
Introducción
En este laboratorio, aprenderás los fundamentos de la construcción de un modelo de aprendizaje automático utilizando una de las bibliotecas de Python más populares: scikit-learn. Nos centraremos en la Regresión Lineal, un algoritmo básico pero potente que se utiliza para predecir valores continuos, como un precio o una temperatura.
Nuestro objetivo es construir un modelo capaz de predecir los precios medios de la vivienda en los distritos de California. Utilizaremos el conjunto de datos de vivienda de California, que viene incluido de forma práctica en scikit-learn.
A lo largo de este laboratorio, aprenderás a:
- Cargar un conjunto de datos desde
scikit-learn. - Preparar y dividir los datos para el entrenamiento y la prueba.
- Crear y entrenar un modelo de Regresión Lineal.
- Utilizar el modelo entrenado para realizar predicciones.
- Visualizar los resultados para comprender el rendimiento del modelo.
Realizarás todas las tareas dentro del WebIDE. ¡Comencemos!
Cargar el conjunto de datos de vivienda de California con datasets.fetch_california_housing()
En este paso, comenzaremos cargando el conjunto de datos para nuestro modelo. scikit-learn incluye varios conjuntos de datos integrados, los cuales son excelentes para el aprendizaje y la práctica. Utilizaremos el conjunto de datos de vivienda de California.
Primero, necesitamos crear un script de Python. Ya se ha creado un archivo llamado main.py para ti en el directorio ~/project. Puedes encontrarlo en el explorador de archivos en el lado izquierdo del WebIDE.
Abre main.py y añade el siguiente código. Este código importa las bibliotecas necesarias (fetch_california_housing de sklearn.datasets y pandas) y carga el conjunto de datos. Usaremos pandas para convertir los datos en un DataFrame, que es una estructura de datos tabular fácil de visualizar y manipular.
Por favor, añade el siguiente código a main.py:
import pandas as pd
from sklearn.datasets import fetch_california_housing
## Load the California housing dataset
california = fetch_california_housing()
## Create a DataFrame
california_df = pd.DataFrame(california.data, columns=california.feature_names)
california_df['MedHouseVal'] = california.target
## Print the first 5 rows of the DataFrame
print("California Housing Dataset:")
print(california_df.head())
Ahora, ejecutemos el script para ver el resultado. Abre una terminal en el WebIDE (puedes usar el menú "Terminal" -> "New Terminal") y ejecuta el siguiente comando:
python3 main.py
Deberías ver las primeras cinco filas del conjunto de datos impresas en la consola. La columna MedHouseVal es nuestra variable objetivo, que representa el valor medio de la vivienda para los distritos de California, expresado en cientos de miles de dólares ($100,000).
California Housing Dataset:
MedInc HouseAge AveRooms AveBedrms Population AveOccup Latitude Longitude MedHouseVal
0 8.3252 41.0 6.984127 1.023810 322.0 2.555556 37.88 -122.23 4.526
1 8.3014 21.0 6.238137 0.971880 2401.0 2.109842 37.86 -122.22 3.585
2 7.2574 52.0 8.288136 1.073446 496.0 2.802260 37.85 -122.24 3.521
3 5.6431 52.0 5.817352 1.073059 558.0 2.547945 37.85 -122.25 3.413
4 3.8462 52.0 6.281853 1.081081 565.0 2.181467 37.85 -122.25 3.422
Dividir los datos en entrenamiento y prueba usando train_test_split de sklearn.model_selection
En este paso, prepararemos nuestros datos para el proceso de entrenamiento. Una parte crucial del aprendizaje automático es evaluar el modelo con datos que nunca antes ha visto. Para hacer esto, dividimos nuestro conjunto de datos en dos partes: un conjunto de entrenamiento y un conjunto de prueba. El modelo aprenderá del conjunto de entrenamiento y utilizaremos el conjunto de prueba para ver qué tan bien funciona.
Primero, necesitamos separar nuestras características (las variables de entrada, X) de nuestro objetivo (el valor que queremos predecir, y). En nuestro caso, X serán todas las columnas excepto MedHouseVal, y y será la columna MedHouseVal.
Luego, utilizaremos la función train_test_split de sklearn.model_selection para realizar la división.
Añade el siguiente código a tu archivo main.py.
from sklearn.model_selection import train_test_split
## Prepare the data
X = california_df.drop('MedHouseVal', axis=1) ## Features (input variables)
y = california_df['MedHouseVal'] ## Target variable (what we want to predict)
## Split the data into training and testing sets
## test_size=0.2: Reserve 20% of data for testing, 80% for training
## random_state=42: Ensures reproducible splits (same result every run)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
## Print the shapes of the new datasets to confirm the split
print("\n--- Data Split ---")
print("X_train shape:", X_train.shape) ## Training features
print("X_test shape:", X_test.shape) ## Test features
print("y_train shape:", y_train.shape) ## Training target values
print("y_test shape:", y_test.shape) ## Test target values
Ahora, ejecuta el script de nuevo desde la terminal:
python3 main.py
Verás las formas (shapes) de los conjuntos de entrenamiento y prueba recién creados impresas debajo del DataFrame. Esto confirma que los datos se han dividido correctamente.
--- Data Split ---
X_train shape: (16512, 8)
X_test shape: (4128, 8)
y_train shape: (16512,)
y_test shape: (4128,)
Inicializar el modelo LinearRegression de sklearn.linear_model
En este paso, crearemos nuestro modelo de Regresión Lineal. scikit-learn hace que esto sea increíblemente sencillo. Solo necesitamos importar la clase LinearRegression del módulo sklearn.linear_model y luego crear una instancia de ella.
Esta instancia es un objeto que contiene el algoritmo de regresión lineal. La regresión lineal encuentra la línea que mejor se ajusta a través de los puntos de datos, utilizando la fórmula: y = mx + b, donde m son los coeficientes (pesos) para cada característica, y b es la intersección. Aquí utilizamos los parámetros predeterminados, que funcionan bien para la mayoría de los casos básicos.
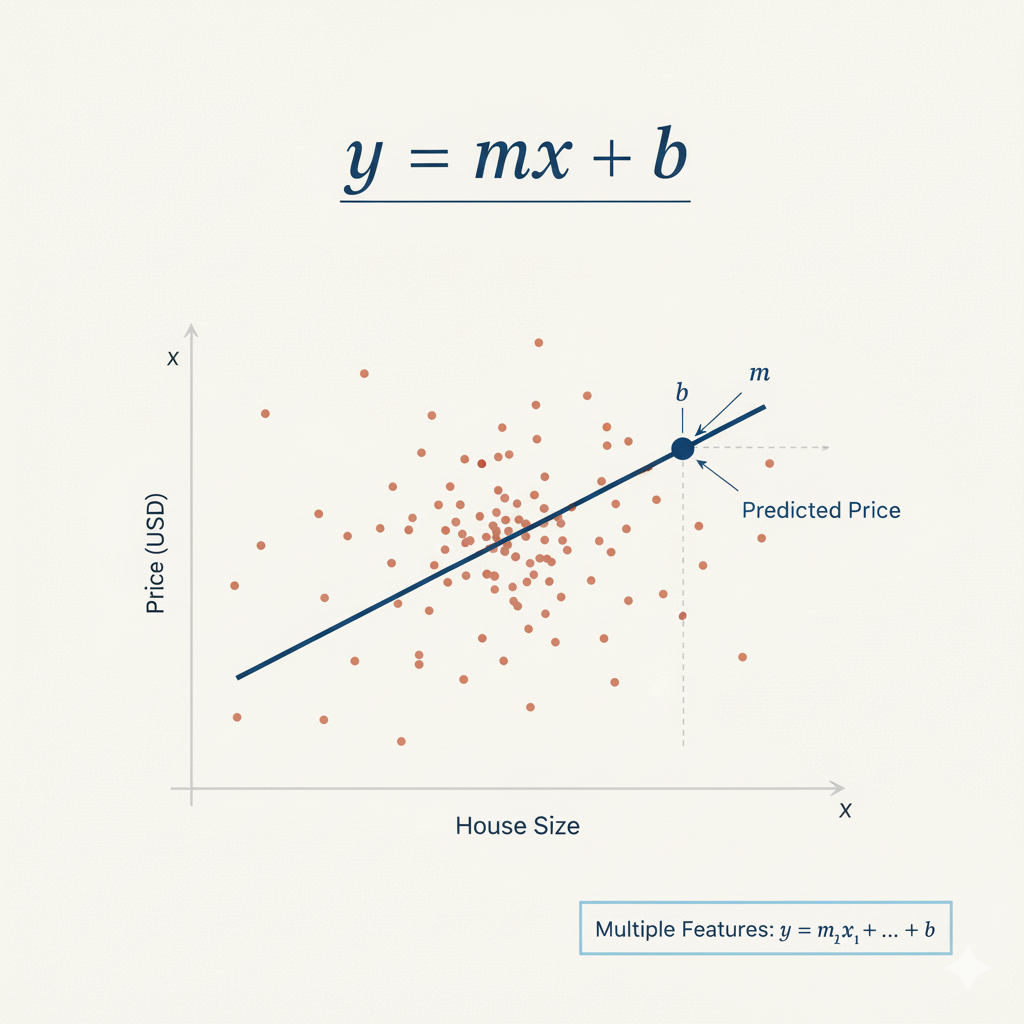 Figura 1: Fórmula de regresión lineal y = mx + b, donde m es la pendiente y b es la intersección
Figura 1: Fórmula de regresión lineal y = mx + b, donde m es la pendiente y b es la intersección
Añade el siguiente código a tu archivo main.py. Esto importará la clase LinearRegression y creará un objeto de modelo.
from sklearn.linear_model import LinearRegression
## Initialize the Linear Regression model
model = LinearRegression()
## Print the model to confirm it's created
print("\n--- Model Initialized ---")
print(model)
Ejecuta tu script main.py de nuevo desde la terminal:
python3 main.py
La salida ahora incluirá una línea que muestra el objeto LinearRegression. Esto confirma que el modelo se ha inicializado correctamente.
--- Model Initialized ---
LinearRegression()
Ajustar el modelo con model.fit(X_train, y_train)
En este paso, entrenaremos nuestro modelo. Este proceso a menudo se denomina "ajustar" (fitting) el modelo a los datos. Durante el ajuste, el modelo aprende las relaciones entre las características (X_train) y la variable objetivo (y_train). Para la regresión lineal, esto significa encontrar los coeficientes óptimos para cada característica para predecir mejor el objetivo.
Utilizaremos el método fit() de nuestro objeto de modelo, pasando nuestros datos de entrenamiento como argumentos.
Añade el siguiente código a tu archivo main.py.
## Fit (train) the model on the training data
## The fit() method learns the relationship between features (X_train) and target (y_train)
## It calculates optimal coefficients for each feature and the intercept using least squares optimization
model.fit(X_train, y_train)
## After fitting, the model has learned the coefficients and intercept.
## The intercept represents the predicted value when all features are zero
print("\n--- Model Trained ---")
print("Intercept:", model.intercept_)
Ahora, ejecuta el script desde la terminal:
python3 main.py
Después de que el script se ejecute, verás una nueva sección en la salida que muestra la intersección del modelo de regresión lineal. La intersección es el valor de la predicción cuando todos los valores de las características son cero. Ver un valor numérico aquí confirma que el modelo se ha entrenado correctamente con los datos.
--- Model Trained ---
Intercept: -37.023277706064185
Predecir con datos de prueba usando model.predict(X_test)
En este paso final, utilizaremos nuestro modelo entrenado para realizar predicciones. Este es el objetivo final de construir un modelo predictivo. Utilizaremos los datos de prueba (X_test), que el modelo no ha visto durante el entrenamiento, para evaluar su rendimiento.
Utilizaremos el método predict() de nuestro objeto de modelo entrenado, pasando las características de prueba (X_test) como argumento. El método devolverá una matriz de valores predichos para la variable objetivo.
Añade el siguiente código a tu archivo main.py.
## Make predictions on the test data
## The predict() method uses the learned coefficients and intercept to calculate predictions
## Formula: prediction = intercept + (coeff1 * feature1) + (coeff2 * feature2) + ...
predictions = model.predict(X_test)
## Print the first 5 predictions (values are in $100,000 units)
print("\n--- Predictions ---")
print(predictions[:5])
Ahora, ejecuta el script completo una última vez desde la terminal:
python3 main.py
La salida ahora incluirá los primeros cinco precios de vivienda predichos para el conjunto de prueba. Estos valores son lo que nuestro modelo considera que deberían ser los valores medios de la vivienda, basados en las características en X_test. Puedes comparar conceptualmente estas predicciones con los valores reales en y_test para medir la precisión del modelo.
--- Predictions ---
[0.71912284 1.76401657 2.70965883 2.83892593 2.60465725]
¡Felicidades! Has construido, entrenado y utilizado con éxito un modelo de regresión lineal con scikit-learn.
Visualizar las predicciones del modelo usando matplotlib.pyplot.scatter()
En este paso final, crearemos una visualización para comprender mejor el rendimiento de nuestro modelo. La visualización es crucial en el aprendizaje automático, ya que nos ayuda a ver patrones y relaciones que podrían no ser obvios a partir de números brutos.
Crearemos un gráfico de dispersión (scatter plot) que compare los precios reales de la vivienda (y_test) con las predicciones de nuestro modelo. Este tipo de gráfico se denomina gráfico de dispersión de "predicciones frente a valores reales". Si nuestro modelo fuera perfecto, todos los puntos estarían en una línea diagonal (línea de 45 grados) donde los valores predichos son iguales a los valores reales.
Utilizaremos matplotlib para crear esta visualización y guardarla como un archivo de imagen.
Añade el siguiente código a tu archivo main.py:
import matplotlib.pyplot as plt
## Create a scatter plot comparing actual vs predicted values
plt.figure(figsize=(10, 6))
plt.scatter(y_test, predictions, alpha=0.5, color='blue', edgecolors='black')
## Add a diagonal line showing perfect predictions (where predicted = actual)
plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()],
'r--', linewidth=2, label='Perfect Prediction')
## Add labels and title
plt.xlabel('Actual House Prices ($100,000)')
plt.ylabel('Predicted House Prices ($100,000)')
plt.title('Linear Regression: Actual vs Predicted House Prices')
plt.legend()
plt.grid(True, alpha=0.3)
## Save the plot to a file
plt.savefig('housing_predictions.png', dpi=300, bbox_inches='tight')
plt.close()
print("\n--- Visualization Complete ---")
print("Plot saved to housing_predictions.png")
Ahora, ejecuta el script completo desde la terminal:
python3 main.py
Verás un mensaje de confirmación de que el gráfico se ha guardado.
--- Visualization Complete ---
Plot saved to housing_predictions.png
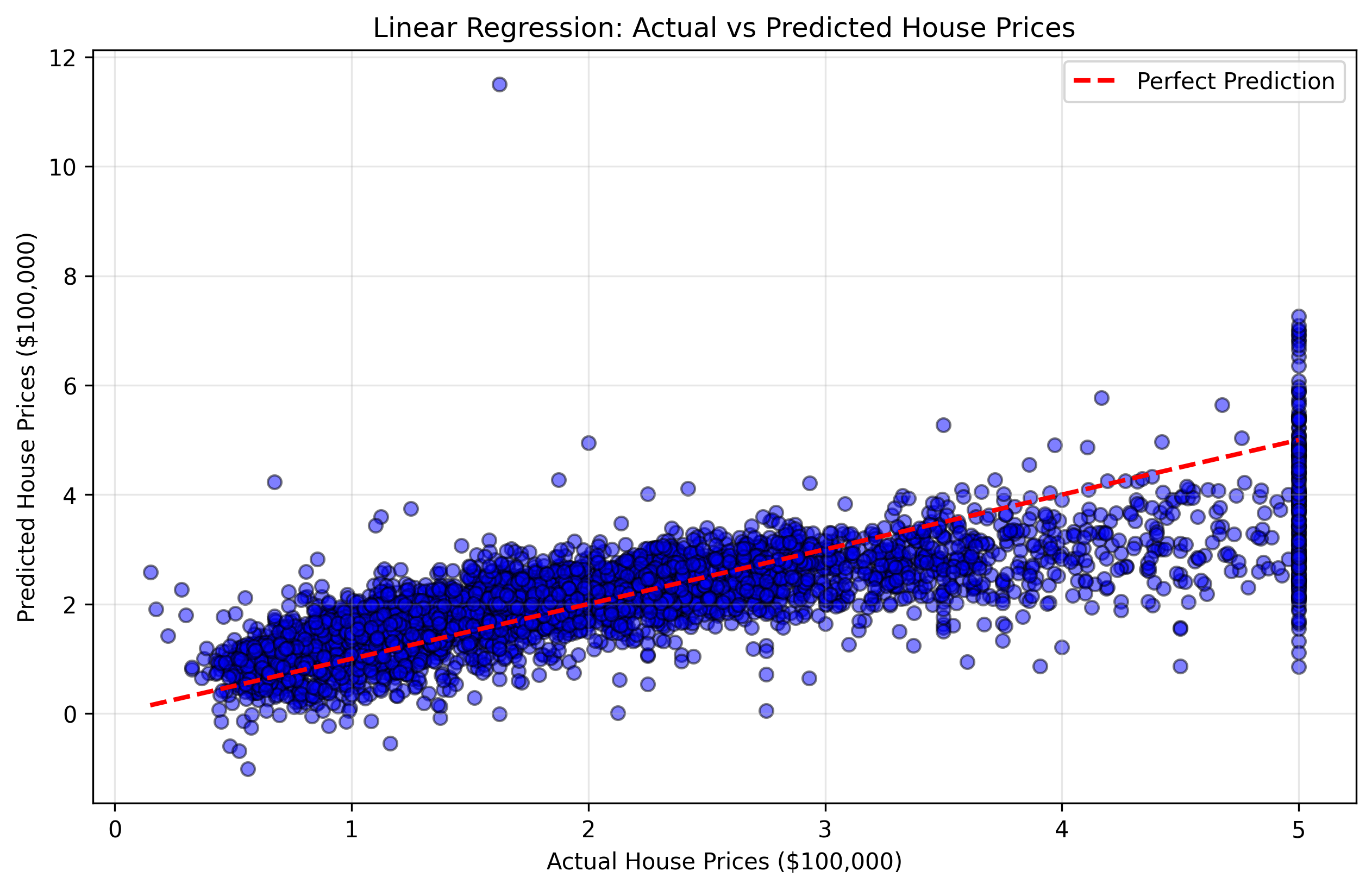 Figura 2: Gráfico de dispersión que muestra los precios reales frente a los predichos. Los puntos más cercanos a la línea diagonal roja indican mejores predicciones.
Figura 2: Gráfico de dispersión que muestra los precios reales frente a los predichos. Los puntos más cercanos a la línea diagonal roja indican mejores predicciones.
Esta visualización te ayudará a entender:
- Puntos cerca de la línea diagonal: Buenas predicciones donde el modelo fue preciso.
- Puntos lejos de la línea diagonal: Malas predicciones donde el modelo cometió errores mayores.
- Patrón general: Si el modelo tiende a sobreestimar o subestimar ciertos rangos de precios.
Puedes hacer doble clic en el archivo housing_predictions.png en el explorador de archivos para ver tu visualización.
¡Felicidades! Has construido, entrenado, probado y visualizado con éxito un modelo de regresión lineal con scikit-learn.
Resumen
En este laboratorio, has completado todo el flujo de trabajo para construir un modelo básico de aprendizaje automático utilizando scikit-learn.
Comenzaste cargando el conjunto de datos de vivienda de California y preparándolo usando pandas. Luego, aprendiste la importancia de dividir tus datos en conjuntos de entrenamiento y prueba, y realizaste la división usando train_test_split.
Posteriormente, inicializaste un modelo de LinearRegression, lo entrenaste con tus datos de entrenamiento usando el método fit(), utilizaste el modelo entrenado para realizar predicciones sobre datos de prueba no vistos con el método predict(), y finalmente visualizaste los resultados para comprender el rendimiento de tu modelo.
Este laboratorio proporciona una base sólida en scikit-learn. A partir de aquí, puedes explorar temas más avanzados como:
- Evaluación del modelo: Calcular métricas como el Error Cuadrático Medio (MSE) o R-cuadrado para medir la precisión del modelo.
- Visualización de datos: Crear gráficos más avanzados como gráficos de residuos, gráficos de importancia de características o matrices de correlación.
- Escalado de características: Estandarizar o normalizar características para un mejor rendimiento.
- Regularización: Usar regresión Ridge o Lasso para evitar el sobreajuste (overfitting).
- Validación cruzada: Evaluación más robusta usando validación cruzada k-fold.
- Otros algoritmos: Probar Random Forest, Support Vector Machines o Redes Neuronales.


