
소개
Docker 의 본질은 LXC 를 사용하여 가상 머신과 유사한 기능을 달성하여 하드웨어 리소스를 절약하고 사용자에게 더 많은 컴퓨팅 리소스를 제공하는 것입니다. 이 프로젝트는 C++ 와 Linux 의 Namespace 및 Control Group 기술을 결합하여 간단한 Docker 컨테이너를 구현합니다.
결과적으로, 우리는 컨테이너에 대해 다음과 같은 기능을 달성할 것입니다:
- 독립적인 파일 시스템
- 네트워크 접근 지원
👀 미리보기
$ make
make container
make[1]: Entering directory '/home/labex/project'
gcc -c network.c nl.c
g++ -std=c++11 -o docker-run main.cpp network.o nl.o
make[1]: Leaving directory '/home/labex/project'
$ sudo ./docker-run
...start container
root@labex:/## ifconfig
eth0 Link encap:Ethernet HWaddr 00:16:3e:da:01:72
inet6 addr: fe80::dc15:18ff:fe43:53b9/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:38 errors:0 dropped:0 overruns:0 frame:0
TX packets:9 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:5744 (5.7 KB) TX bytes:726 (726.0 B)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
🎯 과제
이 프로젝트에서 다음을 배우게 됩니다:
- C++ 와 Linux 의 Namespace 기술을 사용하여 간단한 Docker 컨테이너를 만드는 방법
- 컨테이너를 위한 독립적인 파일 시스템을 구현하는 방법
- 컨테이너의 네트워크 접근을 활성화하는 방법
🏆 성과
이 프로젝트를 완료하면 다음을 수행할 수 있습니다:
- C++ 와 Linux 의 Namespace 기술을 사용하여 간단한 Docker 컨테이너를 만들 수 있습니다.
- 컨테이너를 위한 독립적인 파일 시스템을 구현할 수 있습니다.
- 컨테이너의 네트워크 접근을 활성화할 수 있습니다.
Linux 네임스페이스 기술
C++ 에서 우리는 namespace 키워드에 익숙합니다. C++ 에서 각 네임스페이스는 서로 다른 코드에서 동일한 이름을 격리합니다. 따라서 네임스페이스의 이름이 다르면 네임스페이스 내 코드의 이름이 동일할 수 있으므로 코드에서 이름 충돌 문제를 해결합니다.
반면에 Linux Namespace 는 Linux 커널에서 제공하는 기술로, C++ 의 namespace 개념과 유사하게 애플리케이션에 대한 리소스 격리 솔루션을 제공합니다. PID, IPC 및 네트워킹과 같은 리소스는 운영 체제 자체에서 관리해야 한다는 것을 알고 있지만, Linux Namespace 는 이러한 리소스가 더 이상 전역적이지 않도록 하고 특정 네임스페이스에 할당할 수 있습니다.
Docker 기술 세계에서 우리는 LXC 및 OS 수준 가상화와 같은 용어를 자주 듣습니다. LXC 는 Namespace 기술을 활용하여 서로 다른 컨테이너 간의 리소스 격리를 달성합니다. Namespace 기술을 활용함으로써 서로 다른 컨테이너 내의 프로세스는 서로 다른 네임스페이스에 속하며 서로 간섭하지 않습니다. 요약하면, Namespace 기술은 다양한 관점에서 시스템 전체 속성을 조작할 수 있게 해주는 가벼운 형태의 가상화를 제공합니다.
Linux 에서 Namespace 와 관련된 가장 중요한 시스템 호출은 clone()입니다. clone()의 목적은 프로세스를 생성할 때 스레드를 특정 네임스페이스로 제한하는 것입니다.
시스템 콜 캡슐화
Linux 시스템 호출은 C 로 작성되었으므로, 프로젝트를 위해 C++ 코드를 작성해야 합니다. 순수하게 C++ 스타일을 유지하기 위해 먼저 이러한 필수 API 를 C++ 형태로 캡슐화할 것입니다. 이를 통해 이러한 API 가 어떻게 사용되는지 더 깊이 이해할 수 있습니다.
다음 API 를 사용할 것입니다:
clone()
clone과 fork 시스템 호출은 모두 Linux 에서 프로세스를 생성하는 데 사용됩니다. 그러나 fork는 clone의 작은 부분일 뿐입니다. 둘의 차이점은 fork는 부모 프로세스의 정확한 복사본인 자식 프로세스만 생성하는 반면, clone은 부모 프로세스 리소스를 자식 프로세스에 선택적으로 복사할 수 있다는 점에서 더 강력하다는 것입니다. 복사되지 않은 리소스는 포인터 복사 (arg) 를 통해 프로세스 간에 공유됩니다. 복사할 특정 리소스는 flags를 사용하여 지정할 수 있으며, 함수는 자식 프로세스의 PID 를 반환합니다.
우리는 프로세스가 네 가지 주요 요소로 구성되어 있다는 것을 알고 있습니다:
- 실행할 코드 세그먼트
- 프로세스에 대한 개인 스택 공간
- 프로세스 제어 블록 (PCB)
- 프로세스별 네임스페이스
처음 두 요소는 clone의 fn 및 child_stack 매개변수에 해당합니다. 프로세스 제어 블록은 커널에 의해 제어되며 이에 대해 걱정할 필요가 없습니다. 따라서 네임스페이스는 flags 매개변수와 관련됩니다. Docker 컨테이너를 생성하려는 목표를 달성하기 위해 필요한 주요 매개변수는 다음과 같습니다:
네임스페이스 분류 시스템 호출 매개변수
UTS CLONE_NEWUTS
Mount CLONE_NEWNS
PID CLONE_NEWPID
Network CLONE_NEWNET
이름에서 알 수 있듯이 CLONE_NEWNS는 파일 시스템 관련 마운팅을 복사 및 파일 시스템 관련 리소스에 제공하고, CLONE_NEWUTS는 호스트 이름을 설정하는 기능을 제공하며, CLONE_NEWPID는 독립적인 프로세스 공간 지원을 제공하고, CLONE_NEWNET는 네트워크 관련 지원을 제공합니다.
execv()
int execv(const char *path, char *const argv[]);
execv는 path로 지정된 실행 파일을 실행합니다. 이 시스템 호출을 통해 자식 프로세스는 컨테이너를 실행 상태로 유지하기 위해 /bin/bash를 실행할 수 있습니다.
sethostname()
int sethostname(const char *name, size_t len);
이름에서 알 수 있듯이 이 시스템 호출은 호스트 이름을 설정하는 데 사용됩니다. C 스타일 문자열은 포인터를 사용하고 문자열의 길이를 내부에서 직접 결정할 수 없으므로 len 매개변수를 사용하여 문자열의 길이를 얻는다는 점에 유의해야 합니다.
chdir()
int chdir(const char *path);
우리는 모든 프로그램이 특정 디렉토리에서 실행된다는 것을 알고 있습니다. 리소스에 액세스해야 할 때 절대 경로 대신 상대 경로를 사용하여 관련 리소스에 액세스할 수 있습니다. chdir은 프로그램의 작업 디렉토리를 변경하는 편의성을 제공하며, 특정 공개되지 않은 목적으로 사용할 수 있습니다.
chroot()
이 시스템 호출은 루트 디렉토리를 변경하는 데 사용됩니다:
int chroot(const char *path);
mount()
이 시스템 호출은 mount 명령과 유사하게 파일 시스템을 마운트하는 데 사용됩니다.
int mount(const char *source, const char *target,
const char *filesystemtype, unsigned long mountflags,
const void *data);
컨테이너 서브 프로세스 생성
~/project 디렉토리에 들어가서 docker.hpp라는 파일을 만듭니다. 이 파일에서 먼저 외부 코드에서 호출할 수 있는 docker 네임스페이스를 생성합니다.
//
// docker.hpp
// cpp_docker
//
// 시스템 호출을 위한 헤더 파일
#include <sys/wait.h> // waitpid
#include <sys/mount.h> // mount
#include <fcntl.h> // open
#include <unistd.h> // execv, sethostname, chroot, fchdir
#include <sched.h> // clone
// C 표준 라이브러리
#include <cstring>
// C++ 표준 라이브러리
#include <string> // std::string
#define STACK_SIZE (512 * 512) // 자식 프로세스 공간의 크기를 정의합니다.
namespace docker {
// .. docker 마법이 시작되는 곳
}
가독성을 높이기 위해 몇 가지 변수를 정의해 보겠습니다:
// `docker` 네임스페이스 내에서 정의됨
typedef int proc_status;
proc_status proc_err = -1;
proc_status proc_exit = 0;
proc_status proc_wait = 1;
컨테이너 클래스를 정의하기 전에 컨테이너를 생성하는 데 필요한 매개변수를 분석해 보겠습니다. 지금은 네트워크 관련 구성을 고려하지 않겠습니다. 이미지에서 Docker 컨테이너를 생성하려면 호스트 이름과 이미지 위치만 지정하면 됩니다. 따라서:
// Docker 컨테이너 시작 구성
typedef struct container_config {
std::string host_name; // 호스트 이름
std::string root_dir; // 컨테이너의 루트 디렉토리
} container_config;
이제 container 클래스를 정의하고 생성자에서 컨테이너에 필요한 구성을 수행하도록 하겠습니다:
class container {
private:
// 가독성 향상
typedef int process_pid;
// 자식 프로세스 스택
char child_stack[STACK_SIZE];
// 컨테이너 구성
container_config config;
public:
container(container_config &config) {
this->config = config;
}
};
container 클래스의 특정 메서드에 대해 생각하기 전에 먼저 이 container 클래스를 어떻게 사용할지 생각해 보겠습니다. 이를 위해 ~/project 폴더에 main.cpp 파일을 생성해 보겠습니다:
//
// main.cpp
// cpp_docker
//
#include "docker.hpp"
#include <iostream>
int main(int argc, char** argv) {
std::cout << "...start container" << std::endl;
docker::container_config config;
// 컨테이너 구성
// ...
docker::container container(config);// config 를 기반으로 컨테이너 구성
container.start(); // 컨테이너 시작
std::cout << "stop container..." << std::endl;
return 0;
}
main.cpp에서 컨테이너 시작을 간결하고 이해하기 쉽게 만들기 위해 start() 메서드를 사용하여 컨테이너를 시작한다고 가정해 보겠습니다. 이는 나중에 docker.hpp 파일을 작성하기 위한 기반을 제공합니다.
이제 docker.hpp로 돌아가서 start() 메서드를 구현해 보겠습니다:
void start() {
auto setup = [](void *args) -> int {
auto _this = reinterpret_cast<container *>(args);
// 컨테이너에 대한 관련 구성 수행
// ...
return proc_wait;
};
process_pid child_pid = clone(setup, child_stack+STACK_SIZE, // 스택의 맨 아래로 이동
SIGCHLD, // 자식 프로세스가 종료되면 부모 프로세스에 신호 전송
this);
waitpid(child_pid, nullptr, 0); // 자식 프로세스가 종료될 때까지 대기
}
docker::container::start() 메서드는 Linux 에서 clone() 시스템 호출을 사용합니다. docker::container 인스턴스 객체를 콜백 함수 setup에 전달하기 위해 clone()의 네 번째 인수를 사용하여 전달할 수 있습니다. 여기서는 this 포인터를 전달합니다.
setup 함수의 경우 람다 표현식을 생성합니다. C++ 에서 빈 캡처 목록이 있는 람다 표현식은 함수 포인터로 전달될 수 있습니다. 따라서 setup은 clone()에 전달된 콜백 함수가 됩니다.
람다 표현식 대신 클래스에 정의된 정적 멤버 함수를 사용할 수도 있지만, 그러면 코드가 덜 우아해집니다.
이 container 클래스의 생성자에서 clone() 시스템 호출에 의해 호출될 자식 프로세스 처리 함수를 정의합니다. typedef를 사용하여 이 함수의 반환 유형을 proc_status로 변경합니다. 이 함수가 proc_wait를 반환하면 clone()에 의해 복제된 자식 프로세스는 종료될 때까지 대기합니다.
그러나 프로세스 내에서 어떤 구성도 수행하지 않았으므로 이것으로는 충분하지 않습니다. 결과적으로 프로세스가 시작되면 다른 할 일이 없으므로 프로그램이 즉시 종료됩니다. 우리가 알고 있듯이 Docker 에서 컨테이너를 실행 상태로 유지하려면 다음을 사용할 수 있습니다:
docker run -it ubuntu:14.04 /bin/bash
이는 STDIN 을 컨테이너의 /bin/bash에 바인딩합니다. 따라서 start_bash() 메서드를 docker::container 클래스에 추가해 보겠습니다:
private:
void start_bash() {
// C++ std::string 을 C 스타일 문자열 char *로 안전하게 변환
// C++14 부터 이 직접 할당은 금지됩니다: `char *str = "test";`
std::string bash = "/bin/bash";
char *c_bash = new char[bash.length()+1]; // '\0'을 위해 +1
strcpy(c_bash, bash.c_str());
char* const child_args[] = { c_bash, NULL };
execv(child_args[0], child_args); // 자식 프로세스에서 /bin/bash 실행
delete []c_bash;
}
그리고 setup 내에서 호출합니다:
auto setup = [](void *args) -> int {
auto _this = reinterpret_cast<container *>(args);
_this->start_bash();
return proc_wait;
}
이제 다음 작업을 볼 수 있습니다:
labex:project/ $ hostname
iZj6cboigynrxh4mn2oo16Z
labex:project/ $ g++ main.cpp -std=c++11
labex:project/ $ ./a.out
...start container
labex@iZj6cboigynrxh4mn2oo16Z:~/project$ mkdir test
labex@iZj6cboigynrxh4mn2oo16Z:~/project$ ls
a.out docker.hpp main.cpp test
labex@iZj6cboigynrxh4mn2oo16Z:~/project$ exit
exit
stop container...
위 단계에서 먼저 현재 hostname을 확인하고, 지금까지 작성한 코드를 컴파일하고, 실행하고, 컨테이너에 들어갑니다. 컨테이너에 들어간 후 bash 프롬프트가 변경되는 것을 볼 수 있는데, 이는 우리가 예상했던 것입니다.
그러나 이것이 우리가 원하는 결과가 아니라는 것을 쉽게 알 수 있습니다. 이는 호스트 시스템과 정확히 동일합니다. 이 "컨테이너" 내에서 수행된 모든 작업은 호스트 시스템에 직접적인 영향을 미칩니다.
이것이 clone API 에 필요한 네임스페이스를 도입하는 곳입니다.
컨테이너 자체 호스트 이름 설정
앞서 시스템 호출 섹션에서 언급했듯이, 시스템 호출을 사용하여 자식 프로세스의 호스트 이름을 설정하는 것은 매우 간단합니다. 따라서 docker::container 클래스에 대한 private 메서드를 생성합니다:
private:
// 컨테이너의 호스트 이름 설정
void set_hostname() {
sethostname(this->config.host_name.c_str(), this->config.host_name.length());
}
또한 start() 메서드를 다음과 같이 변경합니다:
void start() {
auto setup = [](void *args) -> int {
auto _this = reinterpret_cast<container *>(args);
// 컨테이너 구성
_this->set_hostname();
_this->start_bash();
return proc_wait;
};
process_pid child_pid = clone(setup, child_stack+STACK_SIZE,
CLONE_NEWUTS| // UTS 네임스페이스 추가
SIGCHLD, // 자식 프로세스가 종료되면 부모에게 신호 전송
this);
waitpid(child_pid, nullptr, 0); // 자식 프로세스가 종료될 때까지 대기
}
main.cpp 파일에서 호스트 이름의 이름을 구성합니다:
int main(int argc, char** argv) {
std::cout << "...start container" << std::endl;
docker::container_config config;
config.host_name = "labex";
……
이제 코드를 다시 컴파일해 보겠습니다:
labex:project/ $ g++ main.cpp -std=c++11
labex:project/ $ ./a.out
...start container
stop container...
컨테이너가 즉시 종료되는 것을 관찰할 수 있습니다. 이는 네임스페이스를 도입하면 프로그램에 슈퍼유저 권한이 필요하기 때문입니다. 따라서 sudo를 사용하여 프로그램을 실행해야 합니다:
labex:project/ $ sudo ./a.out
...start container
root@labex:/home/labex/project## hostname
labex
root@labex:/home/labex/project## exit
exit
stop container...
labex:project/ $ hostname
iZj6cboigynrxh4mn2oo16Z
그러나 ls 명령에서 볼 수 있듯이 호스트 머신의 디렉토리에 여전히 액세스할 수 있으므로, 이것은 여전히 컨테이너의 원하는 효과를 얻지 못합니다.
컨테이너 자체 파일 시스템 활성화
Docker 기술에서 컨테이너는 이미지를 기반으로 생성됩니다. 컨테이너를 구현하려는 것이므로 이미지를 기반으로 생성해야 하는 것은 당연합니다. 다행히 여러분을 위해 Docker 이미지를 준비했습니다. 다음에서 다운로드하여 얻을 수 있습니다:
cd ~/project
wget --header="User-Agent: Mozilla/5.0" https://file.labex.io/lab/171925/docker-image.tar
그런 다음, ~/project/labex 폴더에 압축을 풉니다:
mkdir labex
tar -xf docker-image.tar --directory labex/
rm docker-image.tar
여기서 몇 가지 압축 해제 오류가 발생할 수 있습니다. 이는 환경에서 일부 파일의 외부 생성이 금지되어 있기 때문입니다. 이는 자체 컨테이너 구현에 영향을 미치지 않으므로 무시하십시오.
tar: dev/agpgart: Cannot mknod: Operation not permitted
tar: dev/audio: Cannot mknod: Operation not permitted
tar: dev/audio1: Cannot mknod: Operation not permitted
tar: dev/audio2: Cannot mknod: Operation not permitted
tar: dev/audio3: Cannot mknod: Operation not permitted
tar: dev/audioctl: Cannot mknod: Operation not permitted
……
압축 해제가 완료되면 labex 아래에서 거의 완전한 Linux 디렉토리를 볼 수 있습니다:
labex:project/ $ ls labex
bin boot dev etc home lib lib64 media mnt opt proc root run sbin srv sys tmp usr var
이제 docker::container가 이 디렉토리에 들어가서 이를 루트 디렉토리로 사용하고 시작 시 서브 프로세스의 외부 액세스를 마스킹하려고 합니다:
private:
// 루트 디렉토리 설정
void set_rootdir() {
// chdir 시스템 호출, 특정 디렉토리로 전환
chdir(this->config.root_dir.c_str());
// chroot 시스템 호출, 루트 디렉토리 설정, 이미
// 현재 디렉토리로 전환했으므로
// 현재 디렉토리를 루트 디렉토리로 간단히 사용할 수 있습니다.
chroot(".");
}
그런 다음 main.cpp에서 관련 구성을 채웁니다:
#include "docker.hpp"
#include <iostream>
int main(int argc, char** argv) {
std::cout << "...start container" << std::endl;
docker::container_config config;
config.host_name = "labex";
config.root_dir = "./labex";
……
그리고 Mount Namespace 를 활성화하기 위해 clone() 호출에서 CLONE_NEWNS를 활성화합니다:
void start() {
auto setup = [](void *args) -> int {
auto _this = reinterpret_cast<container *>(args);
_this->set_hostname();
_this->set_rootdir();
_this->start_bash();
return proc_wait;
};
process_pid child_pid = clone(setup, child_stack+STACK_SIZE,
CLONE_NEWUTS| // UTS 네임스페이스
CLONE_NEWNS| // Mount 네임스페이스
SIGCHLD, // 자식 프로세스가 종료되면 신호가 부모 프로세스로 전송됨
this);
waitpid(child_pid, nullptr, 0); // 자식 프로세스가 종료될 때까지 대기
}
이제 다시 컴파일해 보겠습니다:
labex:project/ $ g++ main.cpp -std=c++11
labex:project/ $ sudo ./a.out
...start container
root@labex:/## ls
bin boot dev etc home lib lib64 media mnt opt proc root run sbin srv sys tmp usr var
root@labex:/## hostname
labex
ls를 실행하면 자식 프로세스가 이제 완전한 linux 디렉토리에 있음을 확인할 수 있습니다.
컨테이너 자체 프로세스 시스템 활성화
하지만 여전히 문제가 있습니다. ps 또는 top과 같은 명령을 사용하면 여전히 부모 프로세스의 모든 프로세스를 관찰할 수 있습니다. 이것은 원하는 효과가 아닙니다. 예를 들어, ps의 출력에서 a.out을 볼 수 있으며, 프로세스 ID 값도 매우 큽니다.
이 문제를 해결하려면 자식 프로세스의 PID 공간을 부모 프로세스와 격리하기 위해 PID 네임스페이스를 도입해야 합니다.
private:
// 독립적인 프로세스 네임스페이스 설정
void set_procsys() {
// proc 파일 시스템 마운트
mount("none", "/proc", "proc", 0, nullptr);
mount("none", "/sys", "sysfs", 0, nullptr);
}
마찬가지로, start()에서 이 코드 부분을 추가하고 CLONE_NEWPID를 도입해야 합니다:
void start() {
auto setup = [](void *args) -> int {
auto _this = reinterpret_cast<container *>(args);
_this->set_hostname();
_this->set_rootdir();
_this->set_procsys();
_this->start_bash();
return proc_wait;
};
process_pid child_pid = clone(setup, child_stack,
CLONE_NEWUTS| // UTS 네임스페이스
CLONE_NEWNS| // Mount 네임스페이스
CLONE_NEWPID| // PID 네임스페이스
SIGCHLD, // 자식 프로세스가 종료되면 신호가 부모 프로세스로 전송됨
this);
waitpid(child_pid, nullptr, 0); // 자식 프로세스가 종료될 때까지 대기
}
이제 다시 컴파일하고 실행하면 컨테이너가 자체 독립적인 프로세스 공간을 갖는 것을 볼 수 있습니다:
이 시점에서 Linux 의 네임스페이스 기술을 사용하여 자식 프로세스의 리소스를 격리하고 Docker 컨테이너에 자체 프로세스 공간과 파일 시스템을 제공했습니다.
그러나 컨테이너는 여전히 네트워크에 액세스할 수 없으며, ifconfig를 사용하여 호스트 머신의 네트워크 장치에 액세스할 수도 있습니다. 이것은 우리가 원하는 것이 아닙니다. 다음으로, 컨테이너를 더욱 향상시켜 완전한 컨테이너처럼 보이게 하고 네트워크 액세스에 대한 지원을 제공할 것입니다.
Docker 네트워킹 원리
이전에는 Docker 가 어떻게 닫힌 컨테이너를 구현하는지에 대한 예비적인 이해를 했습니다. 그러나 우리가 구현한 Docker 컨테이너가 네트워크 액세스를 지원하지 않으며, 우리가 실행하는 서로 다른 컨테이너가 서로 통신할 수 있는 능력을 갖는 것이 불가능하다는 것도 발견했습니다.
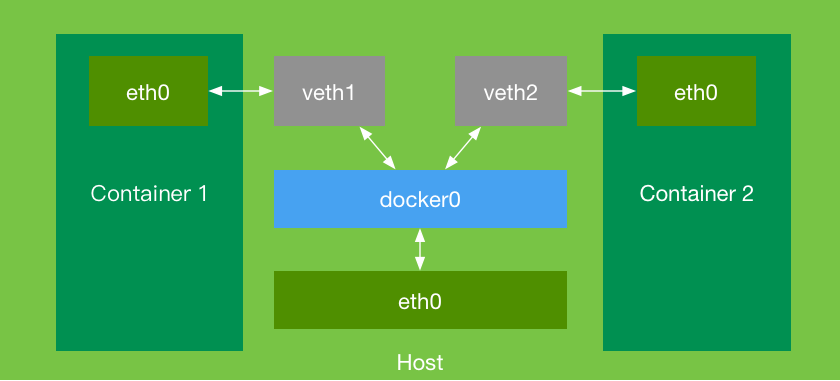
Docker 컨테이너 간의 네트워크 통신의 원리는 'docker0'이라는 브리지를 통해 달성됩니다. 'container1'과 'container2'라는 두 컨테이너는 각각 자체 네트워크 장치인 'eth0'을 가지고 있습니다. 모든 네트워크 요청은 'eth0'을 통해 전달됩니다. 컨테이너는 자식 프로세스에서 실행되므로, 'eth0' 인터페이스 간의 통신을 활성화하려면 'veth1'과 'veth2'라는 한 쌍의 네트워크 장치를 생성하여 'docker0' 브리지에 추가해야 합니다. 이를 통해 브리지는 컨테이너 내의 'eth0' 인터페이스에서 생성된 네트워크 요청을 무조건 전달하고 라우팅하여 컨테이너 간의 통신을 가능하게 합니다.
따라서 우리가 작성하는 컨테이너가 네트워크 통신 기능을 갖도록 하려면 먼저 사용할 수 있는 브리지를 생성해야 합니다. 편의상 환경에 있는 기존 'docker0'을 직접 사용하겠습니다.
네트워크 생성 준비
네트워크를 조작하기 위해 네이티브 Linux API 를 사용하는 것은 매우 복잡한 작업이며, 많은 C 언어 연산도 포함합니다. C++ 를 사용하여 코딩하는 데 더 집중하기 위해, 네트워크를 더 편리하게 조작할 수 있도록 이미 구현된 몇 가지 "바퀴"가 있습니다.
/tmp디렉토리에 들어가면network.h,nl.h,network.c,nl.c의 네 개의 파일을 제공했습니다.
이 네 개의 파일을 ~/project 디렉토리로 복사합니다:
cp /tmp/network.h /tmp/nl.h /tmp/network.c /tmp/nl.c ~/project/
마지막 세 파일의 코드는 LXC 툴셋에서 가져온 것입니다. 그러나 이 코드는 C 언어로 작성되었습니다. C++11 부터 C++ 와 C 는 더 이상 서로 호환되지 않으므로, C++ 가 이 코드를 원활하게 호출할 수 있도록 하려면 C/C++ 혼합 프로그래밍에 대한 약간의 지식이 있어야 합니다.
먼저, 소스 코드를 실행 파일로 변환하는 작업이 직접 수행되는 것이 아니라, 전처리, 컴파일, 어셈블리, 링크의 여러 단계를 거쳐 수행된다는 것을 알고 있습니다. 일반적으로 g++ main.cpp 단계를 사용하여 위의 모든 단계를 한 번에 완료합니다.
그러나 프로젝트가 커지고 소스 파일 수가 증가하면 사소한 변경만으로 전체 프로젝트를 다시 컴파일하는 것은 비용 효율적이지 않습니다. 이 시점에서 먼저 코드를 .o 파일로 컴파일한 다음 링크 작업을 진행할 수 있습니다. 이를 통해 C 언어로 컴파일된 링크 파일과 C++ 관련 소스 코드를 동시에 컴파일할 수도 있습니다.
C++ 와 C 는 서로 다른 컴파일 및 처리 방식을 가지고 있으므로, C 언어 코드를 컴파일하려는 경우 __cplusplus 매크로와 extern "C"를 사용해야 합니다.
network.h에는 network.c의 관련 인터페이스 선언이 저장되어 있습니다. 다음 주석 처리된 부분을 주석 처리하면:
// #ifdef __cplusplus
// extern "C"
// {
// #endif
#include <sys/types.h>
int netdev_set_flag(const char *name, int flag);
……
void new_hwaddr(char *hwaddr);
// #ifdef __cplusplus
// }
// #endif
gcc를 사용하여 직접 .o 파일로 컴파일합니다:
gcc -c network.c nl.c
그리고 다음 코드를 사용합니다:
// test.cpp
#include "network.h"
int main() {
new_hwaddr(nullptr);
return 0;
}
컴파일하고 테스트하려면:
g++ test.cpp network.o nl.o -std=c++11
컴파일에 실패하고 undefined reference to 'new_hwaddr(char*)' 오류가 발생합니다.
/usr/bin/ld: /tmp/ccz4DEEy.o: in function `main':
test.cpp:(.text+0xe): undefined reference to `new_hwaddr(char*)'
collect2: error: ld returned 1 exit status
다시 말해:
C 라이브러리를 C++ 로 컴파일하고 링크하려면 인터페이스의 관련 선언을 래핑해야 합니다:
#ifdef __cplusplus
extern "C"
{
#endif
// C interface functions
#ifdef __cplusplus
}
#endif
이때, network.c와 nl.c를 다시 .o 파일로 컴파일한 다음 *.o를 test.cpp와 함께 컴파일하여 성공적으로 컴파일합니다.
컨테이너 네트워크 생성
이전 Docker 의 네트워크 원리에 대한 섹션을 기반으로, 우리가 생성하는 컨테이너가 네트워크를 지원하도록 하기 위한 다음 단계를 요약할 수 있습니다:
- 가상 네트워크 장치 veth1/veth2 한 쌍을 생성합니다;
- veth1 의 MAC 주소를 설정합니다;
- veth1 을 브리지 labex0 에 추가합니다;
- veth1 을 활성화합니다;
- 자식 프로세스를 생성합니다;
- veth2 를 자식 프로세스의 네트워크 네임스페이스로 이동하고 이름을 eth0 으로 변경합니다;
- 자식 프로세스가 완료될 때까지 기다립니다;
- 네트워크 장치 veth1 및 veth2 를 삭제합니다;
따라서 start() 로직을 더 최적화해야 합니다.
먼저, 네트워크 관련 구성을 docker::container_config에 추가해야 합니다:
헤더 파일을 포함합니다:
#include <net/if.h> // if_nametoindex
#include <arpa/inet.h> // inet_pton
#include "network.h"
docker::container_config 구성을 추가합니다:
// Docker 컨테이너 시작 구성
typedef struct container_config {
std::string host_name; // 호스트 이름
std::string root_dir; // 컨테이너 루트 디렉토리
std::string ip; // 컨테이너 IP
std::string bridge_name; // 브리지 이름
std::string bridge_ip; // 브리지 IP
} container_config;
그런 다음, 컨테이너 IP, 추가할 브리지 이름 docker0, 그리고 main.cpp에서 브리지의 IP 를 설정합니다:
int main(int argc, char** argv) {
std::cout << "...start container" << std::endl;
docker::container_config config;
config.host_name = "labex";
config.root_dir = "./labex";
// 네트워크 매개변수 구성
config.ip = "192.168.0.100"; // 컨테이너 IP
config.bridge_name = "docker0"; // 호스트 브리지
config.bridge_ip = "192.168.0.1"; // 호스트 브리지 IP
docker::container container(config);
container.start();
std::cout << "stop container..." << std::endl;
return 0;
}
위의 네트워크 장치 로직을 기반으로 start() 메서드를 리팩토링해 보겠습니다:
private:
// 삭제를 위해 컨테이너 네트워크 장치 저장
char *veth1;
char *veth2;
public:
void start() {
char veth1buf[IFNAMSIZ] = "labex0X";
char veth2buf[IFNAMSIZ] = "labex0X";
// 네트워크 장치 한 쌍을 생성합니다. 하나는 호스트에 로드되고 다른 하나는 자식 프로세스의 컨테이너로 이동합니다.
veth1 = lxc_mkifname(veth1buf); // lxc_mkifname API 는 가상 네트워크 장치 이름에 최소한 하나의 "X"를 추가하여 가상 네트워크 장치의 임의 생성을 지원해야 합니다.
veth2 = lxc_mkifname(veth2buf); // 이는 네트워크 장치의 올바른 생성을 보장하기 위한 것입니다. 자세한 내용은 network.c 에서 lxc_mkifname 의 구현을 참조하십시오.
lxc_veth_create(veth1, veth2);
// veth1 의 MAC 주소를 설정합니다.
setup_private_host_hw_addr(veth1);
// veth1 을 브리지에 추가합니다.
lxc_bridge_attach(config.bridge_name.c_str(), veth1);
// veth1 을 활성화합니다.
lxc_netdev_up(veth1);
// 컨테이너 생성 전 몇 가지 구성 작업
auto setup = [](void *args) -> int {
auto _this = reinterpret_cast<container *>(args);
_this->set_hostname();
_this->set_rootdir();
_this->set_procsys();
// 컨테이너 내부의 네트워크 구성
// ...
_this->start_bash();
return proc_wait;
};
// clone 을 사용하여 컨테이너를 생성합니다.
process_pid child_pid = clone(setup, child_stack,
CLONE_NEWUTS| // UTS 네임스페이스
CLONE_NEWNS| // 마운트 네임스페이스
CLONE_NEWPID| // PID 네임스페이스
CLONE_NEWNET| // Net 네임스페이스
SIGCHLD, // 자식 프로세스가 종료될 때 부모 프로세스에 신호를 보냅니다.
this);
// veth2 를 컨테이너로 이동하고 eth0 으로 이름을 변경합니다.
lxc_netdev_move_by_name(veth2, child_pid, "eth0");
waitpid(child_pid, nullptr, 0); // 자식 프로세스가 종료될 때까지 기다립니다.
}
~container() {
// 종료 시 생성된 가상 네트워크 장치를 삭제하는 것을 잊지 마십시오.
lxc_netdev_delete_by_name(veth1);
lxc_netdev_delete_by_name(veth2);
}
참고:
clone에CLONE_NEWNET을 추가합니다.
위의 단계에서 볼 수 있듯이, 네트워크 장치를 생성한 후 자식 프로세스를 생성하는 동안 외부 네트워크 장치와 협력하여 컨테이너 내부에서 관련 구성을 수행해야 합니다:
- 컨테이너 내부에서
lo장치를 활성화합니다; eth0의 IP 주소를 구성합니다;eth0을 활성화합니다;- 게이트웨이를 설정합니다;
eth0의 MAC 주소를 설정합니다;
private:
void set_network() {
int ifindex = if_nametoindex("eth0");
struct in_addr ipv4;
struct in_addr bcast;
struct in_addr gateway;
// IP 주소를 점 표기법과 이진법 사이에서 변환하는 IP 주소 변환 함수
inet_pton(AF_INET, this->config.ip.c_str(), &ipv4);
inet_pton(AF_INET, "255.255.255.0", &bcast);
inet_pton(AF_INET, this->config.bridge_ip.c_str(), &gateway);
// eth0 의 IP 주소를 구성합니다.
lxc_ipv4_addr_add(ifindex, &ipv4, &bcast, 16);
// lo 를 활성화합니다.
lxc_netdev_up("lo");
// eth0 을 활성화합니다.
lxc_netdev_up("eth0");
// 게이트웨이를 설정합니다.
lxc_ipv4_gateway_add(ifindex, &gateway);
// eth0 의 MAC 주소를 설정합니다.
char mac[18];
new_hwaddr(mac);
setup_hw_addr(mac, "eth0");
}
그런 다음, 컨테이너의 setup에서 이 메서드를 호출합니다:
……
_this->set_procsys();
_this->set_network(); // 컨테이너 내부의 네트워크 구성을 위한 협력
_this->start_bash();
return proc_wait;
이 시점에서, network.o 및 nl.o 컴파일된 링크 파일을 사용하기 시작했으므로, 매우 간단한 Makefile을 작성해 보겠습니다:
C = gcc
CXX = g++
C_LIB = network.c nl.c
C_LINK = network.o nl.o
MAIN = main.cpp
LD = -std=c++11
OUT = docker-run
all:
make container
container:
$(C) -c $(C_LIB)
$(CXX) $(LD) -o $(OUT) $(MAIN) $(C_LINK)
clean:
rm *.o $(OUT)
참고: Makefile 의 명령은 공백 대신 탭으로 시작해야 합니다. 이는 Markdown 인터프리터가 탭을 네 개의 공백으로 변환하기 때문입니다. Makefile 을 작성할 때는 네 개의 공백 대신 탭을 사용해야 합니다. 그렇지 않으면 Makefile 이 "Makefile:10: *** missing separator. Stop." 오류를 표시합니다.
다시 컴파일하고 실행하여 컨테이너에 들어가면 ifconfig를 사용하여 네트워크를 확인할 수 있습니다:
labex:project/ $ make
make container
make[1]: Entering directory '/home/labex/project'
gcc -c network.c nl.c
g++ -std=c++11 -o docker-run main.cpp network.o nl.o
make[1]: Leaving directory '/home/labex/project'
labex:project/ $ sudo ./docker-run
...start container
root@labex:/## ifconfig
eth0 Link encap:Ethernet HWaddr 00:16:3e:da:01:72
inet6 addr: fe80::dc15:18ff:fe43:53b9/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:38 errors:0 dropped:0 overruns:0 frame:0
TX packets:9 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:5744 (5.7 KB) TX bytes:726 (726.0 B)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
요약
이 프로젝트를 통해 우리는 점차적으로 다음을 달성했습니다: 파일 시스템을 컨테이너에 통합하고, 외부 네트워크에 대한 접근을 가능하게 했습니다.
기본적인 Docker 컨테이너를 성공적으로 생성했습니다. 이 컨테이너를 더 최적화하여 보다 현실적인 에뮬레이션을 구현할 수 있습니다.


