
Introducción
OpenAI Whisper destaca en la conversión de habla de diversos archivos multimedia, incluyendo audio y video, en texto escrito. Este tutorial lo guiará a través de los usos esenciales y más sofisticados del comando Whisper, facilitando transcripciones de alta precisión.
Dominando Whisper para la Transcripción de Medios
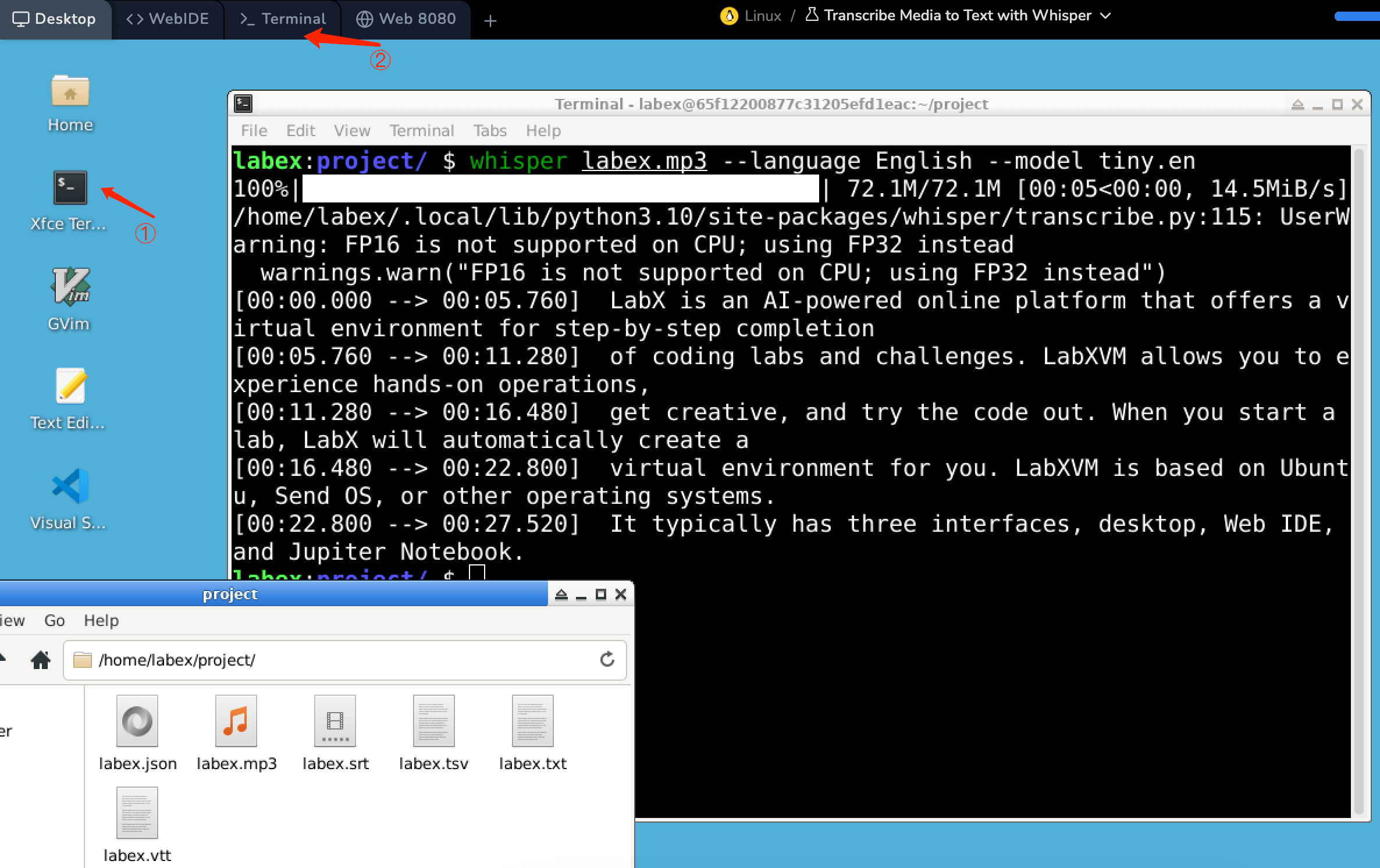
Hay un archivo de audio labex.mp3 en /home/labex/project. Abra la terminal (① o ② en la figura) en el entorno y escriba el siguiente comando:
whisper labex.mp3 --language English --model tiny.en
En este comando, whisper se instruye para transcribir el archivo multimedia labex.mp3.
- El parámetro
--languagese establece en "English", lo que indica el idioma hablado en el medio. - La opción
--modelselecciona el modelo Whisper a utilizar.tiny.enes un modelo más pequeño y rápido, optimizado para el idioma inglés, adecuado para tareas rápidas o hardware menos potente.
Después de ejecutar el comando Whisper para transcribir contenido multimedia, se pueden generar varios archivos en /home/labex/project, cada uno con un propósito y formato distinto para el texto transcrito. Aquí está una descripción general de cada tipo de archivo:
- output.json: Este archivo contiene los resultados detallados de la transcripción en formato JSON, que es un formato ligero de intercambio de datos fácil de leer y escribir para humanos y fácil de analizar y generar para máquinas. El archivo JSON incluye no solo el texto transcrito, sino también metadatos adicionales, como marcas de tiempo, puntuaciones de confianza y posiblemente identificación del hablante. Este formato es especialmente útil para aplicaciones que requieren un procesamiento o análisis detallado de los resultados de la transcripción, como para generar subtítulos con un tiempo preciso o para analizar patrones de habla.
- output.srt: El formato de archivo SRT (SubRip Subtitle) se utiliza para representar subtítulos o leyendas. Cada entrada en un archivo SRT consta de un número de secuencia, el rango de tiempo durante el cual se debe mostrar el texto y el texto en sí. Los archivos SRT son ampliamente compatibles con software y plataformas de reproducción de video, lo que hace que este formato sea ideal para agregar subtítulos a videos.
- output.tsv: TSV significa "Valores Separados por Tabulaciones". Este formato es similar al CSV (Valores Separados por Comas), pero utiliza tabulaciones como delimitadores entre los campos de datos. Un archivo
output.tsvgenerado por Whisper podría contener el texto transcrito junto con información de tiempo y puntuaciones de confianza, separados por tabulaciones. Este formato puede ser útil para tareas de análisis de datos o para importar los resultados de la transcripción a bases de datos o hojas de cálculo. - output.txt: Este es un archivo de texto plano que contiene solo el texto transcrito sin ninguna marca de tiempo o metadatos. La simplicidad de este formato lo hace adecuado para aplicaciones donde el contenido del texto es más importante que el tiempo o donde el texto debe ser leído o procesado por humanos o software básico de procesamiento de texto.
- output.vtt: VTT (Web Video Text Tracks) es otro formato de archivo de subtítulos similar al SRT, pero con más características. Es el formato estándar para las leyendas del etiqueta de video HTML5 y ofrece soporte para el estilo y la posición de los subtítulos. El formato VTT es especialmente útil para contenido de video web, ya que permite una experiencia de visualización más rica con subtítulos personalizables.
Cada uno de estos archivos sirve para diferentes casos de uso, desde documentos de texto simples hasta análisis detallados o subtitulado de videos, brindando flexibilidad en cómo se utilizan los resultados de la transcripción.
Resumen
Este tutorial lo ha guiado a través del uso de OpenAI Whisper para transcribir contenido de archivos multimedia a texto. Comenzando desde lo básico, aprendimos a transcribir un simple archivo multimedia en inglés. Luego avanzamos a explorar características adicionales para optimizar el proceso de transcripción, como elegir diferentes modelos y el procesamiento por lotes. Whisper se destaca como una herramienta versátil para transcribir una amplia variedad de archivos multimedia con facilidad.


