
소개
이 랩에서는 Hadoop 의 주요 구성 요소 중 하나인 HDFS 에 대해 계속 이야기할 것입니다. 이 랩을 통해 HDFS 의 작동 원리 및 기본 작업, 그리고 Hadoop 소프트웨어 아키텍처에서 WebHDFS 에 접근하는 방법을 이해하는 데 도움이 될 것입니다.
HDFS 소개
이름에서 알 수 있듯이, HDFS (Hadoop Distributed File System) 는 Hadoop 프레임워크 내의 분산 저장소 구성 요소이며, 내결함성 (fault tolerant) 과 확장성을 갖습니다.
HDFS 는 Hadoop 클러스터의 일부로 사용되거나 독립 실행형 범용 분산 파일 시스템으로 사용될 수 있습니다. 예를 들어, HBase는 HDFS 를 기반으로 구축되었으며 Spark 역시 HDFS 를 데이터 소스 중 하나로 사용할 수 있습니다. HDFS 의 아키텍처와 기본 작업을 배우는 것은 특정 클러스터의 구성, 개선 및 진단에 큰 도움이 될 것입니다.
HDFS 는 Hadoop 애플리케이션에서 사용되는 분산 저장소이며, 데이터의 소스이자 대상입니다. HDFS 클러스터는 주로 *파일 시스템 메타데이터를 관리하는 **NameNodes***와 *실제 데이터를 저장하는 **DataNodes***로 구성됩니다. 아키텍처는 다음 그림에 나와 있으며, NameNodes, DataNodes, 그리고 Clients 간의 상호 작용 패턴을 보여줍니다.
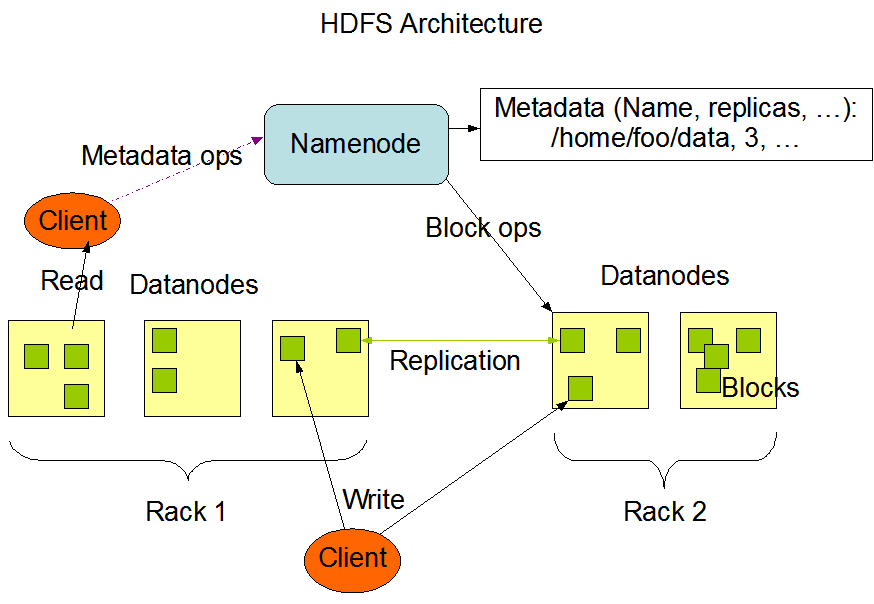 이 그림은 Hadoop 공식 웹사이트에서 인용되었습니다.
이 그림은 Hadoop 공식 웹사이트에서 인용되었습니다.
HDFS 소개 요약:
- HDFS 개요: HDFS (Hadoop Distributed File System) 는 Hadoop 프레임워크 내의 내결함성 및 확장 가능한 분산 저장소 구성 요소입니다.
- 아키텍처: HDFS 클러스터는 메타데이터 관리를 위한 NameNodes 와 실제 데이터 저장을 위한 DataNodes 로 구성됩니다. 아키텍처는 하나의 NameNode 와 여러 DataNodes 를 사용하는 Master/Slave 모델을 따릅니다.
- 파일 저장: HDFS 의 파일은 DataNodes 에 분산 저장되는 블록으로 나뉘며, 기본 블록 크기는 64MB 입니다.
- 작업: NameNode 는 파일 시스템 네임스페이스 작업을 처리하고, DataNodes 는 클라이언트의 읽기 및 쓰기 요청을 관리합니다.
- 상호 작용: 클라이언트는 메타데이터를 위해 NameNode 와 통신하고, 파일 데이터를 위해 DataNodes 와 직접 상호 작용합니다.
- 배포: 일반적으로, 단일 전용 노드가 NameNode 를 실행하고, 다른 각 노드는 DataNode 인스턴스를 실행합니다. HDFS 는 Java 를 사용하여 구축되어 다양한 환경에서 이식성을 제공합니다.
HDFS 에 대한 이러한 핵심 사항을 이해하면 Hadoop 클러스터를 효과적으로 구성, 최적화 및 진단하는 데 도움이 됩니다.
파일 시스템 개요
파일 시스템 네임스페이스
- 계층적 구성: HDFS 와 전통적인 Linux 파일 시스템 모두 디렉토리 트리 구조를 사용하여 계층적 파일 구성을 지원하므로 사용자와 애플리케이션이 디렉토리를 생성하고 파일을 저장할 수 있습니다.
- 접근 및 작업: 사용자는 명령줄 및 API 와 같은 다양한 접근 인터페이스를 통해 HDFS 와 상호 작용하여 파일 생성, 삭제, 이동 및 이름 변경과 같은 작업을 수행할 수 있습니다.
- 기능 지원: 버전 3.3.6 현재 HDFS 는 사용자 할당량, 접근 권한, 하드 링크 또는 소프트 링크를 구현하지 않습니다. 그러나 아키텍처가 이러한 기능을 구현할 수 있도록 허용하므로 향후 릴리스에서 이러한 기능을 지원할 수 있습니다.
- NameNode 관리: HDFS 의 NameNode 는 파일 시스템 메타데이터에 대한 모든 변경 사항과 속성을 처리하며, HDFS 에 유지할 파일 복사본 수를 지정하는 파일의 복제 인자를 관리합니다.
데이터 복사
개발 초기에 HDFS 는 매우 큰 파일을 대규모 클러스터에 노드 간, 고가용성 방식으로 저장하도록 설계되었습니다. 앞서 언급했듯이 HDFS 는 파일을 블록 단위로 저장합니다. 구체적으로, 각 파일을 블록 시퀀스로 저장합니다. 마지막 블록을 제외하고 파일의 모든 블록은 동일한 크기입니다.
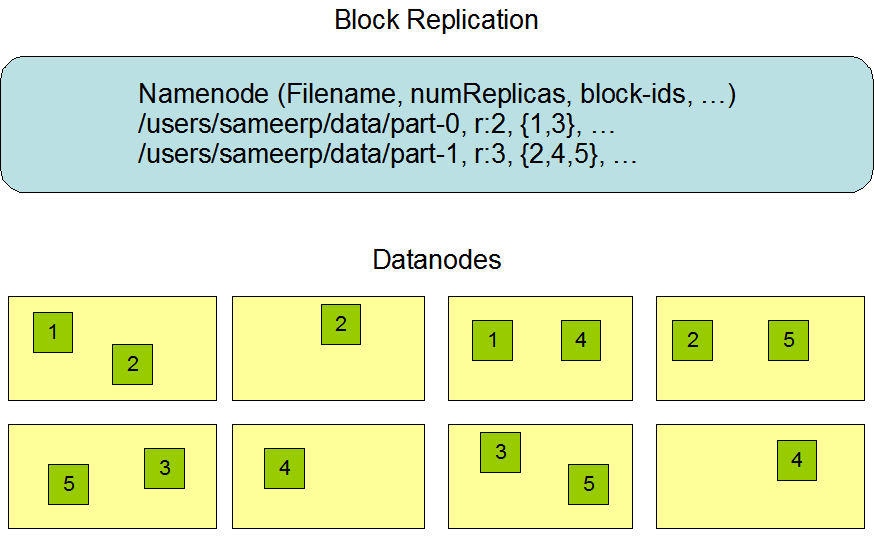 이 그림은 Hadoop 공식 웹사이트에서 인용되었습니다.
이 그림은 Hadoop 공식 웹사이트에서 인용되었습니다.
HDFS 데이터 복제 및 고가용성:
- 데이터 복제: HDFS 에서 파일은 내결함성을 보장하기 위해 여러 DataNode 에 걸쳐 복제되는 블록으로 나뉩니다. 파일 생성 또는 수정 시 복제 인자를 지정할 수 있으며, 각 파일은 특정 시점에 단일 작성자를 갖습니다.
- 복제 관리: NameNode 는 DataNode 로부터 하트비트 및 블록 상태 보고서를 수신하여 파일 블록이 복사되는 방식을 관리합니다. DataNode 는 하트비트를 통해 작업 상태를 보고하고, 블록 상태 보고서에는 DataNode 에 저장된 모든 블록에 대한 정보가 포함됩니다.
- 고가용성: HDFS 는 디스크 손상 또는 기타 오류 발생 시 클러스터의 다른 부분에서 손실된 파일 복사본을 내부적으로 복원하여 어느 정도의 고가용성을 제공합니다. 이 메커니즘은 분산 저장 시스템 내에서 데이터 무결성 및 안정성을 유지하는 데 도움이 됩니다.
파일 시스템 메타데이터의 지속성
- 네임스페이스 관리: 파일 시스템 메타데이터를 포함하는 HDFS 네임스페이스는 NameNode 에 저장됩니다. 파일 시스템 메타데이터의 모든 변경 사항은 파일 생성과 같은 트랜잭션을 지속하는 EditLog 에 기록됩니다. EditLog 는 로컬 파일 시스템에 저장됩니다.
- FsImage: 블록 - 파일 매핑 및 속성을 포함한 전체 파일 시스템 네임스페이스는 FsImage 라는 파일에 저장됩니다. 이 파일은 NameNode 가 있는 로컬 파일 시스템에도 저장됩니다.
- 체크포인트 프로세스: 체크포인트 프로세스에는 NameNode 시작 시 디스크에서 FsImage 및 EditLog 를 읽는 작업이 포함됩니다. EditLog 의 모든 트랜잭션은 메모리 내 FsImage 에 적용된 다음 지속성을 위해 다시 디스크에 저장됩니다. 이 프로세스 후에는 이전 EditLog 를 잘라낼 수 있습니다. 현재 버전 (3.3.6) 에서는 체크포인트가 NameNode 시작 시에만 발생하지만, 향후 버전에서는 향상된 안정성과 데이터 일관성을 위해 주기적인 체크포인트를 도입할 수 있습니다.
기타 기능
- TCP/IP 기반: HDFS 의 모든 통신 프로토콜은 TCP/IP 프로토콜 제품군을 기반으로 구축되어 분산 파일 시스템의 노드 간에 안정적인 데이터 교환을 보장합니다.
- 클라이언트 프로토콜: 클라이언트와 NameNode 간의 통신은 클라이언트 프로토콜을 통해 용이하게 이루어집니다. 클라이언트는 NameNode 의 구성 가능한 TCP 포트에 연결을 시작하여 파일 시스템 메타데이터와 상호 작용합니다.
- DataNode 프로토콜: DataNode 와 NameNode 간의 통신은 DataNode 프로토콜에 의존합니다. DataNode 는 NameNode 와 통신하여 상태를 보고하고, 하트비트 신호를 보내고, 분산 저장 시스템의 일부로 데이터 블록을 전송합니다.
- 원격 프로시저 호출 (RPC): 클라이언트 프로토콜과 DataNode 프로토콜 모두 원격 프로시저 호출 (RPC) 메커니즘을 사용하여 추상화됩니다. NameNode 는 DataNode 또는 클라이언트에서 시작된 RPC 요청에 응답하여 통신 프로세스에서 수동적인 역할을 유지합니다.
다음은 추가 읽기 자료입니다.
사용자 전환
작업 코드를 작성하기 전에 먼저 hadoop 사용자로 전환해야 합니다. 데스크톱에서 Xfce 터미널을 두 번 클릭하여 열고 다음 명령을 입력하십시오. hadoop 사용자의 비밀번호는 hadoop입니다. 사용자 전환 시 필요합니다.
su - hadoop
labex:~/ $ su - hadoop
hadoop:~$
팁: hadoop 사용자의 비밀번호는 hadoop입니다.
HDFS 초기화
HDFS 를 처음 사용하기 전에 NameNode 를 초기화해야 합니다. 이 작업은 디스크를 포맷하는 것과 비교할 수 있으므로 HDFS 에 데이터를 저장할 때는 이 명령을 주의해서 사용하십시오.
그렇지 않으면 이 섹션에서 실험을 다시 시작하십시오. "기본 환경"을 사용하고 다음 명령으로 HDFS 를 초기화하십시오.
/home/hadoop/hadoop/bin/hdfs namenode -format
팁: 위의 명령은 HDFS 파일 시스템을 포맷합니다. 명령을 실행하기 전에 HDFS 데이터 디렉토리를 삭제해야 합니다.
따라서 Hadoop 관련 서비스를 중지하고 Hadoop 데이터를 삭제해야 합니다.
stop-all.sh
rm -rf ~/hadoopdata
다음 메시지가 표시되면 초기화가 완료된 것입니다.
2024-03-01 11:16:10,439 INFO common.Storage: Storage directory /home/hadoop/hadoopdata/hdfs/namenode has been successfully formatted.
파일 가져오기
HDFS 는 로컬 디스크를 기반으로 구축된 계층화된 분산 저장 시스템이므로 HDFS 를 사용하기 전에 데이터를 가져와야 합니다.
일부 파일을 준비하는 첫 번째이자 가장 편리한 방법은 Hadoop 의 구성 파일을 예시로 사용하는 것입니다.
먼저 HDFS 데몬을 시작해야 합니다.
/home/hadoop/hadoop/sbin/start-dfs.sh
서비스 보기:
hadoop:~$ jps
8341 SecondaryNameNode
7962 NameNode
8474 Jps
8107 DataNode
터미널에 다음 명령을 입력하여 디렉토리를 생성하고 데이터를 복사합니다.
cd /home/hadoop
mkdir sample_data
cp -r /home/hadoop/hadoop/etc/hadoop/* sample_data/
디렉토리 내용 나열:
hadoop:~$ ls /home/hadoop/sample_data/
capacity-scheduler.xml kms-log4j.properties
configuration.xsl kms-site.xml
...
HDFS에 대한 모든 작업은 hdfs dfs로 시작하며 해당 작업 매개변수로 보완됩니다. 가장 일반적으로 사용되는 매개변수는 put이며 다음과 같이 사용되며 터미널에 입력할 수 있습니다.
/home/hadoop/hadoop/bin/hdfs dfs -put /home/hadoop/sample_data/hadoop-policy.xml /policy.xml
디렉토리 내용 나열:
hadoop:~$ hdfs dfs -ls /policy.xml
-rw-r--r-- 1 hadoop supergroup 11765 2024-03-01 11:37 /policy.xml
명령의 마지막 /policy.xml은 HDFS 에 저장된 파일 이름이 policy.xml이고 경로는 / (루트 디렉토리) 임을 의미합니다. 이전 파일 이름을 계속 사용하려면 경로 /를 직접 지정할 수 있습니다.
여러 파일을 업로드해야 하는 경우 로컬 디렉토리의 파일 경로를 연속적으로 지정하고 HDFS 대상 저장 경로로 끝낼 수 있습니다.
/home/hadoop/hadoop/bin/hdfs dfs -mkdir -p /user/hadoop
/home/hadoop/hadoop/bin/hdfs dfs -put /home/hadoop/sample_data/httpfs-env.sh /home/hadoop/sample_data/mapred-env.sh /user/hadoop
디렉토리 내용 나열:
hadoop:~$ hdfs dfs -ls /user/hadoop
Found 2 items
-rw-r--r-- 1 hadoop supergroup 1484 2024-03-01 11:42 /user/hadoop/httpfs-env.sh
-rw-r--r-- 1 hadoop supergroup 1764 2024-03-01 11:42 /user/hadoop/mapred-env.sh
경로 관련 매개변수를 지정하는 규칙은 Linux 시스템의 규칙과 동일합니다. 와일드카드 (예: *.sh) 를 사용하여 작업을 단순화할 수 있습니다.
파일 작업
마찬가지로 -ls 매개변수를 사용하여 지정된 디렉토리의 파일을 나열할 수 있습니다.
/home/hadoop/hadoop/bin/hdfs dfs -ls /user/hadoop
여기에 나열된 파일은 실험 환경에 따라 다를 수 있습니다.
파일의 내용을 보려면 cat 매개변수를 사용할 수 있습니다. 가장 쉽게 생각할 수 있는 것은 HDFS 에서 파일 경로를 직접 지정하는 것입니다. 로컬 디렉토리를 HDFS 상의 파일과 비교해야 하는 경우 해당 경로를 별도로 지정할 수 있습니다. 그러나 로컬 디렉토리는 file:// 표시자로 시작해야 하며 파일 경로 (예: /home/hadoop/.bashrc, 앞에 /를 잊지 마세요) 로 보완해야 합니다. 그렇지 않으면 여기에 지정된 모든 경로는 기본적으로 HDFS 의 경로로 인식됩니다.
/home/hadoop/hadoop/bin/hdfs dfs -cat file:///home/hadoop/.bashrc /user/hadoop/mapred-env.sh
출력은 다음과 같습니다.
hadoop:~$ hdfs dfs -cat file:///home/hadoop/.bashrc /user/hadoop/mapred-env.sh
## ~/.bashrc: executed by bash(1) for non-login shells.
## see /usr/share/doc/bash/examples/startup-files (in the package bash-doc)
## for examples
## If not running interactively, don't do anything
case $- in
...
파일을 다른 경로로 복사해야 하는 경우 cp 매개변수를 사용할 수 있습니다.
/home/hadoop/hadoop/bin/hdfs dfs -cp /user/hadoop/mapred-env.sh /user/hadoop/copied_file.txt
마찬가지로 파일을 이동해야 하는 경우 mv 매개변수를 사용합니다. 이것은 기본적으로 Linux 파일 시스템 명령 형식과 동일합니다.
/home/hadoop/hadoop/bin/hdfs dfs -mv /user/hadoop/mapred-env.sh /moved_file.txt
lsr 매개변수를 사용하여 하위 디렉토리의 내용을 포함하여 현재 디렉토리의 내용을 나열합니다. 출력은 다음과 같습니다.
hdfs dfs -lsr /
HDFS 의 파일에 새로운 내용을 추가하려면 appendToFile 매개변수를 사용할 수 있습니다. 또한 추가할 로컬 파일 경로를 지정할 때 여러 개를 지정할 수 있습니다. 마지막 매개변수는 추가할 객체가 됩니다. 파일은 HDFS 에 존재해야 하며, 그렇지 않으면 오류가 보고됩니다.
echo 1 >> a.txt
echo 2 >> b.txt
/home/hadoop/hadoop/bin/hdfs dfs -appendToFile a.txt b.txt /user/hadoop/mapred-env.sh
tail 매개변수를 사용하여 파일 꼬리 (파일의 끝 부분) 의 내용을 확인하여 추가가 성공했는지 확인할 수 있습니다.
/home/hadoop/hadoop/bin/hdfs dfs -tail /user/hadoop/mapred-env.sh
tail 명령의 출력을 봅니다.
hadoop:~$ echo 1 >> a.txt
echo 2 >> b.txt
hdfs dfs -appendToFile a.txt b.txt /user/hadoop/mapred-env.sh
hadoop:~$ hdfs dfs -tail /user/hadoop/mapred-env.sh
1
2
파일 또는 디렉토리를 삭제해야 하는 경우 rm 매개변수를 사용합니다. 이 매개변수는 Linux 파일 시스템 명령 rm과 동일한 의미를 갖는 -r 및 -f와 함께 사용할 수도 있습니다.
/home/hadoop/hadoop/bin/hdfs dfs -rm /moved_file.txt
moved_file.txt 파일의 내용이 삭제되고 명령은 'Deleted /moved_file.txt' 출력을 반환합니다.
디렉토리 작업
이전 내용에서 HDFS 에서 디렉토리를 생성하는 방법을 배웠습니다. 실제로 여러 디렉토리를 한 번에 생성해야 하는 경우 여러 디렉토리의 경로를 매개변수로 직접 지정할 수 있습니다. -p 매개변수는 상위 디렉토리가 존재하지 않는 경우 자동으로 생성됨을 나타냅니다.
/home/hadoop/hadoop/bin/hdfs dfs -mkdir -p /user/hadoop/dir1 /user/hadoop/dir2/sub_dir1
특정 파일 또는 디렉토리가 얼마나 많은 공간을 차지하는지 확인하려면 du 매개변수를 사용할 수 있습니다.
/home/hadoop/hadoop/bin/hdfs dfs -du /user/hadoop/
출력은 다음과 같습니다.
hadoop:~$ hdfs dfs -du /user/hadoop/
1764 1764 /user/hadoop/copied_file.txt
0 0 /user/hadoop/dir1
0 0 /user/hadoop/dir2
1484 1484 /user/hadoop/httpfs-env.sh
4 4 /user/hadoop/mapred-env.sh
파일 내보내기
이전 섹션에서는 주로 HDFS 의 파일 및 디렉토리 작업을 소개했습니다. MapReduce 와 같은 애플리케이션이 계산되고 결과가 기록된 파일이 생성되면 get 매개변수를 사용하여 Linux 시스템의 로컬 디렉토리로 내보낼 수 있습니다.
여기서 첫 번째 경로 매개변수는 HDFS 의 경로를 나타내고 마지막 경로는 로컬 디렉토리에 저장된 경로를 나타냅니다.
/home/hadoop/hadoop/bin/hdfs dfs -get /user/hadoop/mapred-env.sh /home/hadoop/exported_file.txt
내보내기가 성공하면 로컬 디렉토리에서 파일을 찾을 수 있습니다.
cd ~
ls
출력은 다음과 같습니다.
a.txt b.txt exported_file.txt hadoop hadoopdata sample_data
Hadoop 웹 운영
웹 관리 인터페이스
각 NameNode 또는 DataNode 는 클러스터의 현재 상태와 같은 기본 정보를 표시하는 웹 서버를 내부적으로 실행합니다. 기본 구성에서 NameNode 의 홈 페이지는 http://localhost:9870/입니다. DataNode 및 클러스터에 대한 기본 통계를 나열합니다.
웹 브라우저를 열고 주소 표시줄에 다음을 입력합니다.
http://localhost:9870/
Summary에서 현재 "클러스터"의 활성 DataNode 노드 수를 확인할 수 있습니다.
웹 인터페이스는 HDFS 내부의 디렉토리 및 파일을 탐색하는 데에도 사용할 수 있습니다. 상단 메뉴 모음에서 "Utilities" 아래의 "Browse the file system" 링크를 클릭합니다.
Hadoop 클러스터 종료
이제 WebHDFS 의 몇 가지 기본 작업에 대한 소개를 마쳤습니다. 더 많은 지침은 WebHDFS 설명서에서 찾을 수 있습니다. 이 랩은 종료되었습니다. 습관적으로 Hadoop 클러스터를 종료해야 합니다.
/home/hadoop/hadoop/sbin/stop-yarn.sh
/home/hadoop/hadoop/sbin/stop-dfs.sh
hadoop:~$ jps
11633 Jps
요약
이 랩에서는 HDFS 의 아키텍처를 소개했습니다. 또한, 명령줄에서 기본적인 HDFS 작업 명령을 배우고 HDFS 웹 접근 패턴으로 전환하여 HDFS 가 외부 애플리케이션을 위한 실제 스토리지 서비스로 작동하도록 했습니다.
이 랩에서는 WebHDFS 에서 파일을 삭제하는 시나리오는 나열하지 않았습니다. 직접 문서를 확인하실 수 있습니다. 더 많은 기능은 공식 문서에 숨겨져 있으므로 문서를 읽는 데 관심을 가지십시오.
다음은 추가 읽기 자료입니다.


