
Introdução
Bem-vindo a este laboratório prático sobre classificação K-Nearest Neighbors (KNN) usando scikit-learn! Scikit-learn é uma biblioteca Python poderosa e popular para aprendizado de máquina. O algoritmo KNN é um dos algoritmos de classificação mais simples, porém eficazes. Ele classifica um novo ponto de dados com base na classe majoritária de seus 'k' vizinhos mais próximos no espaço de características. Neste laboratório, você percorrerá o processo completo de construção de um modelo de aprendizado de máquina: carregando o famoso conjunto de dados Iris, dividindo-o em conjuntos de treinamento e teste, inicializando e treinando um classificador KNN e, finalmente, usando o modelo treinado para fazer previsões em dados novos e não vistos. Ao final deste laboratório, você terá uma compreensão sólida do fluxo de trabalho fundamental para aprendizado supervisionado em scikit-learn.
Carregar o dataset Iris com datasets.load_iris()
Nesta etapa, você começará carregando o conjunto de dados necessário. Usaremos o clássico conjunto de dados Iris, que está convenientemente incluído no scikit-learn. Primeiro, você precisa importar o módulo datasets do sklearn. Em seguida, chamará a função load_iris() para obter os dados.
Entendendo load_iris():
- Tipo de retorno: Retorna um objeto
Bunch(semelhante a um dicionário) contendo:.data: Matriz de características (150 amostras × 4 características: comprimento da sépala, largura da sépala, comprimento da pétala, largura da pétala).target: Array de rótulos (espécies: 0=setosa, 1=versicolor, 2=virginica).feature_names: Nomes das 4 características.target_names: Nomes das 3 espécies
- Propósito: Fornece um conjunto de dados limpo e pronto para uso para prática de classificação
Atribuiremos esses a variáveis X e y, respectivamente, que é uma convenção comum em aprendizado de máquina (X para características, y para rótulos).
Abra o arquivo main.py no editor à esquerda e adicione o seguinte código.
from sklearn import datasets
## Load the iris dataset
iris = datasets.load_iris()
## Assign features to X and labels to y
X = iris.data
y = iris.target
## You can print the shape to see the dimensions
print("Features shape:", X.shape)
print("Labels shape:", y.shape)
Agora, execute o script a partir do terminal para ver a saída.
python3 main.py
Você deverá ver as dimensões da matriz de características e do vetor de rótulos.
Features shape: (150, 4)
Labels shape: (150,)
Isso nos diz que temos 150 amostras (flores) e 4 características para cada amostra.
Dividir dados em treino e teste usando train_test_split de sklearn.model_selection
Nesta etapa, você dividirá o conjunto de dados em duas partes: um conjunto de treinamento e um conjunto de teste. Esta é uma etapa crucial no aprendizado de máquina para avaliar o desempenho de um modelo em dados não vistos.
Entendendo os parâmetros de train_test_split():
test_size=0.3: Reserva 30% dos dados para teste, 70% para treinamentorandom_state=42: Garante divisões reproduzíveis (a mesma semente aleatória a cada execução)- Propósito: Previne o overfitting (sobreajuste) avaliando o modelo em dados não vistos
- Saída: Retorna quatro arrays: X_train, X_test, y_train, y_test
Treinamos o modelo no conjunto de treinamento e, em seguida, testamos seu poder preditivo no conjunto de teste. O Scikit-learn fornece uma função útil chamada train_test_split para esse fim. Você precisa importá-la de sklearn.model_selection.
Adicione o seguinte código ao final do seu arquivo main.py.
from sklearn.model_selection import train_test_split
## Split data into training and testing sets
## test_size=0.3 means 30% of the data will be used for testing
## random_state ensures reproducibility
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
## Print the shapes of the new sets
print("X_train shape:", X_train.shape)
print("X_test shape:", X_test.shape)
Agora, execute o script novamente.
python3 main.py
A saída agora incluirá as dimensões dos seus conjuntos de treinamento e teste.
Features shape: (150, 4)
Labels shape: (150,)
X_train shape: (105, 4)
X_test shape: (45, 4)
Inicializar KNeighborsClassifier com n_neighbors=3 de sklearn.neighbors
Nesta etapa, você inicializará o classificador K-Nearest Neighbors (KNN). A ideia central do KNN é prever a classe de um ponto de dados observando as classes de seus 'k' vizinhos mais próximos.
Entendendo os parâmetros de KNeighborsClassifier():
n_neighbors=3: Número de vizinhos mais próximos a serem considerados para a previsão- Valores menores (por exemplo, 1-3): Mais sensível a ruído, pode ocorrer overfitting
- Valores maiores (por exemplo, 5-7): Limites de decisão mais suaves, mais robusto
- Comportamento do algoritmo: Para previsão, encontra os k pontos de treinamento mais próximos e usa votação majoritária
- Sem fase de treinamento: KNN é um "aprendiz preguiçoso" (lazy learner) - ele armazena os dados de treinamento e computa durante a previsão
O KNeighborsClassifier é a classe no scikit-learn que implementa este algoritmo. Você precisa importá-lo de sklearn.neighbors. Vamos criar um objeto classificador e nomeá-lo clf.
Adicione o seguinte código ao final do seu arquivo main.py.
from sklearn.neighbors import KNeighborsClassifier
## Initialize the KNN classifier with n_neighbors=3
clf = KNeighborsClassifier(n_neighbors=3)
Este código não produz nenhuma saída, mas cria o objeto classificador na memória, pronto para ser treinado na próxima etapa.
Ajustar o classificador com clf.fit(X_train, y_train)
Nesta etapa, você treinará, ou 'ajustará' (fit), o classificador usando seus dados de treinamento. Para o algoritmo KNN, a fase de 'treinamento' é muito simples: ela envolve apenas o armazenamento de todo o conjunto de dados de treinamento (X_train e y_train).
Entendendo o método .fit():
- Parâmetros de entrada:
X_train(matriz de características),y_train(rótulos alvo) - O que faz: Armazena os dados de treinamento na memória para uso posterior durante a previsão
- Especificidade do KNN: Ao contrário de outros algoritmos, o KNN não aprende parâmetros durante o ajuste (fit)
- Propósito: Prepara o modelo para fazer previsões em novos dados
Quando uma previsão é necessária para um novo ponto, o algoritmo encontra os 'k' pontos mais próximos neste conjunto de dados armazenado e toma uma decisão. Para treinar o modelo no scikit-learn, você usa o método .fit() do objeto classificador. O método recebe as características de treinamento (X_train) e os rótulos de treinamento correspondentes (y_train) como argumentos.
Adicione a seguinte linha de código ao final de main.py.
## Train the classifier using the training data
clf.fit(X_train, y_train)
print("Classifier trained successfully.")
Após adicionar o código, execute o script.
python3 main.py
Você verá uma mensagem de confirmação de que o classificador foi treinado.
Features shape: (150, 4)
Labels shape: (150,)
X_train shape: (105, 4)
X_test shape: (45, 4)
Classifier trained successfully.
Prever classes com clf.predict(X_test)
Nesta etapa final, você usará o classificador treinado para fazer previsões nos dados de teste. Agora que o modelo 'aprendeu' com os dados de treinamento, podemos fornecer a ele as características do conjunto de teste (X_test), que ele nunca viu antes, e pedir para prever a classe para cada amostra.
Entendendo o método .predict():
- Parâmetro de entrada:
X_test(matriz de características de dados não vistos) - Processo do algoritmo: Para cada amostra de teste, encontra os k vizinhos mais próximos nos dados de treinamento e usa votação majoritária
- Saída: Array de rótulos de classe previstos (mesmo comprimento das amostras de entrada)
- Métrica de distância: Usa a distância Euclidiana por padrão para medir a similaridade entre os pontos
- Propósito: Avalia o desempenho do modelo em dados novos e não vistos
Isso é feito usando o método .predict(). O método recebe as características de teste (X_test) como entrada e retorna um array de rótulos previstos. Armazenaremos essas previsões em uma variável chamada predictions e as imprimiremos no console. Você também pode imprimir os rótulos reais (y_test) para ver o quão bem o modelo se saiu.
Adicione a última parte do código ao seu arquivo main.py.
## Make predictions on the test data
predictions = clf.predict(X_test)
print("Predictions on test data:", predictions)
print("Actual labels of test data:", y_test)
Agora, execute o script completo.
python3 main.py
Você verá o array de rótulos de classe previstos para o conjunto de teste, seguido pelo array dos rótulos verdadeiros.
... (previous output) ...
Classifier trained successfully.
Predictions on test data: [1 0 2 1 1 0 1 2 1 1 2 0 0 0 0 1 2 1 1 2 0 2 0 2 2 2 2 2 0 0 0 0 1 0 0 2 1
0 0 0 2 1 1 0 0]
Actual labels of test data: [1 0 2 1 1 0 1 2 1 1 2 0 0 0 0 1 2 1 1 2 0 2 0 2 2 2 2 2 0 0 0 0 1 0 0 2 1
0 0 0 2 1 1 0 0]
Nota: Os arrays de saída são mostrados na íntegra aqui. Ao comparar os dois arrays, você pode ver que as previsões correspondem perfeitamente aos rótulos reais, indicando um excelente desempenho do modelo neste conjunto de teste.
Visualizar Resultados da Classificação KNN
Nesta etapa bônus, você criará visualizações para entender melhor seus resultados de classificação KNN. A visualização ajuda você a ver o quão bem seu modelo se saiu e a entender os limites de decisão criados pelo algoritmo KNN.
Entendendo a visualização de dados em classificação:
- Gráficos de dispersão (Scatter plots): Mostram as relações entre as características e como as classes são distribuídas
- Codificação por cores: Cores diferentes representam classes diferentes (espécies)
- Dados de treinamento vs. teste: Ajuda a entender a generalização do modelo
- Precisão da previsão: Comparação visual de rótulos previstos vs. reais
Adicione o seguinte código ao final do seu arquivo main.py para criar visualizações:
import matplotlib.pyplot as plt
import numpy as np
## Create subplots for multiple visualizations
fig, axes = plt.subplots(1, 2, figsize=(15, 6))
## Plot 1: Training data with different colors for each class
scatter1 = axes[0].scatter(X_train[:, 0], X_train[:, 1], c=y_train, cmap='viridis', alpha=0.7, s=50)
axes[0].set_xlabel('Sepal Length (cm)')
axes[0].set_ylabel('Sepal Width (cm)')
axes[0].set_title('Training Data Distribution')
axes[0].legend(*scatter1.legend_elements(), title="Classes")
## Plot 2: Test data predictions vs actual labels
## Create a comparison: correct predictions vs incorrect ones
test_predictions = clf.predict(X_test)
correct_predictions = (test_predictions == y_test)
## Plot correct predictions
correct_mask = correct_predictions
scatter2_correct = axes[1].scatter(X_test[correct_mask, 0], X_test[correct_mask, 1],
c=y_test[correct_mask], cmap='viridis', alpha=0.7, s=50, marker='o')
## Plot incorrect predictions with different marker
incorrect_mask = ~correct_predictions
if np.any(incorrect_mask):
scatter2_incorrect = axes[1].scatter(X_test[incorrect_mask, 0], X_test[incorrect_mask, 1],
c=test_predictions[incorrect_mask], cmap='viridis',
alpha=0.7, s=80, marker='x', edgecolors='red', linewidths=2)
axes[1].set_xlabel('Sepal Length (cm)')
axes[1].set_ylabel('Sepal Width (cm)')
axes[1].set_title('Test Data: Predictions vs Actual\n(correct=●, incorrect=✕)')
## Create legend
legend_elements = [plt.Line2D([0], [0], marker='o', color='w', markerfacecolor='gray', markersize=8, label='Correct'),
plt.Line2D([0], [0], marker='x', color='red', markersize=8, label='Incorrect')]
axes[1].legend(handles=legend_elements)
plt.tight_layout()
plt.savefig('knn_classification_results.png', dpi=150, bbox_inches='tight')
print("Visualization saved to knn_classification_results.png")
## Additional: Show prediction accuracy
accuracy = np.mean(correct_predictions) * 100
print(f"Model Accuracy: {accuracy:.1f}%")
Execute o script atualizado:
python3 main.py
Você deverá ver uma saída incluindo:
... (previous output) ...
Visualization saved to knn_classification_results.png
Model Accuracy: 100.0%
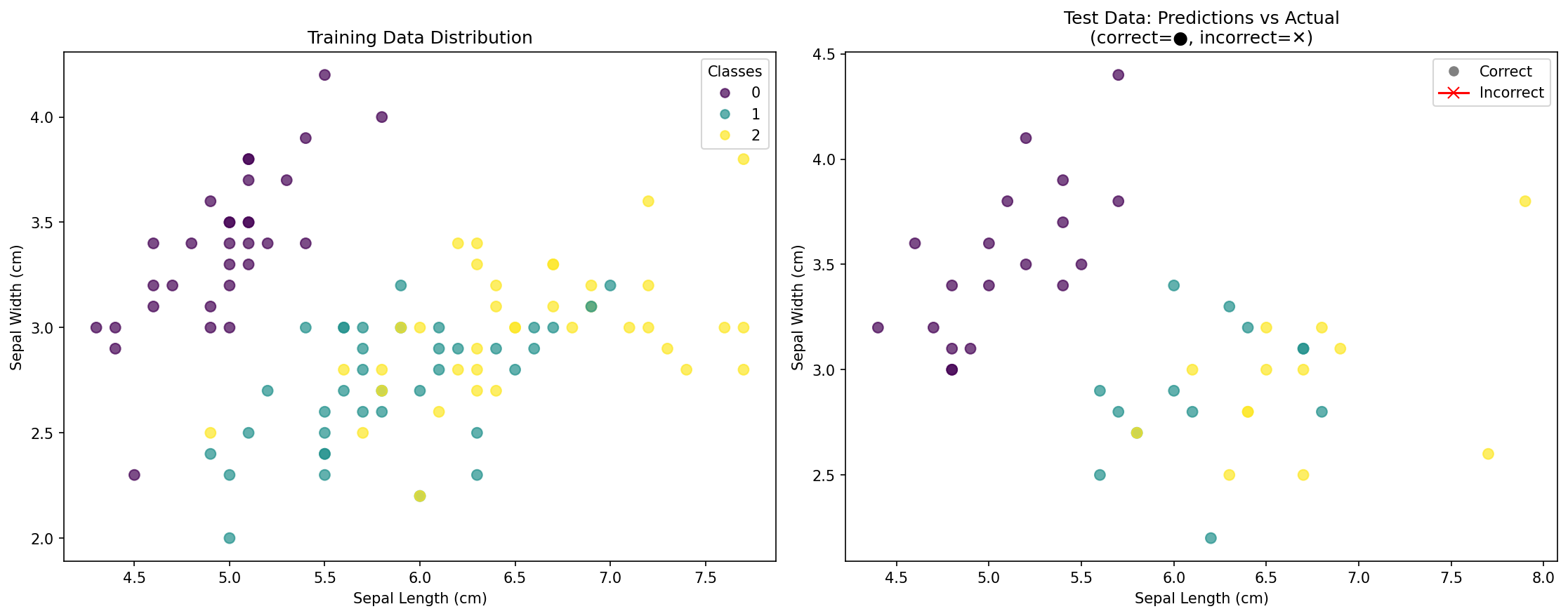
O que a visualização mostra:
- Gráfico da esquerda: Distribuição dos pontos de dados de treinamento, coloridos por sua espécie real
- Gráfico da direita: Pontos de dados de teste mostrando:
- Círculos (●): Pontos classificados corretamente
- Cruzes (✕): Pontos classificados incorretamente (se houver)
- Pontuação de precisão: Porcentagem geral de previsões corretas
Esta visualização ajuda você a entender:
- Como as classes são distribuídas no espaço de características
- Se o seu modelo está com overfitting (sobreajuste) ou generalizando bem
- Quais áreas podem ser desafiadoras para a classificação
- A eficácia do seu modelo KNN visualmente
Resumo
Parabéns por completar este laboratório! Você construiu e treinou com sucesso um modelo de classificação K-Nearest Neighbors (KNN) usando scikit-learn. Você aprendeu o fluxo de trabalho fundamental de um projeto de aprendizado de máquina supervisionado, que inclui:
- Carregar um conjunto de dados usando
sklearn.datasets. - Dividir os dados em conjuntos de treinamento e teste com
train_test_split. - Inicializar um classificador, neste caso,
KNeighborsClassifier. - Treinar o modelo nos dados de treinamento usando o método
.fit(). - Fazer previsões em dados novos e não vistos usando o método
.predict(). - Visualizar resultados para entender o desempenho do modelo e os padrões de decisão.
Este processo forma a base para muitas tarefas de aprendizado de máquina. A partir daqui, você pode explorar como avaliar o desempenho do seu modelo de forma mais formal usando métricas como precisão (accuracy), precisão (precision) e recall, ou experimentar diferentes valores para n_neighbors para ver como isso afeta o resultado. Você também pode tentar visualizar os limites de decisão ou usar diferentes métricas de distância no seu classificador KNN.


