
介绍
OpenAI Whisper 擅长将各种媒体文件(包括音频和视频)中的语音转换为书面文本。本教程将引导你了解 Whisper 命令的基本和更高级的用法,帮助你实现高精度的转录。
掌握 Whisper 进行媒体转录
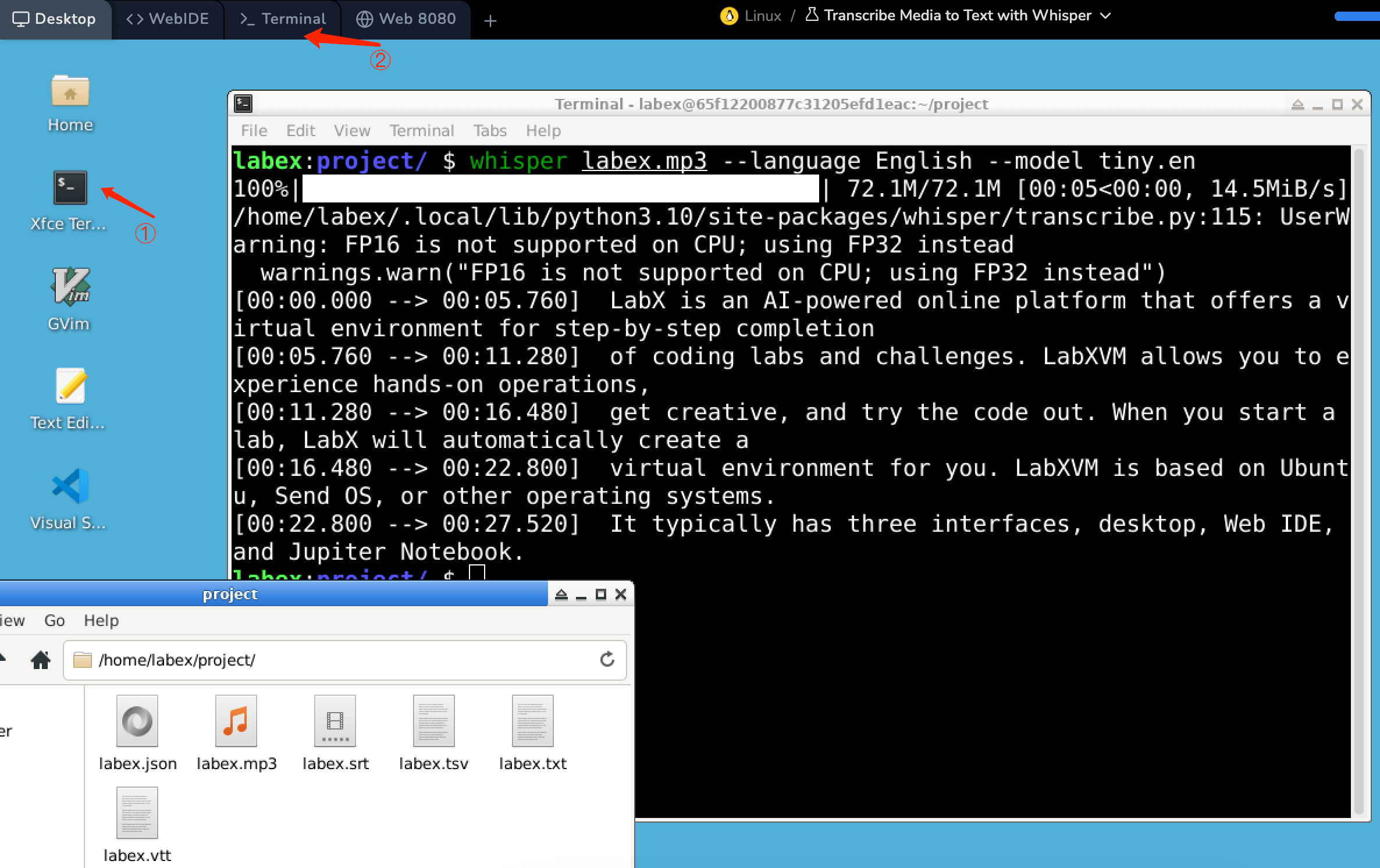
在 /home/labex/project 目录下有一个音频文件 labex.mp3,在环境中打开终端(图中的 ① 或 ②)并输入以下命令:
whisper labex.mp3 --language English --model tiny.en
在这个命令中,whisper 被指示转录媒体文件 labex.mp3。
--language参数设置为 English,表示媒体中的语言为英语。--model选项选择要使用的 Whisper 模型,tiny.en是一个更小、更快的模型,专为英语优化,适合快速任务或性能较低的硬件。
执行 Whisper 命令转录媒体内容后,会在 /home/labex/project 目录下生成多个文件,每个文件以不同的格式和用途保存转录文本。以下是每种文件类型的概述:
- output.json:此文件包含以 JSON 格式存储的详细转录结果。JSON 是一种轻量级的数据交换格式,易于人类阅读和编写,也易于机器解析和生成。JSON 文件不仅包含转录文本,还包括额外的元数据,如时间戳、置信度分数以及可能的说话人识别信息。这种格式特别适用于需要对转录结果进行详细处理或分析的应用场景,例如生成精确时间轴的字幕或分析语音模式。
- output.srt:SRT(SubRip Subtitle)文件格式用于表示字幕或标题。SRT 文件中的每个条目包括一个序列号、文本应显示的时间范围以及文本本身。SRT 文件被广泛支持于视频播放软件和平台,因此这种格式非常适合为视频添加字幕。
- output.tsv:TSV 代表制表符分隔值(Tab-Separated Values)。这种格式类似于 CSV(逗号分隔值),但使用制表符作为数据字段之间的分隔符。Whisper 生成的
output.tsv文件可能包含转录文本以及时间信息和置信度分数,字段之间用制表符分隔。这种格式适用于数据分析任务或将转录结果导入数据库或电子表格。 - output.txt:这是一个纯文本文件,仅包含转录文本,不包含任何时间戳或元数据。这种格式的简单性使其适用于文本内容比时间信息更重要的场景,或者需要由人类或基本文本处理软件读取或处理文本的场景。
- output.vtt:VTT(Web Video Text Tracks)是另一种字幕文件格式,类似于 SRT,但具有更多功能。它是 HTML5 视频标签字幕的标准格式,支持字幕的样式和定位。VTT 格式特别适用于网络视频内容,因为它允许通过可自定义的字幕提供更丰富的观看体验。
这些文件各自服务于不同的用例,从简单的文本文档到详细的分析或视频字幕,提供了转录结果利用的灵活性。
总结
本教程引导你使用 OpenAI Whisper 将媒体文件中的内容转录为文本。从基础开始,我们学习了如何转录一个简单的英语媒体文件。随后,我们进一步探索了优化转录过程的其他功能,例如选择不同的模型和批量处理。Whisper 作为一个多功能工具,能够轻松转录各种媒体文件,表现出色。


