
Introducción
¡Bienvenido al mundo del aprendizaje automático con scikit-learn! Uno de los primeros y más cruciales pasos en cualquier proyecto de aprendizaje automático es cargar y comprender tus datos. Scikit-learn, una biblioteca potente y fácil de usar para el aprendizaje automático en Python, proporciona varios conjuntos de datos integrados para ayudarte a empezar.
En este laboratorio, trabajarás con el famoso conjunto de datos de flores Iris. Aprenderás a cargar este conjunto de datos, inspeccionar su estructura, acceder a los datos de características y a las etiquetas objetivo, y finalmente, crear una visualización simple para obtener una primera impresión de la distribución de los datos. Este conocimiento fundamental es esencial para cualquier aspirante a científico de datos o ingeniero de aprendizaje automático.
Cargar el conjunto de datos Iris con datasets.load_iris()
En este paso, aprenderás a cargar uno de los conjuntos de datos integrados de scikit-learn. Utilizaremos la función load_iris() del módulo sklearn.datasets. Esta función devuelve un objeto "Bunch", que es similar a un diccionario de Python y contiene el conjunto de datos junto con sus metadatos.
Primero, abre el archivo main.py desde el explorador de archivos en el lado izquierdo de tu pantalla. Escribiremos todo nuestro código en este archivo.
Ahora, añade el siguiente código a main.py para importar el módulo necesario y cargar el conjunto de datos.
from sklearn import datasets
## Cargar el conjunto de datos Iris
iris = datasets.load_iris()
Este código importa el módulo datasets y llama a la función load_iris(), almacenando el objeto del conjunto de datos resultante en una variable llamada iris.
Para ejecutar tu script, abre una terminal en el WebIDE (puedes usar el menú "Terminal" -> "New Terminal") y ejecuta el siguiente comando. Tu directorio actual ya es ~/project.
python3 main.py
No verás ninguna salida, y eso es lo esperado. Hemos cargado los datos en la variable iris, pero aún no hemos pedido a nuestro script que imprima nada. En los siguientes pasos, exploraremos el contenido de este objeto iris.
Acceder al array de datos usando iris.data
En este paso, accederás al núcleo del conjunto de datos: los datos de características. El objeto iris que creamos contiene un atributo llamado data, que contiene un array de NumPy con las mediciones de cada flor. Cada fila representa una muestra (una flor), y cada columna representa una característica (una medición).
Modifiquemos el archivo main.py para imprimir este array de datos y ver cómo se ve.
Actualiza tu archivo main.py con el siguiente código:
from sklearn import datasets
## Cargar el conjunto de datos Iris
iris = datasets.load_iris()
## Imprimir el array de datos
print(iris.data)
Ahora, ejecuta el script de nuevo desde tu terminal:
python3 main.py
Deberías ver un gran array de números impreso en la terminal. Estos son los datos de características para las 150 muestras de flores del conjunto de datos. Cada muestra tiene 4 características.
[[5.1 3.5 1.4 0.2]
[4.9 3. 1.4 0.2]
[4.7 3.2 1.3 0.2]
...
[6.5 3. 5.2 2. ]
[6.2 3.4 5.4 2.3]
[5.9 3. 5.1 1.8]]
Acceder al array de destino usando iris.target
En este paso, accederás a las etiquetas de cada muestra en el conjunto de datos. En el aprendizaje automático supervisado, estas etiquetas se denominan "objetivo" (target). El objeto iris las almacena en el atributo target. Para el conjunto de datos Iris, los objetivos representan las especies de cada flor.
Las especies están codificadas como enteros: 0 para setosa, 1 para versicolor y 2 para virginica. El atributo iris.target es un array de NumPy que contiene el entero correspondiente para cada muestra en iris.data.
Modifiquemos main.py para imprimir el array objetivo.
from sklearn import datasets
## Cargar el conjunto de datos Iris
iris = datasets.load_iris()
## Imprimir el array objetivo
print(iris.target)
Ejecuta el script desde tu terminal:
python3 main.py
La salida será un array de 0s, 1s y 2s, que representan la especie de cada una de las 150 flores.
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]
Explorar nombres de características con iris.feature_names
En este paso, aprenderás a averiguar qué representan realmente las columnas en el array iris.data. Aunque sabemos que hay cuatro características, sus nombres no son inmediatamente obvios a partir del array de datos en sí. El objeto iris almacena convenientemente estos nombres en el atributo feature_names.
Esto es muy útil para comprender e interpretar tus datos. Modifiquemos main.py para imprimir estos nombres de características.
Actualiza tu archivo main.py:
from sklearn import datasets
## Cargar el conjunto de datos Iris
iris = datasets.load_iris()
## Imprimir los nombres de las características
print(iris.feature_names)
Ahora, ejecuta el script desde tu terminal:
python3 main.py
La salida será una lista de cadenas de texto, que te darán el nombre de cada una de las cuatro columnas en iris.data.
['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
Ahora sabes que las cuatro características corresponden a la longitud del sépalo, el ancho del sépalo, la longitud del pétalo y el ancho del pétalo, todas en centímetros.
Visualizar datos usando matplotlib.pyplot.scatter(iris.data[:, 0], iris.data[:, 1])
En este último paso, realizarás una visualización de datos simple para ver la relación entre dos de las características. La visualización es una parte clave de la exploración de datos. Utilizaremos la biblioteca matplotlib, una herramienta popular de trazado en Python, para crear un gráfico de dispersión (scatter plot).
Trazaremos la primera característica (longitud del sépalo) frente a la segunda característica (ancho del sépalo). Para seleccionar estas columnas de nuestros datos, usamos el slicing de NumPy:
iris.data[:, 0]selecciona todas las filas (:) y la primera columna (0).iris.data[:, 1]selecciona todas las filas (:) y la segunda columna (1).
En lugar de mostrar el gráfico en pantalla, lo cual no es ideal para este entorno, lo guardaremos en un archivo de imagen llamado iris_plot.png.
Actualiza tu archivo main.py con el siguiente código:
from sklearn import datasets
import matplotlib.pyplot as plt
## Cargar el conjunto de datos Iris
iris = datasets.load_iris()
## Trazaremos las dos primeras características: Longitud del Sépalo vs Ancho del Sépalo
X = iris.data[:, :2]
y = iris.target
plt.scatter(X[:, 0], X[:, 1])
plt.xlabel('Longitud del Sépalo (cm)')
plt.ylabel('Ancho del Sépalo (cm)')
plt.title('Longitud del Sépalo vs Ancho del Sépalo')
## Guardar el gráfico en un archivo
plt.savefig('iris_plot.png')
print("Plot saved to iris_plot.png")
Ejecuta el script desde tu terminal:
python3 main.py
Verás un mensaje de confirmación.
Plot saved to iris_plot.png
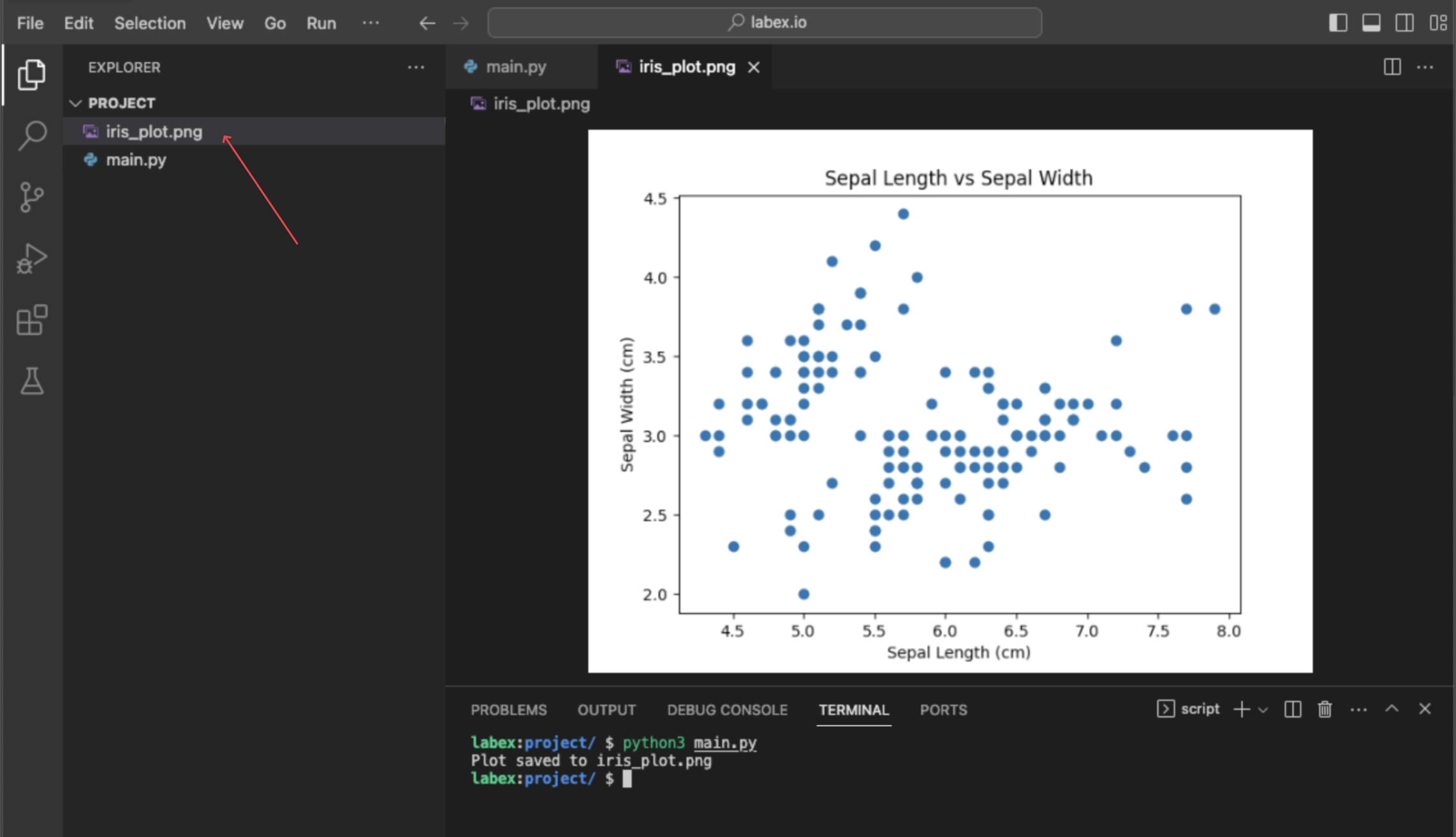
Este comando no mostrará un gráfico directamente, pero creará un nuevo archivo llamado iris_plot.png en tu directorio ~/project. Puedes hacer doble clic en este archivo en el explorador de archivos de la izquierda para ver tu gráfico de dispersión.
Resumen
¡Felicitaciones por completar este laboratorio! Has dado tus primeros pasos exitosos en el manejo de datos con scikit-learn.
En este laboratorio, aprendiste a:
- Cargar un conjunto de datos incorporado usando
sklearn.datasets.load_iris(). - Acceder a la matriz de características usando el atributo
.data. - Acceder a las etiquetas objetivo usando el atributo
.target. - Comprender el significado de las características inspeccionando el atributo
.feature_names. - Realizar una visualización de datos básica creando un gráfico de dispersión con
matplotliby guardándolo en un archivo.
Estas habilidades fundamentales son los pilares para tareas de aprendizaje automático más avanzadas. Ahora estás preparado para explorar otros conjuntos de datos y comenzar a construir tus propios modelos de aprendizaje automático.


