
Introducción
¡Bienvenido a este laboratorio práctico sobre clasificación K-Nearest Neighbors (KNN) utilizando scikit-learn! Scikit-learn es una biblioteca de Python potente y popular para el aprendizaje automático. El algoritmo KNN es uno de los algoritmos de clasificación más simples pero efectivos. Clasifica un nuevo punto de datos basándose en la clase mayoritaria de sus 'k' vecinos más cercanos en el espacio de características. En este laboratorio, recorrerá el proceso completo de construcción de un modelo de aprendizaje automático: cargar el famoso conjunto de datos Iris, dividirlo en conjuntos de entrenamiento y prueba, inicializar y entrenar un clasificador KNN, y finalmente, utilizar el modelo entrenado para hacer predicciones sobre datos nuevos y no vistos. Al final de este laboratorio, tendrá una comprensión sólida del flujo de trabajo fundamental para el aprendizaje supervisado en scikit-learn.
Cargar el conjunto de datos Iris con datasets.load_iris()
En este paso, comenzará cargando el conjunto de datos necesario. Utilizaremos el clásico conjunto de datos Iris, que está convenientemente incluido con scikit-learn. Primero, necesita importar el módulo datasets de sklearn. Luego, llamará a la función load_iris() para obtener los datos.
Comprendiendo load_iris():
- Tipo de retorno: Devuelve un objeto
Bunch(similar a un diccionario) que contiene:.data: Matriz de características (150 muestras × 4 características: longitud del sépalo, ancho del sépalo, longitud del pétalo, ancho del pétalo).target: Vector de etiquetas (especies: 0=setosa, 1=versicolor, 2=virginica).feature_names: Nombres de las 4 características.target_names: Nombres de las 3 especies
- Propósito: Proporciona un conjunto de datos limpio y listo para usar para la práctica de clasificación.
Asignaremos estos a las variables X y y, respectivamente, que es una convención común en el aprendizaje automático (X para características, y para etiquetas).
Abra el archivo main.py en el editor de la izquierda y agregue el siguiente código.
from sklearn import datasets
## Load the iris dataset
iris = datasets.load_iris()
## Assign features to X and labels to y
X = iris.data
y = iris.target
## You can print the shape to see the dimensions
print("Features shape:", X.shape)
print("Labels shape:", y.shape)
Ahora, ejecute el script desde la terminal para ver la salida.
python3 main.py
Debería ver las dimensiones de la matriz de características y el vector de etiquetas.
Features shape: (150, 4)
Labels shape: (150,)
Esto nos indica que tenemos 150 muestras (flores) y 4 características para cada muestra.
Dividir datos en entrenamiento y prueba usando train_test_split de sklearn.model_selection
En este paso, dividirá el conjunto de datos en dos partes: un conjunto de entrenamiento y un conjunto de prueba. Este es un paso crucial en el aprendizaje automático para evaluar el rendimiento de un modelo en datos no vistos.
Comprendiendo los parámetros de train_test_split():
test_size=0.3: Reserva el 30% de los datos para pruebas, el 70% para entrenamiento.random_state=42: Asegura divisiones reproducibles (la misma semilla aleatoria en cada ejecución).- Propósito: Previene el sobreajuste (overfitting) al evaluar el modelo en datos no vistos.
- Salida: Devuelve cuatro arrays: X_train, X_test, y_train, y_test.
Entrenamos el modelo con el conjunto de entrenamiento y luego probamos su poder predictivo con el conjunto de prueba. Scikit-learn proporciona una función útil llamada train_test_split para este propósito. Necesita importarla desde sklearn.model_selection.
Agregue el siguiente código al final de su archivo main.py.
from sklearn.model_selection import train_test_split
## Split data into training and testing sets
## test_size=0.3 means 30% of the data will be used for testing
## random_state ensures reproducibility
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
## Print the shapes of the new sets
print("X_train shape:", X_train.shape)
print("X_test shape:", X_test.shape)
Ahora, ejecute el script nuevamente.
python3 main.py
La salida ahora incluirá las dimensiones de sus conjuntos de entrenamiento y prueba.
Features shape: (150, 4)
Labels shape: (150,)
X_train shape: (105, 4)
X_test shape: (45, 4)
Inicializar KNeighborsClassifier con n_neighbors=3 de sklearn.neighbors
En este paso, inicializará el clasificador K-Nearest Neighbors (Vecinos Más Cercanos). La idea central de KNN es predecir la clase de un punto de datos observando las clases de sus 'k' vecinos más cercanos.
Comprendiendo los parámetros de KNeighborsClassifier():
n_neighbors=3: Número de vecinos más cercanos a considerar para la predicción.- Valores más pequeños (ej. 1-3): Más sensible al ruido, puede sobreajustarse (overfit).
- Valores más grandes (ej. 5-7): Límites de decisión más suaves, más robusto.
- Comportamiento del algoritmo: Para la predicción, encuentra los k puntos de entrenamiento más cercanos y utiliza votación mayoritaria.
- Sin fase de entrenamiento: KNN es un "aprendiz perezoso" (lazy learner): almacena los datos de entrenamiento y calcula durante la predicción.
KNeighborsClassifier es la clase en scikit-learn que implementa este algoritmo. Necesita importarla desde sklearn.neighbors. Creemos un objeto clasificador y llamémoslo clf.
Agregue el siguiente código al final de su archivo main.py.
from sklearn.neighbors import KNeighborsClassifier
## Initialize the KNN classifier with n_neighbors=3
clf = KNeighborsClassifier(n_neighbors=3)
Este código no produce ninguna salida, pero crea el objeto clasificador en memoria, listo para ser entrenado en el siguiente paso.
Ajustar el clasificador con clf.fit(X_train, y_train)
En este paso, entrenará, o 'ajustará' (fit), el clasificador utilizando sus datos de entrenamiento. Para el algoritmo KNN, la fase de 'entrenamiento' es muy simple: solo implica almacenar todo el conjunto de datos de entrenamiento (X_train y y_train).
Comprendiendo el método .fit():
- Parámetros de entrada:
X_train(matriz de características),y_train(etiquetas objetivo). - Qué hace: Almacena los datos de entrenamiento en memoria para su uso posterior durante la predicción.
- Especificidad de KNN: A diferencia de otros algoritmos, KNN no aprende parámetros durante el ajuste (fit).
- Propósito: Prepara el modelo para hacer predicciones sobre datos nuevos.
Cuando se requiere una predicción para un nuevo punto, el algoritmo encuentra los 'k' puntos más cercanos en este conjunto de datos almacenado y toma una decisión. Para entrenar el modelo en scikit-learn, utiliza el método .fit() del objeto clasificador. El método toma las características de entrenamiento (X_train) y las etiquetas de entrenamiento correspondientes (y_train) como argumentos.
Agregue la siguiente línea de código al final de main.py.
## Train the classifier using the training data
clf.fit(X_train, y_train)
print("Classifier trained successfully.")
Después de agregar el código, ejecute el script.
python3 main.py
Verá un mensaje de confirmación de que el clasificador ha sido entrenado.
Features shape: (150, 4)
Labels shape: (150,)
X_train shape: (105, 4)
X_test shape: (45, 4)
Classifier trained successfully.
Predecir clases con clf.predict(X_test)
En este paso final, utilizará el clasificador entrenado para hacer predicciones sobre los datos de prueba. Ahora que el modelo ha 'aprendido' de los datos de entrenamiento, podemos proporcionarle las características del conjunto de prueba (X_test), que nunca ha visto antes, y pedirle que prediga la clase para cada muestra.
Comprendiendo el método .predict():
- Parámetro de entrada:
X_test(matriz de características de datos no vistos). - Proceso del algoritmo: Para cada muestra de prueba, encuentra los k vecinos más cercanos en los datos de entrenamiento y utiliza votación mayoritaria.
- Salida: Matriz de etiquetas de clase predichas (misma longitud que las muestras de entrada).
- Métrica de distancia: Utiliza la distancia Euclidiana por defecto para medir la similitud entre puntos.
- Propósito: Evalúa el rendimiento del modelo en datos nuevos y no vistos.
Esto se realiza utilizando el método .predict(). El método toma las características de prueba (X_test) como entrada y devuelve una matriz de etiquetas predichas. Almacenaremos estas predicciones en una variable llamada predictions y las imprimiremos en la consola. También puede imprimir las etiquetas reales (y_test) para ver qué tan bien se desempeñó el modelo.
Agregue la última parte del código a su archivo main.py.
## Make predictions on the test data
predictions = clf.predict(X_test)
print("Predictions on test data:", predictions)
print("Actual labels of test data:", y_test)
Ahora, ejecute el script completo.
python3 main.py
Verá la matriz de etiquetas de clase predichas para el conjunto de prueba, seguida de la matriz de las etiquetas verdaderas.
... (previous output) ...
Classifier trained successfully.
Predictions on test data: [1 0 2 1 1 0 1 2 1 1 2 0 0 0 0 1 2 1 1 2 0 2 0 2 2 2 2 2 0 0 0 0 1 0 0 2 1
0 0 0 2 1 1 0 0]
Actual labels of test data: [1 0 2 1 1 0 1 2 1 1 2 0 0 0 0 1 2 1 1 2 0 2 0 2 2 2 2 2 0 0 0 0 1 0 0 2 1
0 0 0 2 1 1 0 0]
Nota: Las matrices de salida se muestran aquí en su totalidad. Al comparar las dos matrices, puede ver que las predicciones coinciden perfectamente con las etiquetas reales, lo que indica un excelente rendimiento del modelo en este conjunto de prueba.
Visualizar Resultados de Clasificación KNN
En este paso adicional, creará visualizaciones para comprender mejor sus resultados de clasificación KNN. La visualización le ayuda a ver qué tan bien funcionó su modelo y a comprender los límites de decisión creados por el algoritmo KNN.
Comprendiendo la visualización de datos en clasificación:
- Gráficos de dispersión (Scatter plots): Muestran las relaciones entre las características y cómo se distribuyen las clases.
- Codificación por colores: Diferentes colores representan diferentes clases (especies).
- Datos de entrenamiento vs. datos de prueba: Ayuda a comprender la generalización del modelo.
- Precisión de la predicción: Comparación visual de etiquetas predichas vs. reales.
Agregue el siguiente código al final de su archivo main.py para crear las visualizaciones:
import matplotlib.pyplot as plt
import numpy as np
## Create subplots for multiple visualizations
fig, axes = plt.subplots(1, 2, figsize=(15, 6))
## Plot 1: Training data with different colors for each class
scatter1 = axes[0].scatter(X_train[:, 0], X_train[:, 1], c=y_train, cmap='viridis', alpha=0.7, s=50)
axes[0].set_xlabel('Sepal Length (cm)')
axes[0].set_ylabel('Sepal Width (cm)')
axes[0].set_title('Training Data Distribution')
axes[0].legend(*scatter1.legend_elements(), title="Classes")
## Plot 2: Test data predictions vs actual labels
## Create a comparison: correct predictions vs incorrect ones
test_predictions = clf.predict(X_test)
correct_predictions = (test_predictions == y_test)
## Plot correct predictions
correct_mask = correct_predictions
scatter2_correct = axes[1].scatter(X_test[correct_mask, 0], X_test[correct_mask, 1],
c=y_test[correct_mask], cmap='viridis', alpha=0.7, s=50, marker='o')
## Plot incorrect predictions with different marker
incorrect_mask = ~correct_predictions
if np.any(incorrect_mask):
scatter2_incorrect = axes[1].scatter(X_test[incorrect_mask, 0], X_test[incorrect_mask, 1],
c=test_predictions[incorrect_mask], cmap='viridis',
alpha=0.7, s=80, marker='x', edgecolors='red', linewidths=2)
axes[1].set_xlabel('Sepal Length (cm)')
axes[1].set_ylabel('Sepal Width (cm)')
axes[1].set_title('Test Data: Predictions vs Actual\n(correct=●, incorrect=✕)')
## Create legend
legend_elements = [plt.Line2D([0], [0], marker='o', color='w', markerfacecolor='gray', markersize=8, label='Correct'),
plt.Line2D([0], [0], marker='x', color='red', markersize=8, label='Incorrect')]
axes[1].legend(handles=legend_elements)
plt.tight_layout()
plt.savefig('knn_classification_results.png', dpi=150, bbox_inches='tight')
print("Visualization saved to knn_classification_results.png")
## Additional: Show prediction accuracy
accuracy = np.mean(correct_predictions) * 100
print(f"Model Accuracy: {accuracy:.1f}%")
Ejecute el script actualizado:
python3 main.py
Debería ver una salida que incluya:
... (previous output) ...
Visualization saved to knn_classification_results.png
Model Accuracy: 100.0%
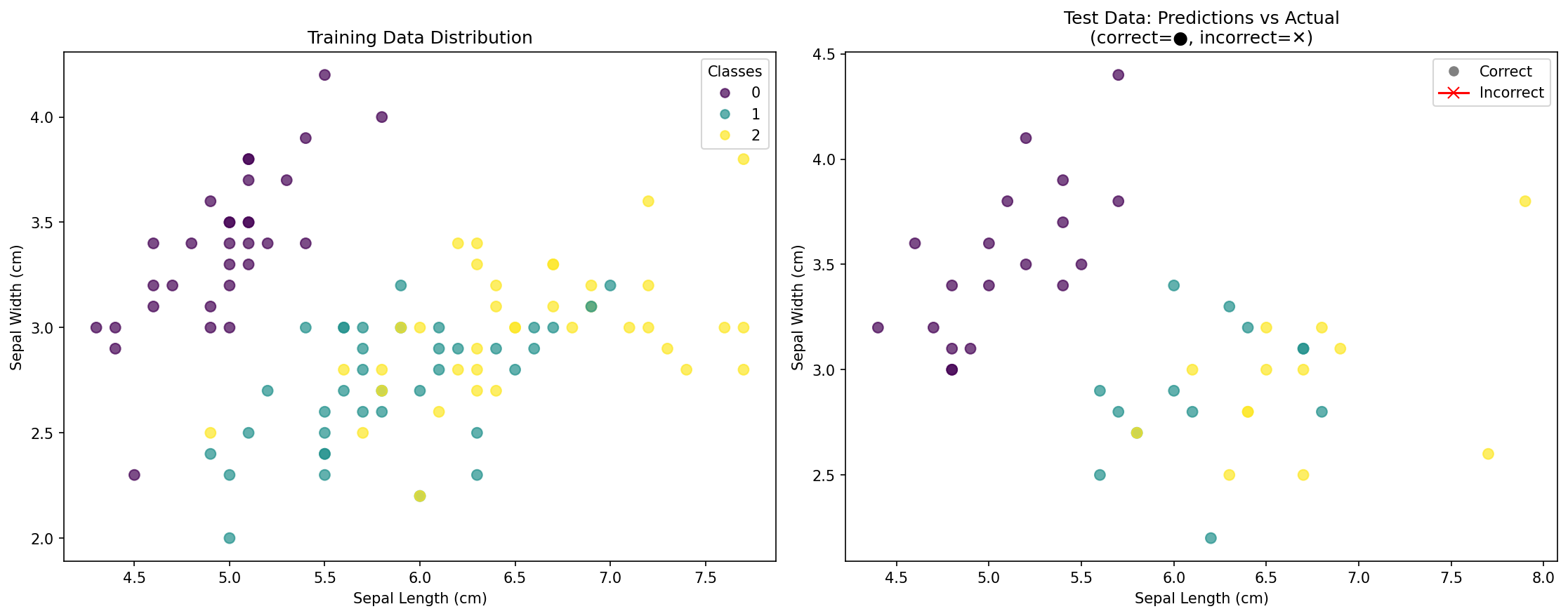
Lo que muestra la visualización:
- Gráfico izquierdo: Distribución de los puntos de datos de entrenamiento, coloreados según su especie real.
- Gráfico derecho: Puntos de datos de prueba que muestran:
- Círculos (●): Puntos clasificados correctamente.
- Cruces (✕): Puntos clasificados incorrectamente (si los hay).
- Puntuación de precisión: Porcentaje general de predicciones correctas.
Esta visualización le ayuda a comprender:
- Cómo se distribuyen las clases en el espacio de características.
- Si su modelo está sobreajustando (overfitting) o generalizando bien.
- Qué áreas pueden ser desafiantes para la clasificación.
- La efectividad de su modelo KNN visualmente.
Resumen
¡Felicitaciones por completar este laboratorio! Ha construido y entrenado con éxito un modelo de clasificación K-Nearest Neighbors (KNN) utilizando scikit-learn. Ha aprendido el flujo de trabajo fundamental de un proyecto de aprendizaje automático supervisado, que incluye:
- Cargar un conjunto de datos utilizando
sklearn.datasets. - Dividir los datos en conjuntos de entrenamiento y prueba con
train_test_split. - Inicializar un clasificador, en este caso,
KNeighborsClassifier. - Entrenar el modelo con los datos de entrenamiento utilizando el método
.fit(). - Realizar predicciones sobre datos nuevos y no vistos utilizando el método
.predict(). - Visualizar los resultados para comprender el rendimiento del modelo y los patrones de decisión.
Este proceso constituye la base para muchas tareas de aprendizaje automático. A partir de aquí, podría explorar cómo evaluar el rendimiento de su modelo de manera más formal utilizando métricas como la precisión (accuracy), la precisión (precision) y la exhaustividad (recall), o experimentar con diferentes valores para n_neighbors para ver cómo afectan el resultado. También podría intentar visualizar los límites de decisión o utilizar diferentes métricas de distancia en su clasificador KNN.


