
Introducción
En este laboratorio, obtendrá experiencia práctica en la programación de tareas en sistemas RHEL utilizando diversas herramientas. Aprenderá a programar trabajos de una sola vez con el comando at, a gestionar tareas recurrentes específicas del usuario utilizando crontab, y a configurar trabajos recurrentes a nivel de sistema con los directorios cron.
Además, este laboratorio cubrirá técnicas avanzadas de programación utilizando los temporizadores systemd para una automatización de tareas más robusta y flexible, y demostrará cómo gestionar archivos temporales de manera eficiente con systemd-tmpfiles. Al final de este laboratorio, será competente en la elección del método de programación apropiado para diferentes escenarios y en la gestión efectiva de tareas automatizadas en un entorno RHEL.
Programar un trabajo único con 'at'
En este paso, aprenderá a programar un trabajo para que se ejecute una sola vez en un momento futuro utilizando el comando at. El comando at es útil para ejecutar comandos que no necesitan ejecutarse repetidamente. Programaremos un trabajo simple, inspeccionaremos sus detalles y luego lo eliminaremos.
En este laboratorio, trabajaremos directamente en el sistema local para aprender la programación de tareas. Todos los comandos se ejecutarán en su entorno de terminal actual.
Programemos un trabajo para imprimir la fecha y hora actuales en un archivo llamado ~/myjob.txt en su directorio de inicio. Lo programaremos para que se ejecute dentro de 3 minutos:
at now + 3 minutes << EOF
date > ~/myjob.txt
EOF
El mensaje warning: commands will be executed using /bin/sh es normal. La salida job N at ... indica el número del trabajo y la hora de ejecución programada. Anote el número del trabajo, ya que lo necesitará más adelante.
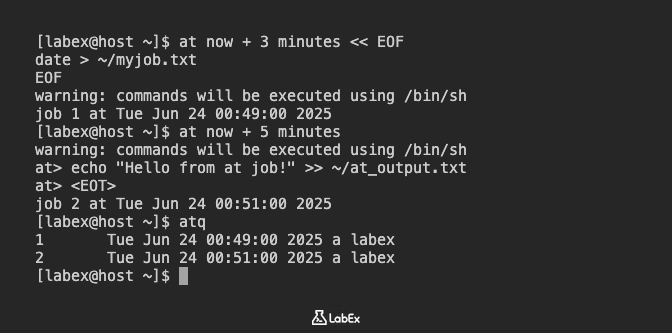
A continuación, programemos otro trabajo de forma interactiva. Este método es útil para introducir varios comandos o scripts más complejos. Programaremos un trabajo para añadir "Hello from at job!" a ~/at_output.txt dentro de 5 minutos:
at now + 5 minutes
Después de escribir el comando y presionar Enter, verá un prompt at>. Escriba su comando y luego presione Ctrl+d para finalizar:
at > echo "Hello from at job!" >> ~/at_output.txt
at > Ctrl+d
Para ver los trabajos que están actualmente en la cola de at, utilice el comando atq. Este comando lista todos los trabajos pendientes de at para el usuario actual.
atq
La salida mostrará el número del trabajo, la hora programada, la cola y el usuario que lo programó.
Puede inspeccionar los comandos que ejecutará un trabajo at específico utilizando el comando at -c seguido del número del trabajo. Reemplace N con uno de los números de trabajo que anotó anteriormente.
at -c N
Este comando mostrará el script de shell que at ejecutará para ese trabajo. Debería ver el comando date > ~/myjob.txt o echo "Hello from at job!" >> ~/at_output.txt dentro de la salida.
Finalmente, para eliminar un trabajo at programado, utilice el comando atrm seguido del número del trabajo. Eliminemos el primer trabajo que programamos. Reemplace N con el número de trabajo de su primer trabajo.
atrm N
Después de eliminar el trabajo, puede usar atq nuevamente para verificar que ya no está en la cola.
atq
Ahora solo debería ver el segundo trabajo (si aún no se ha ejecutado) o una cola vacía si ambos trabajos han sido eliminados o ejecutados.
Esto completa el primer paso de la programación de trabajos únicos con el comando at.
Gestionar trabajos 'at'
En este paso, profundizaremos en la gestión de trabajos at, incluyendo la programación de trabajos con diferentes colas y la verificación de su ejecución. Comprender las colas de at puede ser útil para priorizar tareas o separar diferentes tipos de trabajos únicos.
Continuaremos trabajando en el sistema local para explorar funciones de gestión de trabajos at más avanzadas.
El comando at permite especificar una cola usando la opción -q. Las colas son letras individuales de a a z. La cola a es la predeterminada, y los trabajos en las colas a a z se ejecutan con una cortesía (prioridad) decreciente. La cola a tiene la prioridad más alta y la cola z tiene la más baja. La cola b está reservada para trabajos por lotes (batch jobs).
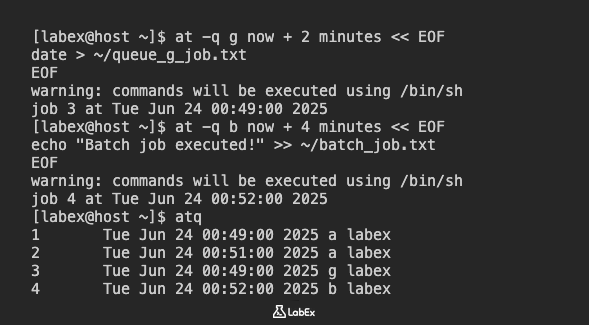
Programemos un trabajo en la cola g (una cola de menor prioridad) para que se ejecute en 2 minutos. Este trabajo creará un archivo llamado ~/queue_g_job.txt con una marca de tiempo:
at -q g now + 2 minutes << EOF
date > ~/queue_g_job.txt
EOF
Verá una salida similar a job N at .... Anote este número de trabajo.
A continuación, programemos otro trabajo, esta vez en la cola b (cola de lotes), que se utiliza típicamente para trabajos que pueden ejecutarse cuando la carga del sistema es baja. Este trabajo añadirá "Batch job executed!" a ~/batch_job.txt. Lo programaremos para que se ejecute dentro de 4 minutos:
at -q b now + 4 minutes << EOF
echo "Batch job executed!" >> ~/batch_job.txt
EOF
Nuevamente, anote el número de trabajo.
Para ver todos los trabajos pendientes, incluidos los de diferentes colas, use atq.
atq
Ahora debería ver ambos trabajos listados, con sus respectivas letras de cola (g y b).
Ahora, espere a que se ejecuten sus trabajos programados. Espere al menos 5 minutos para permitir que todos los trabajos se completen. Puede verificar si los archivos creados por sus trabajos at existen y contienen el contenido esperado.
Verifique ~/queue_g_job.txt:
cat ~/queue_g_job.txt
Debería ver una cadena de fecha y hora.
Verifique ~/batch_job.txt:
cat ~/batch_job.txt
Debería ver "Batch job executed!".
Si los archivos no están presentes o están vacíos, podría significar que los trabajos aún no se han ejecutado o que hubo un problema con el comando. Puede volver a verificar atq para ver si todavía están pendientes.
Esto completa el paso de gestión avanzada de trabajos at. Los trabajos at restantes se eliminarán automáticamente cuando se destruya el contenedor.
Programar trabajos recurrentes de usuario con 'crontab'
En este paso, aprenderá a programar tareas recurrentes para un usuario específico utilizando crontab. A diferencia de los trabajos at, que se ejecutan una vez, los trabajos cron se ejecutan repetidamente en intervalos especificados. Esto es ideal para el mantenimiento rutinario, copias de seguridad de datos o generación de informes.
Continuaremos trabajando en el sistema local para aprender sobre la gestión de crontab de usuario.
El comando crontab permite a los usuarios crear, editar y ver sus propios trabajos cron. Cada usuario tiene su propio archivo crontab.
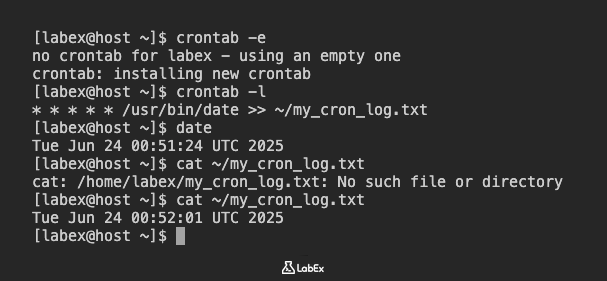
Para editar su archivo crontab, use el comando crontab -e. Esto abrirá su archivo crontab en el editor de texto predeterminado (generalmente vim).
crontab -e
Instrucciones del editor Vim:
- Presione
ipara entrar en modo de inserción (verá-- INSERT --en la parte inferior) - Use las teclas de flecha para navegar
- Para guardar y salir: Presione
Escpara salir del modo de inserción, luego escriba:wqy presioneEnter - Para salir sin guardar: Presione
Esc, luego escriba:q!y presioneEnter
Dentro del editor, agregará una nueva línea para definir su trabajo cron. Una entrada cron tiene cinco campos de hora y fecha, seguidos del comando que se ejecutará. Los campos son:
- Minuto (0-59)
- Hora (0-23)
- Día del mes (1-31)
- Mes (1-12)
- Día de la semana (0-7, donde 0 o 7 es domingo)
Puede usar * como comodín para significar "cada" para un campo, o / para especificar valores de paso (por ejemplo, */5 para cada 5 minutos).
Programemos un trabajo que agregue la fecha y hora actuales a un archivo llamado ~/my_cron_log.txt cada minuto. Esto nos permitirá observar rápidamente el trabajo cron en acción.
Siga estos pasos en vim:
- Presione
ipara entrar en modo de inserción - Agregue la siguiente línea al archivo
crontab:
* * * * * /usr/bin/date >> ~/my_cron_log.txt
- Presione
Escpara salir del modo de inserción - Escriba
:wqy presioneEnterpara guardar y salir
Debería ver un mensaje que indica que se ha instalado un nuevo crontab:
crontab: installing new crontab
Para verificar que su trabajo cron se ha agregado correctamente, puede listar sus entradas crontab usando el comando crontab -l:
crontab -l
Debería ver la línea que acaba de agregar:
* * * * * /usr/bin/date >> ~/my_cron_log.txt
Ahora, espere uno o dos minutos para permitir que el trabajo cron se ejecute al menos una vez. Puede verificar la hora actual para ver cuándo ocurrirá la próxima marca de minuto:
date
Después de esperar al menos dos minutos para permitir que el trabajo cron se ejecute un par de veces, verifique el contenido del archivo ~/my_cron_log.txt.
cat ~/my_cron_log.txt
Debería ver una o más líneas, cada una conteniendo una fecha y hora, lo que indica que su trabajo cron se ha ejecutado.
Mon Apr 8 10:30:01 AM EDT 2024
Mon Apr 8 10:31:01 AM EDT 2024
Esto completa el paso de gestión de crontab de usuario. El trabajo cron continuará ejecutándose hasta que el contenedor sea destruido.
Gestionar las entradas 'crontab' del usuario
En este paso, aprenderá técnicas más avanzadas para gestionar las entradas crontab de usuario, incluyendo la edición de trabajos existentes, la adición de múltiples trabajos y la comprensión de cadenas cron especiales. La gestión efectiva de crontab es crucial para automatizar tareas de rutina.
Continuaremos trabajando en el sistema local para explorar técnicas avanzadas de gestión de crontab.
Comencemos agregando un nuevo trabajo cron. Este trabajo agregará "Hello from cron!" a ~/cron_messages.txt cada dos minutos.
Abra su crontab para editarlo:
crontab -e
En vim:
- Presione
ipara entrar en el modo de inserción - Agregue la siguiente línea al archivo
crontab:
*/2 * * * * echo "Hello from cron!" >> ~/cron_messages.txt
- Presione
Escpara salir del modo de inserción - Escriba
:wqy presioneEnterpara guardar y salir
Verifique que la entrada se haya agregado:
crontab -l
Debería ver la línea recién agregada.
Ahora, agreguemos otro trabajo cron que se ejecute diariamente a las 08:00 AM. Este trabajo registrará el uso del disco de su directorio de inicio en ~/disk_usage.log.
Abra su crontab para editarlo nuevamente:
crontab -e
En vim:
- Presione
ipara entrar en el modo de inserción - Agregue la siguiente línea debajo de la anterior:
0 8 * * * du -sh ~ >> ~/disk_usage.log
- Presione
Escpara salir del modo de inserción - Escriba
:wqy presioneEnterpara guardar y salir
Verifique que ambas entradas estén presentes:
crontab -l
Ahora debería ver ambos trabajos cron listados.
cron también admite cadenas especiales que pueden simplificar las programaciones comunes. Estas incluyen @reboot, @yearly, @annually, @monthly, @weekly, @daily, @midnight y @hourly. Por ejemplo, @hourly es equivalente a 0 * * * *.
Agreguemos un trabajo que se ejecute cada hora y registre el tiempo de actividad del sistema en ~/uptime_log.txt.
Abra su crontab para editarlo:
crontab -e
En vim:
- Presione
ipara entrar en el modo de inserción - Agregue la siguiente línea:
@hourly uptime >> ~/uptime_log.txt
- Presione
Escpara salir del modo de inserción - Escriba
:wqy presioneEnterpara guardar y salir
Verifique las tres entradas:
crontab -l
Ahora debería ver los tres trabajos cron.
Para demostrar el efecto de estos trabajos, esperaremos un corto período. Dado que los trabajos están programados a diferentes intervalos, no los veremos todos ejecutarse inmediatamente, pero podemos verificar la configuración.
Espere al menos 3 minutos para permitir que el trabajo */2 se ejecute al menos una vez.
Verifique el archivo ~/cron_messages.txt:
cat ~/cron_messages.txt
Debería ver al menos un mensaje "Hello from cron!".
Hello from cron!
Es posible que los archivos ~/disk_usage.log y ~/uptime_log.txt aún no se hayan creado, dependiendo de la hora actual, ya que están programados para la ejecución diaria y horaria, respectivamente. La parte importante es que sus entradas están correctamente configuradas en su crontab.
Esto completa el paso de gestión de crontab de usuario. Todos los trabajos cron continuarán ejecutándose hasta que se destruya el contenedor.
Programar trabajos recurrentes del sistema con directorios cron
En este paso, aprenderá a programar tareas recurrentes en todo el sistema utilizando directorios cron. A diferencia de las entradas crontab de usuario, que son específicas de un usuario, los trabajos cron del sistema son gestionados por el usuario root y afectan a todo el sistema. Estos se utilizan típicamente para el mantenimiento del sistema, la rotación de registros y otras tareas administrativas.
Continuaremos trabajando en el sistema local para explorar la configuración de trabajos cron en todo el sistema.
Los trabajos cron en todo el sistema se definen en /etc/crontab o colocando scripts en directorios específicos:
/etc/cron.hourly/: Los scripts en este directorio se ejecutan una vez por hora./etc/cron.daily/: Los scripts en este directorio se ejecutan una vez al día./etc/cron.weekly/: Los scripts en este directorio se ejecutan una vez a la semana./etc/cron.monthly/: Los scripts en este directorio se ejecutan una vez al mes.
Estos directorios son procesados por la utilidad run-parts, que ejecuta todos los archivos ejecutables dentro de ellos.
Para gestionar los trabajos cron del sistema, necesita privilegios de root. Dado que el usuario labex tiene acceso sudo, podemos usar sudo para los comandos requeridos.
Creemos un script simple que registre un mensaje en el registro del sistema. Colocaremos este script en /etc/cron.hourly/ para que se ejecute cada hora.
Primero, cree el archivo de script /etc/cron.hourly/my_hourly_script:
sudo nano /etc/cron.hourly/my_hourly_script
Agregue el siguiente contenido al archivo:
#!/bin/bash
logger "Hourly cron job executed at $(date)"
Guarde y salga del editor (Ctrl+o, Enter, Ctrl+x en nano).
A continuación, debe hacer que el script sea ejecutable. Sin permisos de ejecución, run-parts lo ignorará.
sudo chmod +x /etc/cron.hourly/my_hourly_script
Ahora, verifiquemos que el script sea ejecutable:
ls -l /etc/cron.hourly/my_hourly_script
Debería ver x en los permisos, por ejemplo: -rwxr-xr-x.
Dado que los trabajos cron.hourly se ejecutan una vez por hora, no podemos esperar una hora completa para verificar su ejecución en este laboratorio. Sin embargo, podemos activar manualmente el comando run-parts para el directorio horario para simular su ejecución.
sudo run-parts /etc/cron.hourly/
Este comando ejecutará todos los scripts ejecutables en /etc/cron.hourly/. El script que creamos usa el comando logger para escribir mensajes en el registro del sistema. Si bien no podemos verificar fácilmente la salida del registro en este entorno de contenedor, el objetivo de aprendizaje importante es comprender cómo crear y gestionar scripts en los directorios cron.
En un sistema RHEL real, podría verificar los registros del sistema usando journalctl o /var/log/messages para verificar que el script se ejecutó correctamente.
Esto completa el paso de gestión de trabajos cron del sistema. El script permanecerá en su lugar y se ejecutaría cada hora en un entorno de sistema real.
Configurar temporizadores systemd para tareas recurrentes
En este paso, aprenderá sobre los temporizadores systemd, que son una alternativa moderna a cron para programar tareas en sistemas Linux. Los temporizadores systemd ofrecen más flexibilidad y una mejor integración con el ecosistema systemd. Si bien los comandos systemctl se utilizan típicamente para gestionar las unidades systemd, debido al entorno del contenedor Docker, nos centraremos en crear y verificar los archivos de unidad de temporizador y servicio directamente.
Los temporizadores systemd funcionan en conjunto con las unidades de servicio systemd. Una unidad de temporizador (archivo .timer) define cuándo debe ejecutarse una tarea, y una unidad de servicio (archivo .service) define qué tarea debe ejecutarse.
Continuaremos trabajando en el sistema local para explorar la configuración de los temporizadores systemd.
Necesitará privilegios de root para crear archivos de unidad systemd en directorios del sistema. Dado que el usuario labex tiene acceso sudo, podemos usar sudo para los comandos requeridos.
Creemos un servicio simple que registre un mensaje en un archivo. Colocaremos este archivo de unidad de servicio en /etc/systemd/system/, que es donde se almacenan típicamente las unidades de servicio personalizadas.
Cree el archivo de unidad de servicio /etc/systemd/system/my-custom-task.service:
sudo nano /etc/systemd/system/my-custom-task.service
Agregue el siguiente contenido al archivo:
[Unit]
Description=My Custom Scheduled Task
[Service]
Type=oneshot
ExecStart=/bin/bash -c 'echo "My custom task executed at $(date)" >> /var/log/my-custom-task.log'
Guarde y salga del editor (Ctrl+o, Enter, Ctrl+x en nano).
A continuación, cree el archivo de unidad de temporizador /etc/systemd/system/my-custom-task.timer. Este temporizador activará nuestro servicio cada 5 minutos.
sudo nano /etc/systemd/system/my-custom-task.timer
Agregue el siguiente contenido al archivo:
[Unit]
Description=Run My Custom Scheduled Task every 5 minutes
[Timer]
Persistent=true
[Install]
WantedBy=timers.target
Guarde y salga del editor.
Explicación de OnCalendar:
*:0/5significa "cada 5 minutos".*para año, mes, día, hora (cualquier valor).0/5para minuto, lo que significa comenzando en el minuto 0, cada 5 minutos (0, 5, 10, ..., 55).
En un entorno systemd típico, ahora ejecutaría systemctl daemon-reload para que systemd esté al tanto de los nuevos archivos de unidad, y luego systemctl enable --now my-custom-task.timer para iniciar el temporizador. Sin embargo, debido a las limitaciones del contenedor Docker, systemctl no es completamente funcional.
En cambio, verificaremos manualmente la creación de los archivos. El demonio systemd dentro del contenedor podría recoger estos archivos eventualmente, pero no podemos controlar ni observar directamente la ejecución de su temporizador en esta configuración de laboratorio. El objetivo principal aquí es comprender cómo configurar estos archivos.
Verifiquemos la existencia de los archivos creados:
ls -l /etc/systemd/system/my-custom-task.service
ls -l /etc/systemd/system/my-custom-task.timer
Debería ver la salida que indica que ambos archivos existen.
Para simular la ejecución del servicio, puede ejecutar manualmente el comando definido en ExecStart:
sudo /bin/bash -c 'echo "My custom task executed at $(date)" >> /var/log/my-custom-task.log'
Ahora, verifique el archivo de registro para ver la salida:
sudo cat /var/log/my-custom-task.log
Debería ver el mensaje que acaba de registrar:
My custom task executed at Tue Jun 10 06:54:40 UTC 2025
Esto completa el paso de configuración del temporizador systemd. Los archivos de unidad de servicio y temporizador permanecerán en su lugar como referencia.
Gestionar archivos temporales con systemd-tmpfiles
En este paso, aprenderá a gestionar archivos y directorios temporales utilizando systemd-tmpfiles. Esta utilidad es parte de systemd y es responsable de crear, eliminar y limpiar archivos y directorios volátiles y temporales. Se utiliza comúnmente para gestionar /tmp, /var/tmp y otras ubicaciones de almacenamiento temporal, asegurando que los archivos antiguos se eliminen periódicamente.
Continuaremos trabajando en el sistema local para explorar la configuración de systemd-tmpfiles.
Necesitará privilegios de root para configurar systemd-tmpfiles. Dado que el usuario labex tiene acceso sudo, podemos usar sudo para los comandos requeridos.
systemd-tmpfiles lee los archivos de configuración de /etc/tmpfiles.d/ y /usr/lib/tmpfiles.d/. Estos archivos definen reglas para crear, eliminar y gestionar archivos y directorios.
Creemos un archivo de configuración personalizado para gestionar un nuevo directorio temporal. Crearemos un directorio /run/my_temp_dir y configuraremos systemd-tmpfiles para limpiar los archivos con más de 1 minuto de antigüedad.
Cree el archivo de configuración /etc/tmpfiles.d/my_temp_dir.conf:
sudo nano /etc/tmpfiles.d/my_temp_dir.conf
Agregue el siguiente contenido al archivo:
d /run/my_temp_dir 0755 labex labex 1m
Explicación de la línea:
d: Especifica que esta entrada define un directorio./run/my_temp_dir: La ruta al directorio.0755: Los permisos para el directorio.labex labex: El propietario y el grupo para el directorio.1m: La antigüedad después de la cual los archivos en este directorio deben ser eliminados (1 minuto).
Guarde y salga del editor (Ctrl+o, Enter, Ctrl+x en nano).
Ahora, digamos a systemd-tmpfiles que aplique esta configuración. La opción --create creará el directorio si no existe.
sudo systemd-tmpfiles --create /etc/tmpfiles.d/my_temp_dir.conf
Verifique que el directorio se haya creado con los permisos y la propiedad correctos:
ls -ld /run/my_temp_dir
Debería ver una salida similar a:
drwxr-xr-x 2 labex labex 6 Jun 10 06:55 /run/my_temp_dir
A continuación, creemos un archivo de prueba dentro de este nuevo directorio temporal:
sudo touch /run/my_temp_dir/test_file.txt
Verifique que el archivo exista:
ls -l /run/my_temp_dir/test_file.txt
Ahora, necesitamos esperar más de 1 minuto para que el archivo se vuelva "antiguo" según nuestra configuración. Espere al menos 70 segundos (1 minuto y 10 segundos).
Después de esperar más de 1 minuto, ejecutaremos manualmente systemd-tmpfiles con la opción --clean para activar el proceso de limpieza basado en nuestra configuración.
sudo systemd-tmpfiles --clean /etc/tmpfiles.d/my_temp_dir.conf
Finalmente, verifique si test_file.txt ha sido eliminado:
ls -l /run/my_temp_dir/test_file.txt
Debería obtener un error "No such file or directory" (No existe el archivo o directorio), lo que indica que systemd-tmpfiles limpió con éxito el archivo antiguo.
Esto completa el paso de configuración de systemd-tmpfiles. El archivo de configuración y el directorio temporal permanecerán en su lugar como referencia.
Resumen
En este laboratorio, aprendió a programar y gestionar tareas únicas utilizando el comando at, incluyendo la programación de trabajos de forma interactiva y no interactiva, la visualización de la cola at con atq y la eliminación de trabajos pendientes con atrm. También adquirió competencia en la programación de tareas recurrentes específicas del usuario utilizando crontab, cubriendo cómo editar, listar y eliminar trabajos cron, y comprendiendo la sintaxis cron para especificar los tiempos de ejecución. Además, el laboratorio demostró cómo programar tareas recurrentes en todo el sistema colocando scripts en directorios cron estándar (/etc/cron.hourly, /etc/cron.daily, etc.) y cómo crear trabajos cron personalizados en /etc/cron.d.
Finalmente, exploró la programación de tareas avanzada con los temporizadores systemd, aprendiendo a crear y habilitar unidades de servicio y temporizador para tareas recurrentes, y cómo gestionar archivos y directorios temporales utilizando systemd-tmpfiles para la limpieza automatizada. Este laboratorio integral proporcionó experiencia práctica en la gestión de diversas necesidades de programación de tareas en sistemas RHEL, desde comandos simples únicos hasta procesos de sistema recurrentes complejos.


