
介绍
本实验主要介绍 Hadoop 的基础知识,面向具有一定 Linux 基础的学生,旨在帮助你理解 Hadoop 软件系统的架构以及基本的部署方法。
请尽量手动输入文档中的所有示例代码,而不是直接复制粘贴。只有这样,你才能更熟悉代码。如果遇到问题,请仔细查阅文档,或者前往论坛寻求帮助和交流。
Hadoop 简介
Apache Hadoop 是一个基于 Apache 2.0 许可证发布的开源软件框架,支持数据密集型分布式应用。
Apache Hadoop 软件库是一个框架,允许通过简单的编程模型在计算集群上分布式处理大规模数据集。它设计为从单台服务器扩展到数千台机器,每台机器提供本地计算和存储,而不是依赖硬件来提供高可用性。
核心概念
Hadoop 项目主要包括以下四个模块:
- Hadoop Common: 一个公共应用程序,为其他 Hadoop 模块提供支持。
- Hadoop 分布式文件系统 (HDFS): 一个分布式文件系统,为应用程序数据提供高吞吐量访问。
- Hadoop YARN: 任务调度和集群资源管理框架。
- Hadoop MapReduce: 基于 YARN 的大规模数据集并行计算框架。
对于 Hadoop 的新用户,你应该重点关注 HDFS 和 MapReduce。作为一个分布式计算框架,HDFS 满足框架对数据的存储需求,而 MapReduce 满足框架对数据的计算需求。
下图展示了 Hadoop 集群的基本架构:
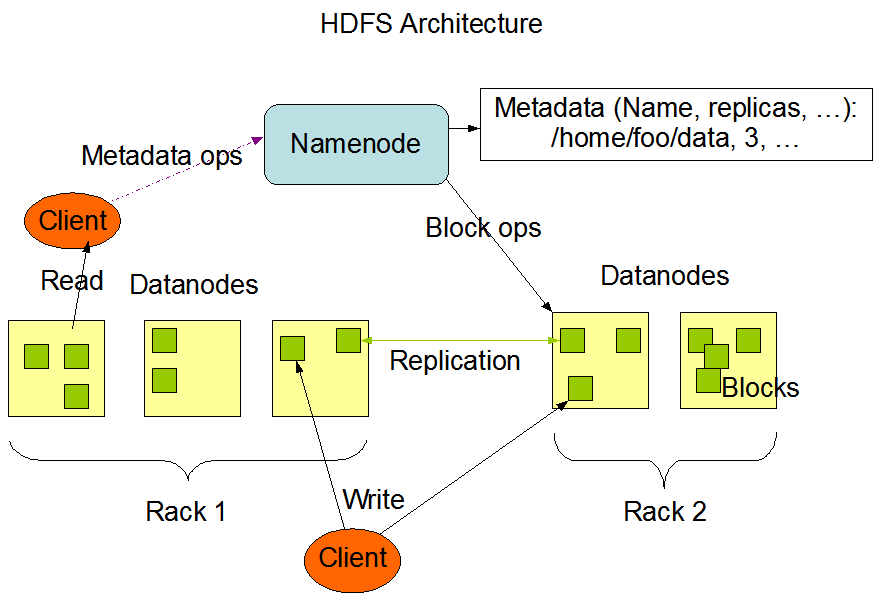
此图引用自 Hadoop 官方网站。
Hadoop 生态系统
正如 Facebook 基于 Hadoop 衍生出了 Hive 数据仓库一样,社区中有许多与之相关的开源项目。以下是一些近期活跃的项目:
- HBase: 一个可扩展的分布式数据库,支持大表的结构化数据存储。
- Hive: 一个数据仓库基础设施,提供数据汇总和临时查询功能。
- Pig: 一种高级数据流语言和执行框架,用于并行计算。
- ZooKeeper: 为分布式应用程序提供高性能协调服务。
- Spark: 一个快速且多功能的 Hadoop 数据计算引擎,具有简单且富有表现力的编程模型,支持数据 ETL(提取、转换和加载)、机器学习、流处理和图形计算。
本实验将从 Hadoop 开始,介绍相关组件的基本用法。
值得注意的是,Spark 是一个分布式内存计算框架,它脱胎于 Hadoop 系统。它对 HDFS 和 YARN 等组件有良好的继承性,同时也改进了 Hadoop 现有的一些不足。
有些人可能会对 Hadoop 和 Spark 的使用场景重叠感到疑惑,但学习 Hadoop 的工作模式和编程模式将有助于加深对 Spark 框架的理解,这也是为什么应该先学习 Hadoop。
Hadoop 的部署
对于初学者来说,Hadoop 2.0 之后的版本差异不大。本节将以 3.3.6 版本为例。
Hadoop 主要有三种部署模式:
- 单机模式: 在单台计算机的单个进程中运行。
- 伪分布式模式: 在单台计算机的多个进程中运行。此模式模拟了单节点下的“多节点”场景。
- 完全分布式模式: 在多台计算机的每个节点上以单个进程运行。
接下来,我们将在单台计算机上安装 Hadoop 3.3.6 版本。
设置用户和用户组
双击打开桌面上的 Xfce 终端,并输入以下命令创建一个名为 hadoop 的用户:
cd ~
sudo adduser hadoop
然后,按照提示输入 hadoop 用户的密码;例如,可以将密码设置为 hadoop。
注意: 输入密码时,命令行中不会有任何提示。输入完成后直接按 Enter 键即可。
接着,将创建的 hadoop 用户添加到 sudo 用户组,以赋予该用户更高的权限:
sudo usermod -G sudo hadoop
通过输入以下命令验证 hadoop 用户是否已添加到 sudo 组:
sudo cat /etc/group | grep hadoop
你应该会看到以下输出:
sudo:x:27:shiyanlou,labex,hadoop
安装 JDK
如前文所述,Hadoop 主要是用 Java 开发的。因此,运行它需要 Java 环境。
不同版本的 Hadoop 对 Java 版本的要求略有不同。要了解你的 Hadoop 应该选择哪个版本的 JDK,可以阅读 Hadoop Wiki 网站上的 Hadoop Java Versions。
切换用户:
su - hadoop
在终端中输入以下命令安装 JDK 11 版本:
sudo apt update
sudo apt install openjdk-11-jdk -y
成功安装后,检查当前的 Java 版本:
java -version
查看输出:
openjdk version "11.0.22" 2024-01-16
OpenJDK Runtime Environment (build 11.0.22+7-post-Ubuntu-0ubuntu222.04.1)
OpenJDK 64-Bit Server VM (build 11.0.22+7-post-Ubuntu-0ubuntu222.04.1, mixed mode, sharing)
配置免密 SSH 登录
安装和配置 SSH 的目的是为了方便 Hadoop 运行与远程管理守护进程相关的脚本。这些脚本需要 sshd 服务。
在配置时,首先切换到 hadoop 用户。在终端中输入以下命令来完成切换:
su hadoop
如果提示需要输入密码,只需输入之前创建用户(hadoop)时指定的密码即可。
成功切换用户后,命令提示符应如上所示。后续步骤将以 hadoop 用户身份执行操作。
接下来生成用于免密 SSH 登录的密钥。
所谓的“免密”是将 SSH 的认证方式从密码登录改为密钥登录,这样 Hadoop 的各个组件在相互访问时无需通过用户交互输入密码,从而减少大量冗余操作。
首先切换到用户的主目录,然后使用 ssh-keygen 命令生成 RSA 密钥。
请在终端中输入以下命令:
cd /home/hadoop
ssh-keygen -t rsa
当遇到密钥存储位置等信息时,可以按 Enter 键使用默认值。
The key's randomart image is:
+---[RSA 3072]----+
| ..+. |
| . = . o |
| .o o * . |
| o .. . + o |
| = +.S. . + |
| + + +++. . |
| . B.O+. |
| o +oXo*E |
| =.+==o. |
+----[SHA256]-----+
密钥生成后,公钥将生成在用户主目录下的 .ssh 目录中。
具体操作如下图所示:
然后继续输入以下命令,将生成的公钥添加到主机认证记录中。为 authorized_keys 文件赋予 写权限,否则在验证期间无法正确执行:
cat .ssh/id_rsa.pub >> .ssh/authorized_keys
chmod 600 .ssh/authorized_keys
添加成功后,尝试登录到 localhost。请在终端中输入以下命令:
ssh localhost
首次登录时,会提示确认公钥指纹,只需输入 yes 并确认即可。之后再次登录时,将实现免密登录:
...
Welcome to Alibaba Cloud Elastic Compute Service !
To run a command as administrator (user "root"), use "sudo <command>".
See "man sudo_root" for details.
hadoop:~$
你需要输入 history -w 或退出终端以保存更改,以便通过验证脚本。
安装 Hadoop
现在,你可以下载 Hadoop 安装包。官方网站提供了最新版本 Hadoop 的下载链接。你也可以在终端中直接使用 wget 命令下载安装包。
在终端中输入以下命令以下载安装包:
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz
下载完成后,可以使用 tar 命令解压安装包:
tar zxvf hadoop-3.3.6.tar.gz
sudo mv hadoop-3.3.6 hadoop
sudo chown -R hadoop:hadoop /home/hadoop
你可以通过在终端中运行 dirname $(dirname $(readlink -f $(which java))) 命令来找到 JAVA_HOME 的位置。
dirname $(readlink -f $(which java))
然后,在终端中使用文本编辑器打开 .zshrc 文件:
vim /home/hadoop/.bashrc
在文件 /home/hadoop/.bashrc 的末尾添加以下内容:
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
export HADOOP_HOME=/home/hadoop/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
保存并退出 vim 编辑器。然后在终端中输入 source 命令以激活新添加的环境变量:
source /home/hadoop/.bashrc
通过在终端中运行 hadoop version 命令来验证安装。
hadoop@iZj6cgdabeniugz9ypibzxZ:~$ hadoop version
Hadoop 3.3.6
Source code repository https://github.com/apache/hadoop.git -r 1be78238728da9266a4f88195058f08fd012bf9c
Compiled by ubuntu on 2023-06-18T08:22Z
Compiled on platform linux-x86_64
Compiled with protoc 3.7.1
From source with checksum 5652179ad55f76cb287d9c633bb53bbd
This command was run using /home/hadoop/hadoop/share/hadoop/common/hadoop-common-3.3.6.jar
伪分布式模式配置
在大多数情况下,Hadoop 用于集群环境,也就是说,我们需要在多个节点上部署 Hadoop。同时,Hadoop 也可以在单个节点上以伪分布式模式运行,通过多个独立的 Java 进程模拟多节点场景。在初学阶段,无需花费大量资源创建不同的节点。因此,本节及后续章节将主要使用伪分布式模式进行 Hadoop“集群”部署。
创建目录
首先,在 Hadoop 用户的主目录中创建 namenode 和 datanode 目录。执行以下命令来创建这些目录:
rm -rf ~/hadoopdata
mkdir -p ~/hadoopdata/hdfs/{namenode,datanode}
然后,你需要修改 Hadoop 的配置文件,使其以伪分布式模式运行。
编辑 core-site.xml
在终端中使用文本编辑器打开 core-site.xml 文件:
vim /home/hadoop/hadoop/etc/hadoop/core-site.xml
在配置文件中,将 configuration 标签的值修改为以下内容:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
fs.defaultFS 配置项用于指示集群默认使用的文件系统位置:
编辑完成后保存文件并退出 vim。
编辑 hdfs-site.xml
打开另一个配置文件 hdfs-site.xml:
vim /home/hadoop/hadoop/etc/hadoop/hdfs-site.xml
在配置文件中,将 configuration 标签的值修改为以下内容:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopdata/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopdata/hdfs/datanode</value>
</property>
</configuration>
此配置项用于指示 HDFS 中文件的副本数量,默认值为 3。由于我们在单个节点上以伪分布式方式部署,因此将其修改为 1:
编辑完成后保存文件并退出 vim。
编辑 hadoop-env.sh
接下来编辑 hadoop-env.sh 文件:
vim /home/hadoop/hadoop/etc/hadoop/hadoop-env.sh
将 JAVA_HOME 的值更改为已安装 JDK 的实际位置,即 /usr/lib/jvm/java-11-openjdk-amd64。
注意: 你可以使用
echo $JAVA_HOME命令检查已安装 JDK 的实际位置。
编辑完成后保存文件并退出 vim 编辑器。
编辑 yarn-site.xml
接下来编辑 yarn-site.xml 文件:
vim /home/hadoop/hadoop/etc/hadoop/yarn-site.xml
在 configuration 标签中添加以下内容:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
编辑完成后保存文件并退出 vim 编辑器。
编辑 mapred-site.xml
最后,你需要编辑 mapred-site.xml 文件。
使用 vim 编辑器打开文件:
vim /home/hadoop/hadoop/etc/hadoop/mapred-site.xml
同样,在 configuration 标签中添加以下内容:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/home/hadoop/hadoop</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/home/hadoop/hadoop</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/home/hadoop/hadoop</value>
</property>
</configuration>
编辑完成后保存文件并退出 vim 编辑器。
Hadoop 启动测试
首先在桌面上打开 Xfce 终端并切换到 Hadoop 用户:
su -l hadoop
HDFS 的初始化主要是格式化:
/home/hadoop/hadoop/bin/hdfs namenode -format
提示:在格式化之前,你需要删除 HDFS 数据目录。
看到以下消息,表示成功:
2024-02-29 18:24:53,887 INFO common.Storage: Storage directory /home/hadoop/hadoopdata/hdfs/namenode has been successfully formatted.
你需要输入 history -w 或退出终端以保存历史记录,以便通过验证脚本。
启动 HDFS
HDFS 初始化完成后,你可以启动 NameNode 和 DataNode 的守护进程。启动后,Hadoop 应用程序(例如 MapReduce 任务)可以从 HDFS 读取和写入文件。
在终端中输入以下命令以启动守护进程:
/home/hadoop/hadoop/sbin/start-dfs.sh
查看输出:
Starting namenodes on [localhost]
Starting datanodes
Starting secondary namenodes [iZj6cjditp4l7k0fylhhfbZ]
iZj6cjditp4l7k0fylhhfbZ: Warning: Permanently added 'izj6cjditp4l7k0fylhhfbz' (ED25519) to the list of known hosts.
为了确认 Hadoop 是否以伪分布式模式成功运行,你可以使用 Java 的进程查看工具 jps 来检查是否存在相应的进程。
在终端中输入以下命令:
jps
如图所示,如果你看到 NameNode、DataNode 和 SecondaryNameNode 的进程,则表明 Hadoop 服务运行正常:
查看日志文件和 WebUI
当 Hadoop 启动失败或任务(或其他操作)运行时报告错误时,除了终端的提示信息外,查看日志是定位问题的最佳方式。大多数问题都可以通过相关软件的日志找到原因和解决方案。作为大数据领域的学习者,分析日志的能力与学习计算框架的能力同样重要,应予以重视。
Hadoop 守护进程日志的默认输出位于安装目录下的日志目录(logs)中。在终端中输入以下命令以进入日志目录:
ls /home/hadoop/hadoop/logs
hadoop-hadoop-datanode-iZj6cjditp4l7k0fylhhfbZ.log
hadoop-hadoop-datanode-iZj6cjditp4l7k0fylhhfbZ.out
hadoop-hadoop-namenode-iZj6cjditp4l7k0fylhhfbZ.log
hadoop-hadoop-namenode-iZj6cjditp4l7k0fylhhfbZ.out
hadoop-hadoop-secondarynamenode-iZj6cjditp4l7k0fylhhfbZ.log
hadoop-hadoop-secondarynamenode-iZj6cjditp4l7k0fylhhfbZ.out
SecurityAuth-hadoop.audit
你可以使用 vim 编辑器查看任何日志文件。
HDFS 启动后,内部 Web 服务还会提供一个显示集群状态的网页。切换到 LabEx VM 的顶部,点击“Web 8088”以打开网页:
打开网页后,你可以看到集群的概览、DataNode 的状态等信息:
随意点击页面顶部的菜单,探索提示和功能。
你需要输入 history -w 或退出终端以保存历史记录,以便通过验证脚本。
HDFS 文件上传测试
HDFS 运行后,可以将其视为一个文件系统。为了测试文件上传功能,你需要创建一个目录(逐级创建,直到所需的目录层级),并尝试将 Linux 系统中的一些文件上传到 HDFS:
cd ~
/home/hadoop/hadoop/bin/hdfs dfs -mkdir /user
/home/hadoop/hadoop/bin/hdfs dfs -mkdir /user/hadoop
目录成功创建后,使用 hdfs dfs -put 命令将本地磁盘上的文件(这里随机选择 Hadoop 配置文件)上传到 HDFS:
/home/hadoop/hadoop/bin/hdfs dfs -put /home/hadoop/hadoop/etc/hadoop /user/hadoop/input
PI 测试用例
在实际生产环境中部署并解决实际问题的绝大多数 Hadoop 应用程序都基于以 WordCount 为代表的 MapReduce 编程模型。因此,WordCount 可以作为入门 Hadoop 的“HelloWorld”程序,或者你可以加入自己的想法来解决特定问题。
启动任务
在上一节的最后,我们上传了一些配置文件到 HDFS 作为示例。接下来,我们可以尝试运行 PI 测试用例,以获取这些文件的词频统计,并根据我们的过滤规则输出结果。
首先在终端中启动 YARN 计算服务:
/home/hadoop/hadoop/sbin/start-yarn.sh
然后输入以下命令以启动任务:
/home/hadoop/hadoop/bin/hadoop jar /home/hadoop/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar pi 3 3
查看输出结果:
Estimated value of Pi is 3.55555555555555555556
在上述参数中,有三个关于路径的参数。它们分别是:jar 包的位置、输入文件的位置以及输出结果的存储位置。在指定路径时,应养成使用绝对路径的习惯。这将有助于快速定位问题并提高工作效率。
完成任务后,你可以查看结果。
关闭 HDFS 服务
计算完成后,如果没有其他软件程序使用 HDFS 上的文件,应及时关闭 HDFS 守护进程。
作为分布式集群及相关计算框架的用户,你应该养成每次涉及集群开关、硬件和软件安装或任何更新时,主动检查相关硬件和软件状态的良好习惯。
在终端中使用以下命令关闭 HDFS 和 YARN 守护进程:
/home/hadoop/hadoop/sbin/stop-yarn.sh
/home/hadoop/hadoop/sbin/stop-dfs.sh
你需要输入 history -w 或退出终端以保存历史记录,以便通过验证脚本。
总结
本实验介绍了 Hadoop 的架构、单机模式和伪分布式模式的安装与部署方法,并通过运行 WordCount 进行了基本测试。
以下是本实验的主要内容:
- Hadoop 架构
- Hadoop 主要模块
- 如何使用 Hadoop 单机模式
- Hadoop 伪分布式模式部署
- HDFS 的基本使用
- WordCount 测试用例
总的来说,Hadoop 是大数据领域中常用的计算和存储框架,其功能需要进一步探索。请保持查阅技术资料的习惯,并继续学习后续内容。


