의 값을 다음으로 수정합니다.
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopdata/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopdata/hdfs/datanode</value>
</property>
</configuration>
이 구성 항목은 HDFS 의 파일 복사본 수를 나타내는 데 사용되며 기본값은 3입니다. 단일 노드에서 의사 분산 방식으로 배포했으므로 1로 수정합니다.
편집 후 파일을 저장하고 vim을 종료합니다.
hadoop-env.sh 편집
다음으로 hadoop-env.sh 파일을 편집합니다.
vim /home/hadoop/hadoop/etc/hadoop/hadoop-env.sh
JAVA_HOME의 값을 설치된 JDK 의 실제 위치, 즉 /usr/lib/jvm/java-11-openjdk-amd64로 변경합니다.
참고:
echo $JAVA_HOME명령을 사용하여 설치된 JDK 의 실제 위치를 확인할 수 있습니다.
편집 후 파일을 저장하고 vim 편집기를 종료합니다.
yarn-site.xml 편집
다음으로 yarn-site.xml 파일을 편집합니다.
vim /home/hadoop/hadoop/etc/hadoop/yarn-site.xml
configuration 태그에 다음을 추가합니다.
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
편집 후 파일을 저장하고 vim 편집기를 종료합니다.
mapred-site.xml 편집
마지막으로 mapred-site.xml 파일을 편집해야 합니다.
vim 편집기로 파일을 엽니다.
vim /home/hadoop/hadoop/etc/hadoop/mapred-site.xml
마찬가지로 configuration 태그에 다음을 추가합니다.
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/home/hadoop/hadoop</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/home/hadoop/hadoop</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/home/hadoop/hadoop</value>
</property>
</configuration>
편집 후 파일을 저장하고 vim 편집기를 종료합니다.
Hadoop 시작 테스트
먼저 데스크톱에서 Xfce 터미널을 열고 Hadoop 사용자로 전환합니다.
su -l hadoop
HDFS 의 초기화는 주로 포맷팅입니다.
/home/hadoop/hadoop/bin/hdfs namenode -format
팁: 포맷팅 전에 HDFS 데이터 디렉토리를 삭제해야 합니다.
다음 메시지를 확인하면 성공을 의미합니다.
2024-02-29 18:24:53,887 INFO common.Storage: Storage directory /home/hadoop/hadoopdata/hdfs/namenode has been successfully formatted.
확인 스크립트를 통과하려면 history -w를 입력하거나 터미널을 종료하여 기록을 저장해야 합니다.
HDFS 시작
HDFS 초기화가 완료되면 NameNode 및 DataNode에 대한 데몬을 시작할 수 있습니다. 시작되면 Hadoop 애플리케이션 (예: MapReduce 작업) 은 HDFS 에서 파일을 읽고 쓸 수 있습니다.
터미널에서 다음 명령을 입력하여 데몬을 시작합니다.
/home/hadoop/hadoop/sbin/start-dfs.sh
출력을 확인합니다.
Starting namenodes on [localhost]
Starting datanodes
Starting secondary namenodes [iZj6cjditp4l7k0fylhhfbZ]
iZj6cjditp4l7k0fylhhfbZ: Warning: Permanently added 'izj6cjditp4l7k0fylhhfbz' (ED25519) to the list of known hosts.
Hadoop 이 의사 분산 패턴으로 성공적으로 실행되었는지 확인하려면 Java 의 프로세스 보기 도구인 jps를 사용하여 해당 프로세스가 있는지 확인할 수 있습니다.
터미널에서 다음 명령을 입력합니다.
jps
그림과 같이 NameNode, DataNode 및 SecondaryNameNode 프로세스가 보이면 Hadoop 서비스가 정상적으로 실행되고 있음을 나타냅니다.
로그 파일 및 WebUI 확인
Hadoop 이 시작되지 않거나 작업 (또는 기타) 이 실행되는 동안 오류가 보고되면 터미널의 프롬프트 정보 외에도 로그를 보는 것이 문제를 찾는 가장 좋은 방법입니다. 대부분의 문제는 관련 소프트웨어의 로그를 통해 원인과 해결책을 찾을 수 있습니다. 빅 데이터 분야의 학습자로서 로그를 분석하는 능력은 컴퓨팅 프레임워크를 배우는 능력만큼 중요하며 진지하게 받아들여야 합니다.
Hadoop 데몬 로그의 기본 출력은 설치 디렉토리 아래의 로그 디렉토리 (logs) 에 있습니다. 터미널에서 다음 명령을 입력하여 로그 디렉토리에 들어갑니다.
ls /home/hadoop/hadoop/logs
hadoop-hadoop-datanode-iZj6cjditp4l7k0fylhhfbZ.log
hadoop-hadoop-datanode-iZj6cjditp4l7k0fylhhfbZ.out
hadoop-hadoop-namenode-iZj6cjditp4l7k0fylhhfbZ.log
hadoop-hadoop-namenode-iZj6cjditp4l7k0fylhhfbZ.out
hadoop-hadoop-secondarynamenode-iZj6cjditp4l7k0fylhhfbZ.log
hadoop-hadoop-secondarynamenode-iZj6cjditp4l7k0fylhhfbZ.out
SecurityAuth-hadoop.audit
vim 편집기를 사용하여 모든 로그 파일을 볼 수 있습니다.
HDFS 가 시작된 후 내부 웹 서비스에서 클러스터 상태를 표시하는 웹 페이지도 제공합니다. LabEx VM 상단으로 전환하고 "Web 8088"을 클릭하여 웹 페이지를 엽니다.
웹 페이지를 연 후 클러스터 개요, DataNode의 상태 등을 볼 수 있습니다.
페이지 상단의 메뉴를 클릭하여 팁과 기능을 자유롭게 탐색하십시오.
확인 스크립트를 통과하려면 history -w를 입력하거나 터미널을 종료하여 기록을 저장해야 합니다.
HDFS 파일 업로드 테스트
HDFS 가 실행되면 파일 시스템으로 간주할 수 있습니다. 여기서는 파일 업로드 기능을 테스트하기 위해 디렉토리를 생성하고 (단계별로 한 단계씩, 필요한 디렉토리 수준까지) Linux 시스템의 일부 파일을 HDFS 에 업로드해 봅니다.
cd ~
/home/hadoop/hadoop/bin/hdfs dfs -mkdir /user
/home/hadoop/hadoop/bin/hdfs dfs -mkdir /user/hadoop
디렉토리가 성공적으로 생성된 후 hdfs dfs -put 명령을 사용하여 로컬 디스크의 파일 (여기서는 임의로 선택한 Hadoop 구성 파일) 을 HDFS 에 업로드합니다.
/home/hadoop/hadoop/bin/hdfs dfs -put /home/hadoop/hadoop/etc/hadoop /user/hadoop/input
PI 테스트 케이스
실제 운영 환경에서 배포되어 실제 문제를 해결하는 Hadoop 애플리케이션의 대부분은 WordCount로 대표되는 MapReduce 프로그래밍 모델을 기반으로 합니다. 따라서 WordCount는 Hadoop 시작을 위한 "HelloWorld" 프로그램으로 사용하거나, 특정 문제를 해결하기 위해 자신만의 아이디어를 추가할 수 있습니다.
작업 시작
이전 섹션의 마지막 부분에서 예시로 몇 가지 구성 파일을 HDFS 에 업로드했습니다. 다음으로, 이러한 파일의 단어 빈도 통계를 얻고 필터링 규칙에 따라 출력하기 위해 PI 테스트 케이스를 실행해 볼 수 있습니다.
먼저 터미널에서 YARN 계산 서비스를 시작합니다.
/home/hadoop/hadoop/sbin/start-yarn.sh
그런 다음 다음 명령을 입력하여 작업을 시작합니다.
/home/hadoop/hadoop/bin/hadoop jar /home/hadoop/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar pi 3 3
출력 결과를 봅니다.
Estimated value of Pi is 3.55555555555555555556
위의 매개변수 중 경로와 관련된 세 가지 매개변수가 있습니다. 이는 jar 패키지의 위치, 입력 파일의 위치 및 출력 결과의 저장 위치입니다. 경로를 지정할 때는 절대 경로를 지정하는 습관을 들이는 것이 좋습니다. 이는 문제를 빠르게 찾고 작업을 신속하게 전달하는 데 도움이 됩니다.
작업을 완료하면 결과를 볼 수 있습니다.
HDFS 서비스 종료
계산 후 HDFS 의 파일을 사용하는 다른 소프트웨어 프로그램이 없으면 HDFS 데몬을 즉시 종료해야 합니다.
분산 클러스터 및 관련 컴퓨팅 프레임워크의 사용자로서 클러스터 열기 및 닫기, 하드웨어 및 소프트웨어 설치 또는 모든 종류의 업데이트와 관련된 모든 경우 관련 하드웨어 및 소프트웨어의 상태를 적극적으로 확인하는 좋은 습관을 들여야 합니다.
터미널에서 다음 명령을 사용하여 HDFS 및 YARN 데몬을 종료합니다.
/home/hadoop/hadoop/sbin/stop-yarn.sh
/home/hadoop/hadoop/sbin/stop-dfs.sh
확인 스크립트를 통과하려면 history -w를 입력하거나 터미널을 종료하여 기록을 저장해야 합니다.
요약
이 랩에서는 Hadoop 의 아키텍처, 독립 실행형 패턴 및 의사 분산 패턴의 설치 및 배포 방법, 그리고 기본적인 테스트를 위한 WordCount 실행을 소개했습니다.
이 랩의 주요 내용은 다음과 같습니다.
- Hadoop 아키텍처
- Hadoop 주요 모듈
- Hadoop 독립 실행형 패턴 사용 방법
- Hadoop 의사 분산 패턴 배포
- HDFS 의 기본 사용법
- WordCount 테스트 케이스
일반적으로 Hadoop 은 빅 데이터 분야에서 일반적으로 사용되는 컴퓨팅 및 스토리지 프레임워크입니다. 그 기능은 더 탐구할 필요가 있습니다. 기술 자료를 참조하는 습관을 유지하고 후속 학습을 계속하십시오.


