
Introdução
Neste laboratório, você aprenderá os fundamentos da construção de um modelo de aprendizado de máquina (machine learning) usando uma das bibliotecas Python mais populares, o scikit-learn. Focaremos na Regressão Linear, um algoritmo básico, porém poderoso, usado para prever valores contínuos, como preços ou temperaturas.
Nosso objetivo é construir um modelo capaz de prever os preços médios de imóveis em distritos da Califórnia. Utilizaremos o conjunto de dados de habitação da Califórnia, que já vem convenientemente incluído no scikit-learn.
Ao longo deste laboratório, você aprenderá a:
- Carregar um conjunto de dados do
scikit-learn. - Preparar e dividir os dados para treinamento e teste.
- Criar e treinar um modelo de Regressão Linear.
- Usar o modelo treinado para fazer previsões.
- Visualizar os resultados para entender o desempenho do modelo.
Você realizará todas as tarefas dentro do WebIDE. Vamos começar!
Carregar o conjunto de dados de habitação da Califórnia com datasets.fetch_california_housing()
Nesta etapa, começaremos carregando o conjunto de dados para o nosso modelo. O scikit-learn vem com vários conjuntos de dados integrados, que são excelentes para aprendizado e prática. Usaremos o conjunto de dados de habitação da Califórnia.
Primeiro, precisamos criar um script Python. Um arquivo chamado main.py já foi criado para você no diretório ~/project. Você pode encontrá-lo no explorador de arquivos no lado esquerdo do WebIDE.
Abra o main.py e adicione o código a seguir. Este código importa as bibliotecas necessárias (fetch_california_housing do sklearn.datasets e pandas) e carrega o conjunto de dados. Usaremos o pandas para converter os dados em um DataFrame, que é uma estrutura de dados tabular fácil de visualizar e manipular.
Por favor, adicione o seguinte código ao main.py:
import pandas as pd
from sklearn.datasets import fetch_california_housing
## Load the California housing dataset
california = fetch_california_housing()
## Create a DataFrame
california_df = pd.DataFrame(california.data, columns=california.feature_names)
california_df['MedHouseVal'] = california.target
## Print the first 5 rows of the DataFrame
print("California Housing Dataset:")
print(california_df.head())
Agora, vamos executar o script para ver a saída. Abra um terminal no WebIDE (você pode usar o menu "Terminal" -> "New Terminal") e execute o seguinte comando:
python3 main.py
Você deverá ver as cinco primeiras linhas do conjunto de dados impressas no console. A coluna MedHouseVal é nossa variável alvo, representando o valor médio da casa para os distritos da Califórnia, expresso em centenas de milhares de dólares ($100.000).
California Housing Dataset:
MedInc HouseAge AveRooms AveBedrms Population AveOccup Latitude Longitude MedHouseVal
0 8.3252 41.0 6.984127 1.023810 322.0 2.555556 37.88 -122.23 4.526
1 8.3014 21.0 6.238137 0.971880 2401.0 2.109842 37.86 -122.22 3.585
2 7.2574 52.0 8.288136 1.073446 496.0 2.802260 37.85 -122.24 3.521
3 5.6431 52.0 5.817352 1.073059 558.0 2.547945 37.85 -122.25 3.413
4 3.8462 52.0 6.281853 1.081081 565.0 2.181467 37.85 -122.25 3.422
Dividir os dados em treino e teste usando train_test_split do sklearn.model_selection
Nesta etapa, prepararemos nossos dados para o processo de treinamento. Uma parte crucial do aprendizado de máquina é avaliar o modelo em dados que ele nunca viu antes. Para fazer isso, dividimos nosso conjunto de dados em duas partes: um conjunto de treinamento e um conjunto de teste. O modelo aprenderá com o conjunto de treinamento, e usaremos o conjunto de teste para verificar seu desempenho.
Primeiro, precisamos separar nossas características (as variáveis de entrada, X) do nosso alvo (o valor que queremos prever, y). No nosso caso, X serão todas as colunas, exceto MedHouseVal, e y será a coluna MedHouseVal.
Em seguida, usaremos a função train_test_split do sklearn.model_selection para realizar a divisão.
Adicione o seguinte código ao seu arquivo main.py:
from sklearn.model_selection import train_test_split
## Prepare the data
X = california_df.drop('MedHouseVal', axis=1) ## Features (input variables)
y = california_df['MedHouseVal'] ## Target variable (what we want to predict)
## Split the data into training and testing sets
## test_size=0.2: Reserve 20% of data for testing, 80% for training
## random_state=42: Ensures reproducible splits (same result every run)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
## Print the shapes of the new datasets to confirm the split
print("\n--- Data Split ---")
print("X_train shape:", X_train.shape) ## Training features
print("X_test shape:", X_test.shape) ## Test features
print("y_train shape:", y_train.shape) ## Training target values
print("y_test shape:", y_test.shape) ## Test target values
Agora, execute o script novamente a partir do terminal:
python3 main.py
Você verá as formas (shapes) dos conjuntos de treinamento e teste recém-criados impressas abaixo do DataFrame. Isso confirma que os dados foram divididos corretamente.
--- Data Split ---
X_train shape: (16512, 8)
X_test shape: (4128, 8)
y_train shape: (16512,)
y_test shape: (4128,)
Inicializar o modelo LinearRegression do sklearn.linear_model
Nesta etapa, criaremos nosso modelo de Regressão Linear. O scikit-learn torna isso incrivelmente simples. Só precisamos importar a classe LinearRegression do módulo sklearn.linear_model e criar uma instância dela.
Essa instância é um objeto que contém o algoritmo de regressão linear. A regressão linear encontra a linha de melhor ajuste através dos pontos de dados, usando a fórmula: y = mx + b, onde m são os coeficientes (pesos) para cada característica e b é o intercepto. Aqui, usamos os parâmetros padrão, que funcionam bem para a maioria dos casos básicos.
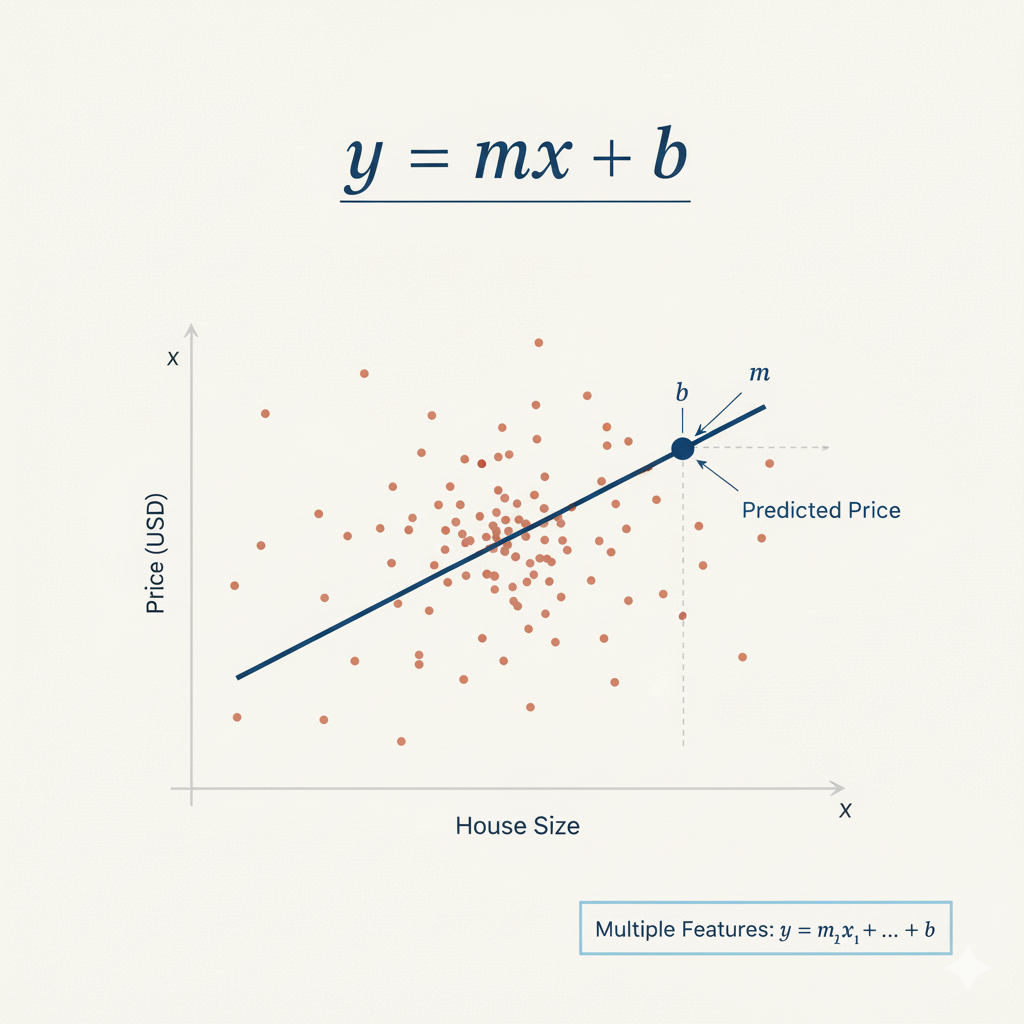 Figura 1: Fórmula da regressão linear y = mx + b, onde m é a inclinação e b é o intercepto
Figura 1: Fórmula da regressão linear y = mx + b, onde m é a inclinação e b é o intercepto
Adicione o seguinte código ao seu arquivo main.py. Isso importará a classe LinearRegression e criará um objeto de modelo.
from sklearn.linear_model import LinearRegression
## Initialize the Linear Regression model
model = LinearRegression()
## Print the model to confirm it's created
print("\n--- Model Initialized ---")
print(model)
Execute seu script main.py novamente a partir do terminal:
python3 main.py
A saída agora incluirá uma linha mostrando o objeto LinearRegression. Isso confirma que o modelo foi inicializado com sucesso.
--- Model Initialized ---
LinearRegression()
Ajustar o modelo com model.fit(X_train, y_train)
Nesta etapa, treinaremos nosso modelo. Esse processo é frequentemente chamado de "ajustar" (fitting) o modelo aos dados. Durante o ajuste, o modelo aprende as relações entre as características (X_train) e a variável alvo (y_train). Para a regressão linear, isso significa encontrar os coeficientes ideais para cada característica para prever melhor o alvo.
Usaremos o método fit() do nosso objeto de modelo, passando nossos dados de treinamento como argumentos.
Adicione o seguinte código ao seu arquivo main.py:
## Fit (train) the model on the training data
## The fit() method learns the relationship between features (X_train) and target (y_train)
## It calculates optimal coefficients for each feature and the intercept using least squares optimization
model.fit(X_train, y_train)
## After fitting, the model has learned the coefficients and intercept.
## The intercept represents the predicted value when all features are zero
print("\n--- Model Trained ---")
print("Intercept:", model.intercept_)
Agora, execute o script a partir do terminal:
python3 main.py
Após a execução do script, você verá uma nova seção na saída mostrando o intercepto do modelo de regressão linear. O intercepto é o valor da previsão quando todos os valores das características são zero. Ver um valor numérico aqui confirma que o modelo foi treinado com sucesso nos dados.
--- Model Trained ---
Intercept: -37.023277706064185
Prever nos dados de teste com model.predict(X_test)
Nesta etapa final, usaremos nosso modelo treinado para fazer previsões. Este é o objetivo final da construção de um modelo preditivo. Usaremos os dados de teste (X_test), que o modelo não viu durante o treinamento, para avaliar seu desempenho.
Usaremos o método predict() do nosso objeto de modelo treinado, passando as características de teste (X_test) como argumento. O método retornará uma matriz de valores previstos para a variável alvo.
Adicione o seguinte código ao seu arquivo main.py:
## Make predictions on the test data
## The predict() method uses the learned coefficients and intercept to calculate predictions
## Formula: prediction = intercept + (coeff1 * feature1) + (coeff2 * feature2) + ...
predictions = model.predict(X_test)
## Print the first 5 predictions (values are in $100,000 units)
print("\n--- Predictions ---")
print(predictions[:5])
Agora, execute o script completo mais uma vez a partir do terminal:
python3 main.py
A saída agora incluirá os cinco primeiros preços de casas previstos para o conjunto de teste. Esses valores são o que nosso modelo acredita que os valores médios das casas deveriam ser, com base nas características em X_test. Você pode comparar conceitualmente essas previsões com os valores reais em y_test para avaliar a precisão do modelo.
--- Predictions ---
[0.71912284 1.76401657 2.70965883 2.83892593 2.60465725]
Parabéns! Você construiu, treinou e usou com sucesso um modelo de regressão linear com scikit-learn.
Visualizar as previsões do modelo usando matplotlib.pyplot.scatter()
Nesta etapa final, criaremos uma visualização para entender melhor o desempenho do nosso modelo. A visualização é crucial no aprendizado de máquina, pois nos ajuda a ver padrões e relações que podem não ser óbvios apenas com números brutos.
Criaremos um gráfico de dispersão (scatter plot) que compara os preços reais das casas (y_test) com as previsões do nosso modelo. Esse tipo de gráfico é chamado de gráfico de "previsões vs reais". Se nosso modelo fosse perfeito, todos os pontos estariam em uma linha diagonal (linha de 45 graus) onde os valores previstos são iguais aos valores reais.
Usaremos o matplotlib para criar essa visualização e salvá-la como um arquivo de imagem.
Adicione o seguinte código ao seu arquivo main.py:
import matplotlib.pyplot as plt
## Create a scatter plot comparing actual vs predicted values
plt.figure(figsize=(10, 6))
plt.scatter(y_test, predictions, alpha=0.5, color='blue', edgecolors='black')
## Add a diagonal line showing perfect predictions (where predicted = actual)
plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()],
'r--', linewidth=2, label='Perfect Prediction')
## Add labels and title
plt.xlabel('Actual House Prices ($100,000)')
plt.ylabel('Predicted House Prices ($100,000)')
plt.title('Linear Regression: Actual vs Predicted House Prices')
plt.legend()
plt.grid(True, alpha=0.3)
## Save the plot to a file
plt.savefig('housing_predictions.png', dpi=300, bbox_inches='tight')
plt.close()
print("\n--- Visualization Complete ---")
print("Plot saved to housing_predictions.png")
Agora, execute o script completo a partir do terminal:
python3 main.py
Você verá uma mensagem de confirmação de que o gráfico foi salvo.
--- Visualization Complete ---
Plot saved to housing_predictions.png
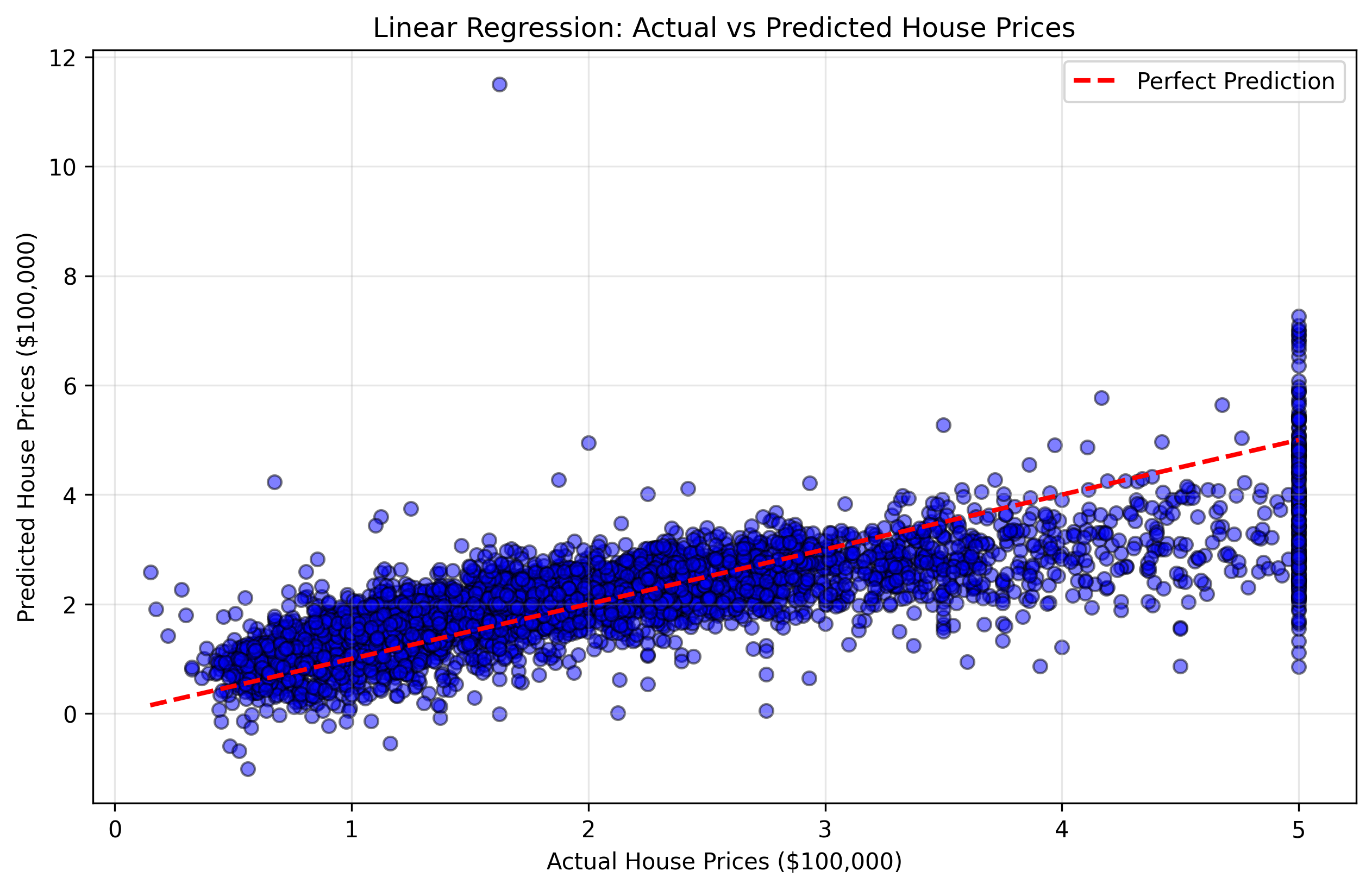 Figura 2: Gráfico de dispersão mostrando os preços reais vs previstos das casas. Pontos mais próximos da linha diagonal vermelha indicam melhores previsões.
Figura 2: Gráfico de dispersão mostrando os preços reais vs previstos das casas. Pontos mais próximos da linha diagonal vermelha indicam melhores previsões.
Esta visualização o ajudará a entender:
- Pontos próximos à linha diagonal: Boas previsões onde o modelo foi preciso.
- Pontos distantes da linha diagonal: Previsões ruins onde o modelo cometeu erros maiores.
- Padrão geral: Se o modelo tende a superestimar ou subestimar certas faixas de preço.
Você pode clicar duas vezes no arquivo housing_predictions.png no explorador de arquivos para visualizar seu gráfico.
Parabéns! Você construiu, treinou, testou e visualizou com sucesso um modelo de regressão linear com scikit-learn.
Resumo
Neste laboratório, você completou todo o fluxo de trabalho para construir um modelo básico de aprendizado de máquina usando o scikit-learn.
Você começou carregando o conjunto de dados de habitação da Califórnia e preparando-o usando o pandas. Em seguida, aprendeu a importância de dividir seus dados em conjuntos de treinamento e teste e realizou a divisão usando train_test_split.
Depois disso, você inicializou um modelo LinearRegression, treinou-o em seus dados de treinamento usando o método fit(), usou o modelo treinado para fazer previsões em dados de teste não vistos com o método predict() e, finalmente, visualizou os resultados para entender o desempenho do seu modelo.
Este laboratório fornece uma base sólida em scikit-learn. A partir daqui, você pode explorar tópicos mais avançados, como:
- Avaliação de modelo: Calcular métricas como Erro Quadrático Médio (MSE) ou R-quadrado para medir a precisão do modelo.
- Visualização de dados: Criar gráficos mais avançados, como gráficos de resíduos, gráficos de importância de características ou matrizes de correlação.
- Escalonamento de características: Padronizar ou normalizar características para um melhor desempenho.
- Regularização: Usar regressão Ridge ou Lasso para evitar o sobreajuste (overfitting).
- Validação cruzada: Avaliação mais robusta usando validação cruzada k-fold.
- Outros algoritmos: Experimentar Random Forest, Support Vector Machines ou Redes Neurais.


