
Introducción
En las versiones 2.0 y posteriores de Hadoop, se introdujo el nuevo patrón de administración de recursos de YARN, que facilita la utilización del clúster, la administración unificada de recursos y la compartición de datos. Basado en la construcción del clúster pseudo-distribuido de Hadoop, esta sección te permitirá aprender la arquitectura, el principio de funcionamiento, la configuración y las técnicas de desarrollo y monitoreo del marco YARN.
Esta práctica requiere un cierto conocimiento básico de programación en Java.
Por favor, escribe todo el código de ejemplo del documento por tu cuenta; no solo copies y pegués. De esta manera podrás familiarizarte más con el código. Si tienes problemas, revisa detenidamente la documentación, o puedes ir al foro para obtener ayuda y comunicarte.
Arquitectura y componentes de YARN
YARN, introducido en Hadoop 0.23 como parte de MapReduce 2.0 (MRv2), revolucionó la gestión de recursos y la programación de trabajos en los clústeres de Hadoop:
- Descomposición de JobTracker:
MRv2descompone las funciones deJobTrackeren demonios separados:ResourceManagerpara la gestión de recursos yApplicationMasterpara la programación y monitoreo de trabajos. - ResourceManager global: Cada aplicación tiene un
ApplicationMastercorrespondiente, que puede ser un trabajo MapReduce o un DAG que describe el trabajo. - Marco de cálculo de datos: El
ResourceManager,SlaveyNodeManagerforman un marco en el que el ResourceManager gobierna todos los recursos de la aplicación. - Componentes de ResourceManager: El
Schedulerasigna recursos basados en restricciones como capacidad y colas, mientras que elApplicationsManagermaneja la presentación de trabajos y la ejecución de ApplicationMaster. - Asignación de recursos: Los requisitos de recursos se definen usando contenedores de recursos con elementos como memoria, CPU, disco y red.
- Rol de NodeManager: NodeManager monitorea el uso de recursos de los contenedores y reporta a ResourceManager y Scheduler.
- Tareas de ApplicationMaster: ApplicationMaster negocia contenedores de recursos con Scheduler, rastrea el estado y monitorea el progreso.
La siguiente figura describe la relación:

YARN asegura la compatibilidad de la API con versiones anteriores, lo que permite una transición sin problemas para ejecutar tareas MapReduce. Comprender la arquitectura y los componentes de YARN es esencial para la gestión eficiente de recursos y la programación de trabajos en los clústeres de Hadoop.
Iniciando el demonio de Hadoop
Antes de aprender los parámetros de configuración relevantes y las técnicas de desarrollo de aplicaciones de YARN, necesitamos iniciar el demonio de Hadoop para que esté listo para usarse en cualquier momento.
Primero, doble clic para abrir la terminal Xfce en el escritorio y escribe el siguiente comando para cambiar al usuario hadoop:
su - hadoop
Consejo: La contraseña es 'hadoop' del usuario 'hadoop'.
Una vez completado el cambio, puedes iniciar los demonios relacionados con Hadoop, incluyendo los marcos HDFS y YARN.
Por favor, escribe los siguientes comandos en la terminal para iniciar los demonios:
/home/hadoop/hadoop/sbin/start-dfs.sh
/home/hadoop/hadoop/sbin/start-yarn.sh
Una vez finalizado el arranque, puedes elegir usar el comando jps para comprobar si los demonios asociados están en ejecución.
hadoop:~$ jps
3378 NodeManager
3028 SecondaryNameNode
3717 Jps
2791 DataNode
2648 NameNode
3240 ResourceManager
Preparando el archivo de configuración
En esta sección, aprenderemos sobre yarn-site.xml, que es uno de los archivos principales de configuración de Hadoop, para ver qué configuraciones se pueden hacer para el clúster YARN en este archivo.
Para evitar el uso incorrecto de los cambios al archivo de configuración, es mejor copiar el archivo de configuración de Hadoop a otro directorio y luego abrirlo.
Para hacer esto, escribe el siguiente comando en la terminal para crear un nuevo directorio para el archivo de configuración:
mkdir /home/hadoop/hadoop_conf
Luego copia el archivo principal de configuración yarn-site.xml de YARN desde el directorio de instalación al directorio recién creado.
Escribe el siguiente comando en la terminal para realizar la operación:
cp /home/hadoop/hadoop/etc/hadoop/yarn-site.xml /home/hadoop/hadoop_conf/yarn-site.xml
Luego utiliza el editor vim para abrir el archivo y ver su contenido:
vim /home/hadoop/hadoop_conf/yarn-site.xml
Cómo funciona el archivo de configuración
Sabemos que hay dos roles importantes en el marco de YARN: ResourceManager y NodeManager. Por lo tanto, cada elemento de configuración en el archivo es una configuración de los dos componentes anteriores.
Hay muchos elementos de configuración que se pueden establecer en este archivo, pero por defecto, este archivo no contiene ningún elemento de configuración personalizado. Por ejemplo, el archivo que abrimos ahora solo tiene el atributo aux-services que se especificó cuando se configuró previamente el clúster pseudo-distribuido de Hadoop, como se muestra en la siguiente figura:
hadoop:~$ cat /home/hadoop/hadoop/etc/hadoop/mapred-site.xml
...
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
Este elemento de configuración se utiliza para establecer los servicios dependientes que deben ejecutarse en el NodeManager. El valor de configuración que especificamos es mapreduce_shuffle, lo que indica que el valor predeterminado del programa MapReduce debe ejecutarse en YARN.
¿Los elementos de configuración no escritos en él no funcionan? No exactamente. Cuando los parámetros de configuración no se especifican explícitamente en el archivo, el marco de YARN de Hadoop leerá los valores predeterminados almacenados en archivos internos. Todos los elementos de configuración especificados explícitamente en el archivo yarn-site.xml sobrescribirán los valores predeterminados, lo que es una forma efectiva para que el sistema de Hadoop se adapte a diferentes escenarios de uso.
Elementos de configuración de ResourceManager
Comprender y configurar correctamente los ajustes de ResourceManager en el archivo yarn-site.xml es esencial para la gestión eficiente de recursos y la ejecución de trabajos en un clúster de Hadoop. A continuación, se presenta un resumen de los principales elementos de configuración relacionados con ResourceManager:
yarn.resourcemanager.address: Expone la dirección a los clientes para enviar aplicaciones y eliminar aplicaciones. El puerto predeterminado es 8032.yarn.resourcemanager.scheduler.address: Expone la dirección a ApplicationMaster para solicitar y liberar recursos. El puerto predeterminado es 8030.yarn.resourcemanager.resource-tracker.address: Expone la dirección a NodeManager para enviar latidos cardíacos y extraer tareas. El puerto predeterminado es 8031.yarn.resourcemanager.admin.address: Expone la dirección a los administradores para comandos de gestión. El puerto predeterminado es 8033.yarn.resourcemanager.webapp.address: Dirección de la interfaz web para ver información del clúster. El puerto predeterminado es 8088.yarn.resourcemanager.scheduler.class: Especifica el nombre de la clase principal del programador (por ejemplo, FIFO, CapacityScheduler, FairScheduler).- Configuración de hilos:
yarn.resourcemanager.resource-tracker.client.thread-countyarn.resourcemanager.scheduler.client.thread-count
- Asignación de recursos:
yarn.scheduler.minimum-allocation-mbyarn.scheduler.maximum-allocation-mbyarn.scheduler.minimum-allocation-vcoresyarn.scheduler.maximum-allocation-vcores
- Gestión de NodeManager:
yarn.resourcemanager.nodes.exclude-pathyarn.resourcemanager.nodes.include-path
- Configuración de latidos cardíacos:
yarn.resourcemanager.nodemanagers.heartbeat-interval-ms
La configuración de estos parámetros permite ajustar finamente el comportamiento de ResourceManager, la asignación de recursos, el manejo de hilos, la gestión de NodeManager y los intervalos de latidos cardíacos en un clúster de Hadoop. Comprender estos elementos de configuración ayuda a prevenir problemas y garantiza un funcionamiento fluido del clúster.
Elementos de configuración de NodeManager
Configurar los ajustes de NodeManager en el archivo yarn-site.xml es crucial para la gestión eficiente de recursos y tareas dentro de un clúster de Hadoop. A continuación, se presenta un resumen de los principales elementos de configuración relacionados con NodeManager:
yarn.nodemanager.resource.memory-mb: Especifica la memoria física total disponible para NodeManager. Este valor permanece constante durante la ejecución de YARN.yarn.nodemanager.vmem-pmem-ratio: Establece la relación entre la memoria virtual y la asignación de memoria física. La relación predeterminada es2.1.yarn.nodemanager.resource.cpu-vcores: Define el número total de CPU virtuales disponibles para NodeManager. El valor predeterminado es8.yarn.nodemanager.local-dirs: Ruta para almacenar resultados intermedios en NodeManager, permitiendo la configuración de múltiples directorios.yarn.nodemanager.log-dirs: Ruta al directorio de registros de NodeManager, que admite la configuración de múltiples directorios.yarn.nodemanager.log.retain-seconds: Tiempo máximo de retención de los registros de NodeManager, el predeterminado es 10800 segundos (3 horas).
La configuración de estos parámetros permite ajustar finamente la asignación de recursos, la gestión de memoria, las rutas de directorio y la configuración de retención de registros para un rendimiento óptimo y una utilización eficiente de recursos por parte de NodeManager en un clúster de Hadoop. Comprender estos elementos de configuración ayuda a garantizar un funcionamiento fluido y una ejecución eficiente de tareas dentro del clúster.
Consulta de elementos de configuración y referencias predeterminadas
Para explorar todos los elementos de configuración disponibles en YARN y otros componentes comunes de Hadoop, puedes consultar los archivos de configuración predeterminados proporcionados por Apache Hadoop. A continuación, se presentan los enlaces para acceder a las configuraciones predeterminadas:
Elementos de configuración de YARN:
Archivos de configuración comunes:
- core-default.xml (core-site.xml)
- hdfs-default.xml (hdfs-site.xml)
- mapred-default.xml (mapred-site.xml)
Explorar estas configuraciones predeterminadas proporciona descripciones detalladas de cada elemento de configuración y sus propósitos, lo que te ayuda a comprender el papel de cada parámetro en el diseño de la arquitectura de Hadoop.
Después de revisar las configuraciones, puedes cerrar el editor vim para concluir tu exploración de las configuraciones de Hadoop.
Creando directorios y archivos del proyecto
Vamos a aprender el proceso de desarrollo de la aplicación de YARN al imitar una aplicación de instancia oficial de YARN.
Primero, crea un directorio para el proyecto. Escribe el siguiente comando en la terminal para crear el directorio:
mkdir /home/hadoop/yarn_app
Luego, crea dos archivos de código fuente en el proyecto por separado.
El primero es Client.java. Utiliza el comando touch en la terminal para crear el archivo:
touch /home/hadoop/yarn_app/Client.java
Luego, crea el archivo ApplicationMaster.java:
touch /home/hadoop/yarn_app/ApplicationMaster.java
hadoop:~$ tree /home/hadoop/yarn_app/
/home/hadoop/yarn_app/
├── ApplicationMaster.java
└── Client.java
0 directorios, 2 archivos
Escribiendo el código del cliente
Al escribir el código para el Cliente, podrás entender las API y sus roles necesarios para desarrollar el Cliente bajo el marco de YARN.
El contenido del código es un poco largo. Una forma más eficiente que leerlo línea por línea es ingresarlo línea por línea en el archivo de código fuente que acabas de crear.
Primero, abre el archivo Client.java recién creado con el editor vim (o otro editor de texto):
vim /home/hadoop/yarn_app/Client.java
Luego, agrega el cuerpo principal del programa para indicar el nombre de la clase y el nombre del paquete para la clase:
package com.labex.yarn.app;
public class Client {
public static void main(String[] args){
//TODO: Edit code here.
}
}
El siguiente código está en forma de segmentación. Al escribir, escribe el siguiente código en la clase Client (es decir, el bloque de código donde se encuentra el comentario //TODO: Edit your code here).
El primer paso que debe hacer el cliente es crear e inicializar el objeto YarnClient y luego iniciarlo:
YarnClient yarnClient = YarnClient.createYarnClient();
yarnClient.init(conf);
yarnClient.start();
Después de crear Client, necesitamos crear un objeto de aplicación de YARN y su ID de aplicación:
YarnClientApplication app = yarnClient.createApplication();
GetNewApplicationResponse appResponse = app.getNewApplicationResponse();
El objeto appResponse contiene información sobre el clúster, como las capacidades mínimas y máximas de recursos del clúster. La información es necesaria para asegurarnos de que podemos configurar adecuadamente los parámetros cuando el ApplicationMaster inicia el contenedor correspondiente.
Una de las principales tareas en el Client es establecer el ApplicationSubmissionContext. Define toda la información que RM necesita para iniciar AM.
En general, el Client necesita establecer lo siguiente en el contexto:
- Información de la aplicación: Incluye el ID y el nombre de la app.
- Información de la cola y la prioridad: Incluye las colas y las prioridades asignadas para la presentación de aplicaciones.
- Usuarios: Quién es el usuario que presentó la app.
- ContainerLaunchContext: Define la información del contenedor en el que se inicia y ejecuta AM. Toda la información necesaria para ejecutar la aplicación se define en el
ContainerLaunchContext, incluyendo los recursos locales (archivos binarios, archivos jar, etc.), variables de entorno (CLASSPATH, etc.), comandos a ejecutar y Token seguro (RECT):
// Establece el contexto de presentación de la aplicación
ApplicationSubmissionContext appContext = app.getApplicationSubmissionContext();
ApplicationId appId = appContext.getApplicationId();
appContext.setKeepContainersAcrossApplicationAttempts(keepContainers);
appContext.setApplicationName(appName);
// El siguiente código se utiliza para establecer los recursos locales de ApplicationMaster
/ / Los recursos locales deben ser archivos locales o paquetes comprimidos, etc.
// En este escenario, el paquete jar está en forma de archivo como uno de los recursos locales de AM.
Map<String, LocalResource> localResources = new HashMap<String, LocalResource>();
LOG.info("Copy AppMaster jar from local filesystem and add to local environment.");
// Copia el paquete jar de ApplicationMaster al sistema de archivos
FileSystem fs = FileSystem.get(conf);
// Crea un recurso local que apunta a la ruta del paquete jar
addToLocalResources(fs, appMasterJar, appMasterJarPath, appId.toString(), localResources, null);
// Establece los parámetros de los registros, se puede omitir
if (!log4jPropFile.isEmpty()) {
addToLocalResources(fs, log4jPropFile, log4jPath, appId.toString(), localResources, null);
}
// El script de shell estará disponible en el contenedor que finalmente lo ejecutará
// Entonces primero cópielo al sistema de archivos para que el marco de YARN pueda encontrarlo
// No es necesario establecerlo como recurso local de AM aquí porque este último no lo necesita
String hdfsShellScriptLocation = "";
long hdfsShellScriptLen = 0;
long hdfsShellScriptTimestamp = 0;
if (!shellScriptPath.isEmpty()) {
Path shellSrc = new Path(shellScriptPath);
String shellPathSuffix = appName + "/" + appId.toString() + "/" + SCRIPT_PATH;
Path shellDst = new Path(fs.getHomeDirectory(), shellPathSuffix);
fs.copyFromLocalFile(false, true, shellSrc, shellDst);
hdfsShellScriptLocation = shellDst.toUri().toString();
FileStatus shellFileStatus = fs.getFileStatus(shellDst);
hdfsShellScriptLen = shellFileStatus.getLen();
hdfsShellScriptTimestamp = shellFileStatus.getModificationTime();
}
if (!shellCommand.isEmpty()) {
addToLocalResources(fs, null, shellCommandPath, appId.toString(),
localResources, shellCommand);
}
if (shellArgs.length > 0) {
addToLocalResources(fs, null, shellArgsPath, appId.toString(),
localResources, StringUtils.join(shellArgs, " "));
}
// Establece los parámetros de entorno que necesita AM
LOG.info("Set the environment for the application master");
Map<String, String> env = new HashMap<String, String>();
// Agrega la ruta al script de shell a la variable de entorno
// AM creará el recurso local correcto para el contenedor final en consecuencia
// y el contenedor anterior ejecutará el script de shell al inicio
env.put(DSConstants.DISTRIBUTEDSHELLSCRIPTLOCATION, hdfsShellScriptLocation);
env.put(DSConstants.DISTRIBUTEDSHELLSCRIPTTIMESTAMP, Long.toString(hdfsShellScriptTimestamp));
env.put(DSConstants.DISTRIBUTEDSHELLSCRIPTLEN, Long.toString(hdfsShellScriptLen));
// Agrega la ruta a AppMaster.jar al classpath
// Tenga en cuenta que no es necesario proporcionar un classpath relacionado con Hadoop aquí, ya que tenemos una anotación en el archivo de configuración externo.
// El siguiente código agrega todos los ajustes de ruta relacionados con el classpath que necesita AM al directorio actual
StringBuilder classPathEnv = new StringBuilder(Environment.CLASSPATH.$$())
.append(ApplicationConstants.CLASS_PATH_SEPARATOR).append("./*");
for (String c : conf.getStrings(
YarnConfiguration.YARN_APPLICATION_CLASSPATH,
YarnConfiguration.DEFAULT_YARN_CROSS_PLATFORM_APPLICATION_CLASSPATH)) {
classPathEnv.append(ApplicationConstants.CLASS_PATH_SEPARATOR);
classPathEnv.append(c.trim());
}
classPathEnv.append(ApplicationConstants.CLASS_PATH_SEPARATOR).append(
"./log4j.properties");
// Establece el comando para ejecutar AM
Vector<CharSequence> vargs = new Vector<CharSequence>(30);
// Establece el comando ejecutable para Java
LOG.info("Setting up app master command");
vargs.add(Environment.JAVA_HOME.$$() + "/bin/java");
// Establece los números de memoria asignados por los parámetros Xmx bajo JVM
vargs.add("-Xmx" + amMemory + "m");
// Establece los nombres de clase
vargs.add(appMasterMainClass);
// Establece el parámetro de ApplicationMaster
vargs.add("--container_memory " + String.valueOf(containerMemory));
vargs.add("--container_vcores " + String.valueOf(containerVirtualCores));
vargs.add("--num_containers " + String.valueOf(numContainers));
vargs.add("--priority " + String.valueOf(shellCmdPriority));
for (Map.Entry<String, String> entry : shellEnv.entrySet()) {
vargs.add("--shell_env " + entry.getKey() + "=" + entry.getValue());
}
if (debugFlag) {
vargs.add("--debug");
}
vargs.add("1>" + ApplicationConstants.LOG_DIR_EXPANSION_VAR + "/AppMaster.stdout");
vargs.add("2>" + ApplicationConstants.LOG_DIR_EXPANSION_VAR + "/AppMaster.stderr");
// Genera el parámetro final y lo configura
StringBuilder command = new StringBuilder();
for (CharSequence str : vargs) {
command.append(str).append(" ");
}
LOG.info("Completed setting up app master command " + command.toString());
List<String> commands = new ArrayList<String>();
commands.add(command.toString());
// Establece el contenedor para que AM inicie el contexto
ContainerLaunchContext amContainer = ContainerLaunchContext.newInstance(
localResources, env, commands, null, null, null);
// La exigencia de configurar los tipos de recursos, incluyendo memoria y núcleos virtuales de CPU.
Resource capability = Resource.newInstance(amMemory, amVCores);
appContext.setResource(capability);
// Si es necesario, los datos del servicio de YARN se pasan a las aplicaciones en formato binario. Pero no es necesario en este ejemplo.
// amContainer.setServiceData(serviceData);
// Establece el Token
if (UserGroupInformation.isSecurityEnabled()) {
Credentials credentials = new Credentials();
String tokenRenewer = conf.get(YarnConfiguration.RM_PRINCIPAL);
if (tokenRenewer == null || tokenRenewer.length() == 0) {
throw new IOException(
"Can't get Master Kerberos principal for the RM to use as renewer");
}
// Obtiene el token del sistema de archivos predeterminado
final Token<?> tokens[] =
fs.addDelegationTokens(tokenRenewer, credentials);
if (tokens!= null) {
for (Token<?> token : tokens) {
LOG.info("Got dt for " + fs.getUri() + "; " + token);
}
}
DataOutputBuffer dob = new DataOutputBuffer();
credentials.writeTokenStorageToStream(dob);
ByteBuffer fsTokens = ByteBuffer.wrap(dob.getData(), 0, dob.getLength());
amContainer.setTokens(fsTokens);
}
appContext.setAMContainerSpec(amContainer);
Una vez que el proceso de configuración se completa, el cliente puede enviar aplicaciones con la prioridad y la cola especificadas:
/ / Establece la prioridad de AM
Priority pri = Priority.newInstance(amPriority);
appContext.setPriority(pri);
// Establece la cola a la que la aplicación se presenta a RM
appContext.setQueue(amQueue);
// Envía la app a AM
yarnClient.submitApplication(appContext);
En este momento, RM aceptará la aplicación y configurará y lanzará AM en el contenedor asignado en segundo plano.
Los clientes pueden seguir el progreso de las tareas reales de varias maneras.
(1) Una de ellas es que puedes comunicarte con el RM a través del método getApplicationReport() del objeto YarnClient y solicitar un informe de la aplicación:
// Utiliza el ID de la app para obtener su informe
ApplicationReport report = yarnClient.getApplicationReport(appId);
Los informes recibidos de RM incluyen lo siguiente:
- Información general: Incluye el número (posición) de la aplicación, la cola para enviar la aplicación, el usuario que envió la aplicación y la hora de inicio de la aplicación.
- Detalles de ApplicationMaster: El host que está ejecutando AM, el puerto RPC que está escuchando las solicitudes de los Clientes y los Tokens que el Cliente y AM necesitan para comunicarse.
- Información de seguimiento de la aplicación: Si la aplicación admite algún tipo de seguimiento de progreso, puede establecer la URL de seguimiento a través del método
getTrackingUrl()informado por la aplicación y el cliente puede monitorear el progreso mediante este método. - Estado de la aplicación: Puedes ver el estado de la aplicación de
ResourceManagerengetYarnApplicationState. SiYarnApplicationStatese establece encomplete, el Cliente debe consultargetFinalApplicationStatuspara comprobar si la tarea de la aplicación se ha ejecutado realmente con éxito. En caso de un error, se pueden encontrar más detalles sobre el error congetDiagnostics.
(2) Si el ApplicationMaster lo admite, el Cliente puede consultar directamente el progreso de AM mismo utilizando la información hostname:rpcport obtenida del informe de la aplicación.
En algunos casos, si la aplicación ha estado en ejecución durante demasiado tiempo, el Cliente puede desear terminar la aplicación. YarnClient admite llamar a killApplication. Permite que el Cliente envíe una señal de terminación a AM a través del ResourceManager. Si está diseñado de esta manera, el administrador de aplicaciones también puede terminar la llamada a través de su soporte de capa RPC, lo que el cliente puede aprovechar.
El código específico es el siguiente, pero el código solo es para referencia y no debe escribirse en Client.java:
yarnClient.killApplication(appId);
Después de editar el contenido anterior, guarda el contenido y sale del editor vim.
Escribiendo el código del ApplicationMaster
De manera similar, utiliza el editor vim para abrir el archivo ApplicationMaster.java y escribir el código:
vim /home/hadoop/yarn_app/ApplicationMaster.java
package com.labex.yarn.app;
public class ApplicationMaster {
public static void main(String[] args){
//TODO:Edit code here.
}
}
La explicación del código sigue siendo en forma de segmento. Todo el código mencionado a continuación debe escribirse en la clase ApplicationMaster (es decir, el bloque de código donde se encuentra el comentario //TODO:Edit code here.).
AM es el verdadero propietario de la tarea, que es iniciado por RM y proporciona toda la información y los recursos necesarios a través del Cliente para supervisar y terminar la tarea.
Dado que AM se inicia en un solo contenedor, es probable que el contenedor comparta el mismo host físico con otros contenedores. Dadas las características de multiarrendamiento de la plataforma de computación en la nube y otros problemas, es posible no poder conocer los puertos preconfigurados para escuchar al principio.
Entonces, cuando AM se inicia, se le pueden dar varios parámetros a través del entorno. Estos parámetros incluyen el ContainerId del contenedor de AM, la hora de presentación de la aplicación y detalles sobre el host del NodeManager que está ejecutando AM.
Todas las interacciones con RM requieren que una aplicación se asigne. Si este proceso falla, cada aplicación puede intentarlo nuevamente. Puedes obtener ApplicationAttemptId a partir del ID del contenedor de AM. Hay APIs relacionadas que pueden convertir los valores obtenidos del entorno en objetos.
Escribe el siguiente código:
Map<String, String> envs = System.getenv();
String containerIdString = envs.get(ApplicationConstants.AM_CONTAINER_ID_ENV);
If (containerIdString == null) {
// El ID del contenedor debe estar establecido en la variable de entorno del marco
Throw new IllegalArgumentException(
"Container ID not set in the environment");
}
ContainerId containerId = ConverterUtils.toContainerId(containerIdString);
ApplicationAttemptId appAttemptID = containerId.getApplicationAttemptId();
Después de que AM se haya inicializado completamente, podemos iniciar dos clientes: uno al ResourceManager y el otro al NodeManager. Usamos un controlador de eventos personalizado para configurarlo, y los detalles se discuten más adelante:
AMRMClientAsync.CallbackHandler allocListener = new RMCallbackHandler();
amRMClient = AMRMClientAsync.createAMRMClientAsync(1000, allocListener);
amRMClient.init(conf);
amRMClient.start();
containerListener = createNMCallbackHandler();
nmClientAsync = new NMClientAsyncImpl(containerListener);
nmClientAsync.init(conf);
nmClientAsync.start();
AM debe enviar latidos cardíacos a RM periódicamente para que este último sepa que AM sigue en ejecución. El intervalo de expiración en RM está definido por YarnConfiguration y su valor predeterminado está definido por el elemento de configuración YarnConfiguration.RM_AM_EXPIRY_INTERVAL_MS en el archivo de configuración. AM necesita registrarse en el ResourceManager para comenzar a enviar latidos cardíacos:
// Regístrese en RM y empiece a enviar latidos cardíacos a RM
appMasterHostname = NetUtils.getHostname();
RegisterApplicationMasterResponse response = amRMClient.registerApplicationMaster(appMasterHostname, appMasterRpcPort, appMasterTrackingUrl);
La información de respuesta del proceso de registro puede incluir la capacidad máxima de recursos del clúster. Podemos usar esta información para verificar la solicitud de la aplicación:
// Guarde temporalmente la información sobre las capacidades de recursos del clúster en RM
int maxMem = response.getMaximumResourceCapability().getMemory();
LOG.info("Max mem capability of resources in this cluster " + maxMem);
int maxVCores = response.getMaximumResourceCapability().getVirtualCores();
LOG.info("Max vcores capability of resources in this cluster " + maxVCores);
// Use el límite de memoria máximo para constreñir el valor de solicitud de capacidad de memoria del contenedor
if (containerMemory > maxMem) {
LOG.info("Container memory specified above max threshold of cluster."
+ " Using max value." + ", specified=" + containerMemory + ", max="
+ maxMem);
containerMemory = maxMem;
}
if (containerVirtualCores > maxVCores) {
LOG.info("Container virtual cores specified above max threshold of cluster."
+ " Using max value." + ", specified=" + containerVirtualCores + ", max="
+ maxVCores);
containerVirtualCores = maxVCores;
}
List<Container> previousAMRunningContainers =
response.getContainersFromPreviousAttempts();
LOG.info("Received " + previousAMRunningContainers.size()
+ " previous AM's running containers on AM registration.");
Dependiendo de los requisitos de la tarea, AM puede programar un conjunto de contenedores para ejecutar tareas. Usamos estos requisitos para calcular cuántos contenedores necesitamos y solicitar un número correspondiente de contenedores:
int numTotalContainersToRequest = numTotalContainers - previousAMRunningContainers.size();
for (int i = 0; i < numTotalContainersToRequest; ++i) {
// Establece el objeto de solicitud para el contenedor de solicitud de RM
ContainerRequest containerAsk = setupContainerAskForRM();
// Envía la solicitud de contenedor a RM
amRMClient.addContainerRequest(containerAsk);
// Este bucle significa sondear RM para obtener contenedores después de obtener las cuotas completamente asignadas
}
El bucle anterior seguirá ejecutándose hasta que todos los contenedores se hayan iniciado y el script de shell se haya ejecutado (ya sea con éxito o con error).
En setupContainerAskForRM(), debes establecer lo siguiente:
- Capacidades de recursos: Actualmente, YARN admite requisitos de recursos basados en memoria, por lo que la solicitud debe definir cuánta memoria se necesita. Este valor se define en megabytes y debe ser menor que el múltiplo exacto de las capacidades máxima y mínima del clúster. Esta capacidad de memoria corresponde al límite de memoria física impuesto al contenedor de tarea. Las capacidades de recursos también incluyen recursos basados en cómputo (vCore).
- Prioridad: Al solicitar un conjunto de contenedores, AM puede definir diferentes prioridades para las colecciones. Por ejemplo, el AM de MapReduce puede asignar una prioridad más alta a los contenedores requeridos por la tarea de Map, mientras que el contenedor de la tarea de Reduce tiene una prioridad más baja:
Private ContainerRequest setupContainerAskForRM() {
/ / Establece la prioridad de la solicitud
Priority pri = Priority.newInstance(requestPriority);
/ / Establece la solicitud para el tipo de recurso, incluyendo memoria y CPU
Resource capability = Resource.newInstance(containerMemory,
containerVirtualCores);
ContainerRequest request = new ContainerRequest(capability, null, null, pri);
LOG.info("Requested container allocation: " + request.toString());
Return request;
}
Después de que AM haya enviado una solicitud de asignación de contenedores, el contenedor se inicia de manera asincrónica por el controlador de eventos del cliente AMRMClientAsync. Los programas que manejan esta lógica deben implementar la interfaz AMRMClientAsync.CallbackHandler.
(1) Cuando se asigna a un contenedor, el controlador debe iniciar un hilo. El hilo ejecuta el código correspondiente para iniciar el contenedor. Aquí usamos LaunchContainerRunnable para demostración. Vamos a discutir esta clase más adelante:
@Override
public void onContainersAllocated(List<Container> allocatedContainers) {
LOG.info("Got response from RM for container allocation, allocatedCnt=" + allocatedContainers.size());
numAllocatedContainers.addAndGet(allocatedContainers.size());
for (Container allocatedContainer : allocatedContainers) {
LaunchContainerRunnable runnableLaunchContainer =
new LaunchContainerRunnable(allocatedContainer, containerListener);
Thread launchThread = new Thread(runnableLaunchContainer);
// Inicia y ejecuta el contenedor con diferentes hilos, lo que evita que el hilo principal se bloquee cuando todos los contenedores no pueden asignar recursos
launchThreads.add(launchThread);
launchThread.start();
}
}
(2) Cuando se envía un latido cardíaco, el controlador de eventos debe informar el progreso de la aplicación:
@Override
public float getProgress() {
// Establece la información de progreso y la informa a RM la próxima vez que envíe un latido cardíaco
float progress = (float) numCompletedContainers.get() / numTotalContainers;
Return progress;
}
El hilo de inicio del contenedor realmente inicia el contenedor en NM. Después de asignar un contenedor a AM, debe seguir un proceso similar al que sigue el Cliente cuando se configura el ContainerLaunchContext para la última tarea que se ejecutará en el contenedor asignado. Después de definir el ContainerLaunchContext, AM puede iniciarlo a través de NMClientAsync:
// Establece los comandos necesarios para ejecutar en el contenedor asignado
Vector<CharSequence> vargs = new Vector<CharSequence>(5);
// Establece el comando ejecutable
vargs.add(shellCommand);
// Establece la ruta del script de shell
if (!scriptPath.isEmpty()) {
vargs.add(Shell.WINDOWS? ExecBatScripStringtPath
: ExecShellStringPath);
}
// Establece parámetros para los comandos de shell
vargs.add(shellArgs);
// Agrega parámetros de redirección de registro
vargs.add("1>" + ApplicationConstants.LOG_DIR_EXPANSION_VAR + "/stdout");
vargs.add("2>" + ApplicationConstants.LOG_DIR_EXPANSION_VAR + "/stderr");
// Obtiene el comando final
StringBuilder command = new StringBuilder();
for (CharSequence str : vargs) {
command.append(str).append(" ");
}
List<String> commands = new ArrayList<String>();
commands.add(command.toString());
// Establece ContainerLaunchContext para establecer recursos locales, variables de entorno, comandos y tokens para el constructor.
ContainerLaunchContext ctx = ContainerLaunchContext.newInstance(
localResources, shellEnv, commands, null, allTokens.duplicate(), null);
containerListener.addContainer(container.getId(), container);
nmClientAsync.startContainerAsync(container, ctx);
El objeto NMClientAsync y su controlador de eventos son responsables de manejar los eventos del contenedor. Incluye inicio, detención, actualizaciones de estado y errores para el contenedor.
Después de que el ApplicationMaster haya determinado que ha terminado, debe desregistrarse con el Cliente de AM-RM y luego detener el Cliente:
try {
amRMClient.unregisterApplicationMaster(appStatus, appMessage, null);
} catch (YarnException ex) {
LOG.error("Failed to unregister application", ex);
} catch (IOException e) {
LOG.error("Failed to unregister application", e);
}
amRMClient.stop();
El contenido anterior es el código principal de ApplicationMaster. Después de editar, guarda el contenido y sale del editor vim.
El proceso de lanzamiento de la aplicación
El proceso de lanzamiento de una aplicación en un clúster de Hadoop es el siguiente:
Compilando y lanzando la aplicación
Después de que se haya completado el código de la sección anterior, se puede compilar en un paquete Jar y enviarlo al clúster de Hadoop utilizando una herramienta de compilación como Maven y Gradle.
Dado que el proceso de compilación requiere conexión a Internet para descargar las dependencias correspondientes, toma mucho tiempo (aproximadamente una hora pico). Entonces, omita el proceso de compilación aquí y utilice el paquete Jar ya compilado en el directorio de instalación de Hadoop para los experimentos posteriores.
En este paso, usamos el ejemplo simple de jar para ejecutar la aplicación de yarn en lugar de construir el jar especificado por maven.
Utilice el comando yarn jar en la terminal para enviar la ejecución. Los parámetros involucrados en los siguientes comandos son la ruta al paquete Jar a ejecutar, el nombre de la clase principal, la ruta al paquete Jar enviado al marco de YARN, el número de comandos de shell a ejecutar y el número de contenedores:
/home/hadoop/hadoop/bin/yarn jar /home/hadoop/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar pi 3 3
Vea la salida en la terminal y podrá ver el progreso de la ejecución de la aplicación.
Estimated value of Pi is 3.55555555555555555556
Durante la ejecución de la tarea, puede ver los mensajes de cada etapa en la salida de la terminal, como inicializando el Cliente, conectando al RM y obteniendo la información del clúster.
Viendo los resultados de la ejecución de la aplicación
Haga doble clic para abrir el navegador web Firefox en el escritorio y escriba la siguiente URL en la barra de direcciones para ver la información de recursos de los nodos en el patrón de YARN del clúster de Hadoop:
http://localhost:8088
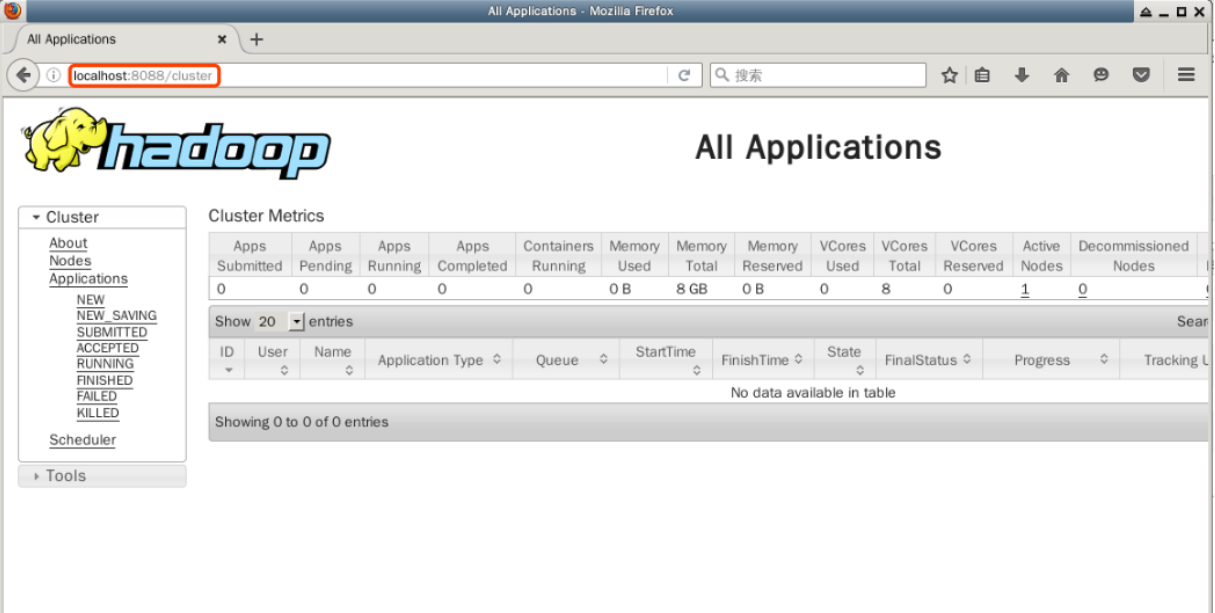
En esta página, se muestra toda la información sobre el clúster de Hadoop, incluyendo el estado de los nodos, aplicaciones y programadores.
Lo más importante de esto es la gestión de la aplicación, y más adelante podremos ver el estado de ejecución de la aplicación enviada aquí. No cierre el navegador Firefox por ahora.
Resumen
Basado en la configuración del clúster pseudo-distribuido de Hadoop, esta práctica continúa enseñándonos la arquitectura, el principio de funcionamiento, la configuración y las técnicas de desarrollo y monitoreo del marco YARN. Se proporcionan muchos archivos de código y de configuración en el curso, así que léalos detenidamente.


