
Introdução
Neste laboratório, exploraremos a criação de tabelas e tipos de dados no PostgreSQL. O objetivo é entender os tipos de dados fundamentais, como inteiros, texto, datas e booleanos, que são cruciais para definir estruturas de tabelas e garantir a integridade dos dados.
Conectaremos ao banco de dados PostgreSQL usando psql, criaremos tabelas com chaves primárias usando SERIAL e adicionaremos restrições básicas como NOT NULL e UNIQUE. Em seguida, inspecionaremos a estrutura da tabela e inseriremos dados para demonstrar o uso de diferentes tipos de dados como INTEGER, SMALLINT, TEXT, VARCHAR(n) e CHAR(n).
Explorar os Tipos de Dados do PostgreSQL
Nesta etapa, exploraremos alguns dos tipos de dados fundamentais disponíveis no PostgreSQL. Compreender os tipos de dados é crucial para definir estruturas de tabelas e garantir a integridade dos dados. Abordaremos tipos comuns como inteiros, texto, datas e booleanos.
Primeiro, vamos conectar ao banco de dados PostgreSQL. Abra um terminal e use o comando psql para conectar ao banco de dados postgres como o usuário postgres. Como o usuário postgres é o superusuário padrão, pode ser necessário usar sudo para mudar para esse usuário primeiro.
sudo -u postgres psql
Você deve estar agora no terminal interativo do PostgreSQL. Você verá um prompt como postgres=#.
Agora, vamos explorar alguns tipos de dados básicos.
1. Tipos Inteiros:
O PostgreSQL oferece vários tipos inteiros com diferentes intervalos. Os mais comuns são INTEGER (ou INT) e SMALLINT.
INTEGER: Uma escolha típica para a maioria dos valores inteiros.SMALLINT: Usado para valores inteiros menores para economizar espaço.
Vamos criar uma tabela simples para demonstrar esses tipos:
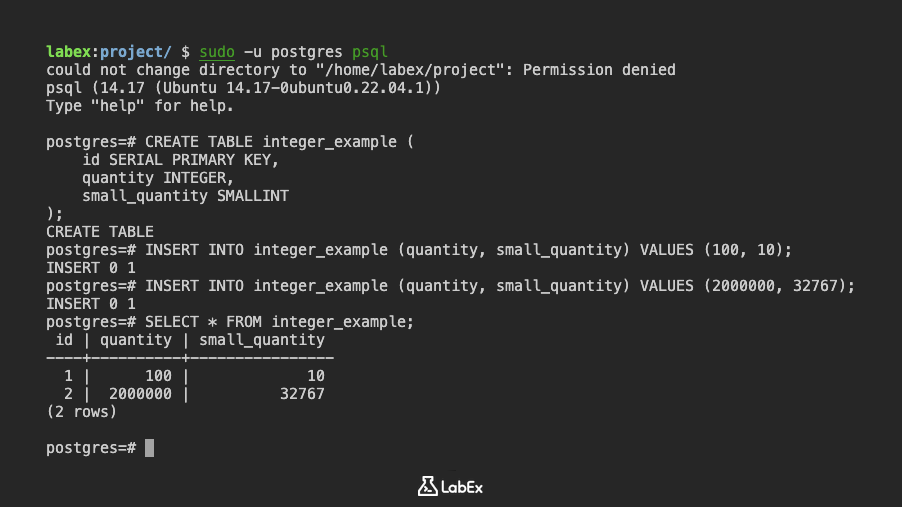
CREATE TABLE integer_example (
id SERIAL PRIMARY KEY,
quantity INTEGER,
small_quantity SMALLINT
);
Aqui, SERIAL é um tipo especial que gera automaticamente uma sequência de inteiros, tornando-o adequado para chaves primárias.
Agora, insira alguns dados:
INSERT INTO integer_example (quantity, small_quantity) VALUES (100, 10);
INSERT INTO integer_example (quantity, small_quantity) VALUES (2000000, 32767);
Você pode visualizar os dados usando:
SELECT * FROM integer_example;
Saída:
id | quantity | small_quantity
----+----------+----------------
1 | 100 | 10
2 | 2000000 | 32767
(2 rows)
2. Tipos de Texto:
O PostgreSQL fornece TEXT, VARCHAR(n) e CHAR(n) para armazenar texto.
TEXT: Armazena strings de comprimento variável de comprimento ilimitado.VARCHAR(n): Armazena strings de comprimento variável com um comprimento máximo den.CHAR(n): Armazena strings de comprimento fixo de comprimenton. Se a string for mais curta, ela é preenchida com espaços.
Vamos criar outra tabela:
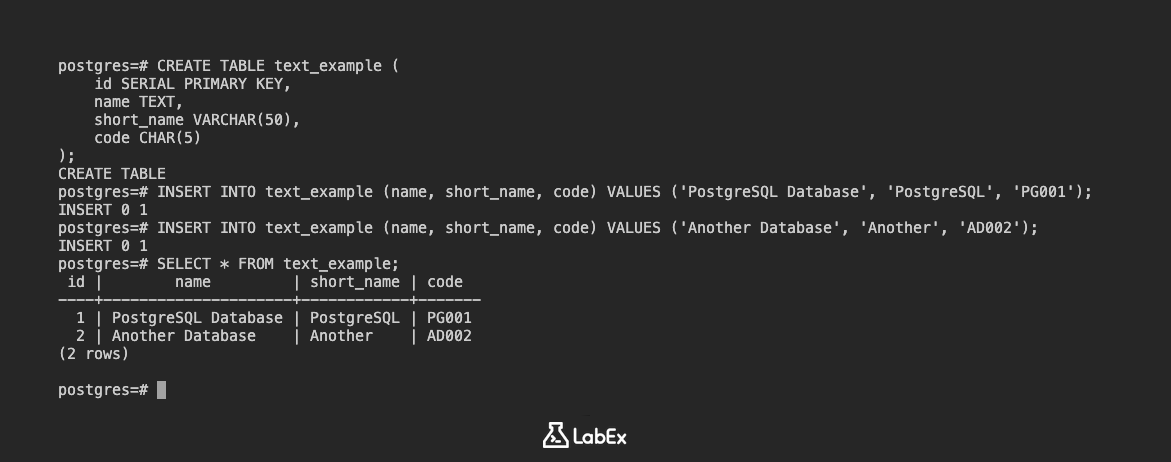
CREATE TABLE text_example (
id SERIAL PRIMARY KEY,
name TEXT,
short_name VARCHAR(50),
code CHAR(5)
);
Insira alguns dados:
INSERT INTO text_example (name, short_name, code) VALUES ('PostgreSQL Database', 'PostgreSQL', 'PG001');
INSERT INTO text_example (name, short_name, code) VALUES ('Another Database', 'Another', 'AD002');
Visualize os dados:
SELECT * FROM text_example;
Saída:
id | name | short_name | code
----+--------------------+------------+-------
1 | PostgreSQL Database | PostgreSQL | PG001
2 | Another Database | Another | AD002
(2 rows)
3. Tipos de Data e Hora:
O PostgreSQL oferece DATE, TIME, TIMESTAMP e TIMESTAMPTZ para lidar com valores de data e hora.
DATE: Armazena apenas a data (ano, mês, dia).TIME: Armazena apenas a hora (hora, minuto, segundo).TIMESTAMP: Armazena data e hora sem informações de fuso horário.TIMESTAMPTZ: Armazena data e hora com informações de fuso horário.
Crie uma tabela:
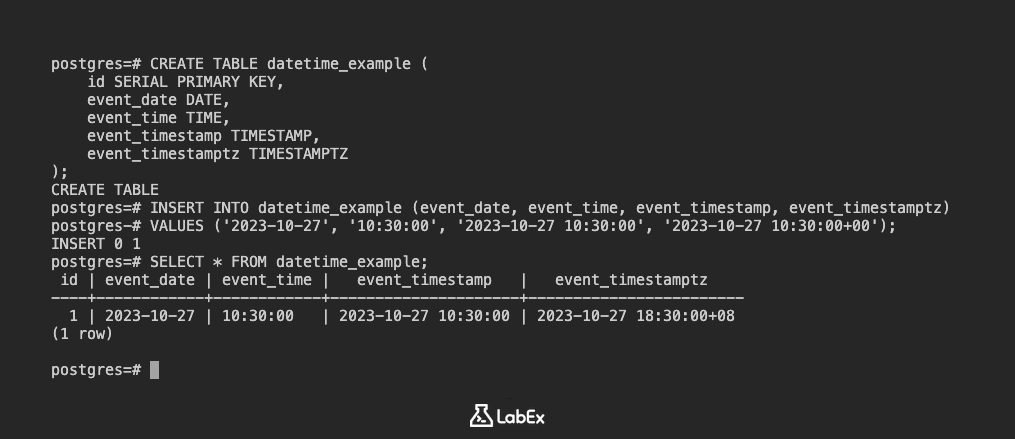
CREATE TABLE datetime_example (
id SERIAL PRIMARY KEY,
event_date DATE,
event_time TIME,
event_timestamp TIMESTAMP,
event_timestamptz TIMESTAMPTZ
);
Insira dados:
INSERT INTO datetime_example (event_date, event_time, event_timestamp, event_timestamptz)
VALUES ('2023-10-27', '10:30:00', '2023-10-27 10:30:00', '2023-10-27 10:30:00+00');
Visualize os dados:
SELECT * FROM datetime_example;
Saída:
id | event_date | event_time | event_timestamp | event_timestamptz
----+------------+------------+---------------------+----------------------------
1 | 2023-10-27 | 10:30:00 | 2023-10-27 10:30:00 | 2023-10-27 10:30:00+00
(1 row)
4. Tipo Booleano:
O tipo BOOLEAN armazena valores verdadeiro/falso.
Crie uma tabela:
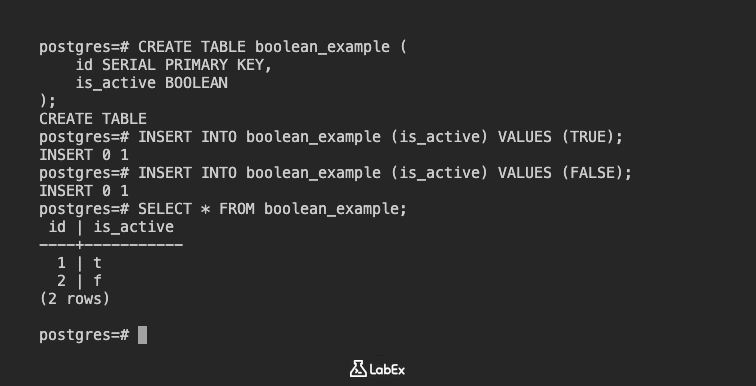
CREATE TABLE boolean_example (
id SERIAL PRIMARY KEY,
is_active BOOLEAN
);
Insira dados:
INSERT INTO boolean_example (is_active) VALUES (TRUE);
INSERT INTO boolean_example (is_active) VALUES (FALSE);
Visualize os dados:
SELECT * FROM boolean_example;
Saída:
id | is_active
----+-----------
1 | t
2 | f
(2 rows)
Finalmente, saia do terminal psql:
\q
Você explorou agora alguns dos tipos de dados fundamentais no PostgreSQL. Esses tipos de dados formam os blocos de construção para criar esquemas de banco de dados robustos e bem definidos.
Criar Tabelas com Chaves Primárias
Nesta etapa, aprenderemos como criar tabelas com chaves primárias no PostgreSQL. Uma chave primária é uma coluna ou um conjunto de colunas que identifica exclusivamente cada linha em uma tabela. Ela impõe a unicidade e serve como um elemento crucial para a integridade dos dados e as relações entre as tabelas.
Primeiro, vamos conectar ao banco de dados PostgreSQL. Abra um terminal e use o comando psql para conectar ao banco de dados postgres como o usuário postgres.
sudo -u postgres psql
Você deve estar agora no terminal interativo do PostgreSQL.
Entendendo as Chaves Primárias
Uma chave primária tem as seguintes características:
- Deve conter valores únicos.
- Não pode conter valores
NULL. - Uma tabela pode ter apenas uma chave primária.
Criando uma Tabela com uma Chave Primária
Existem duas maneiras comuns de definir uma chave primária ao criar uma tabela:
Usando a restrição
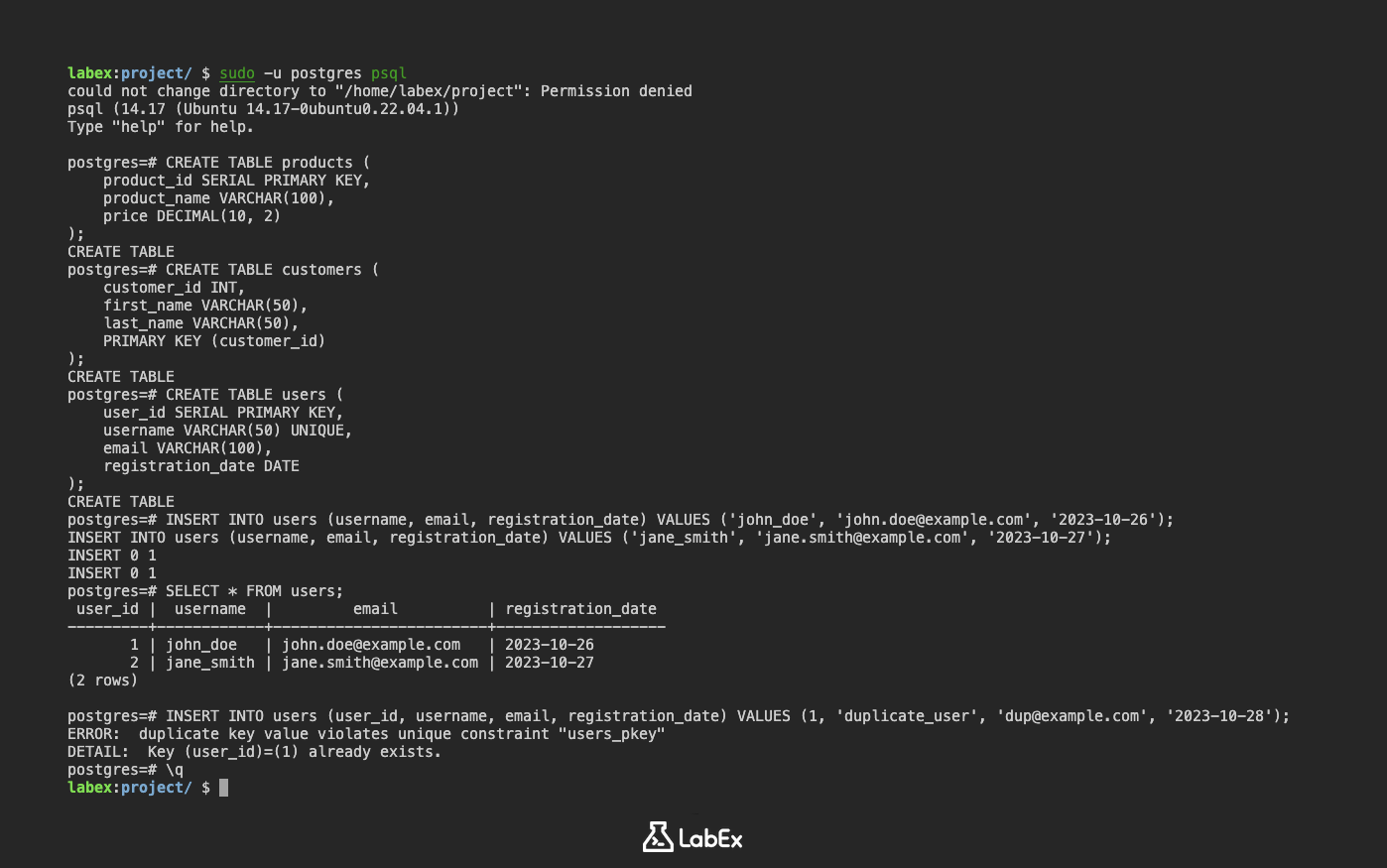
PRIMARY KEYdentro da definição da coluna:CREATE TABLE products ( product_id SERIAL PRIMARY KEY, product_name VARCHAR(100), price DECIMAL(10, 2) );Neste exemplo,
product_idé definido como a chave primária usando a restriçãoPRIMARY KEY. A palavra-chaveSERIALcria automaticamente uma sequência para gerar valores inteiros únicos para oproduct_id.Usando a restrição
PRIMARY KEYseparadamente:CREATE TABLE customers ( customer_id INT, first_name VARCHAR(50), last_name VARCHAR(50), PRIMARY KEY (customer_id) );Aqui, a restrição
PRIMARY KEYé definida separadamente, especificando que a colunacustomer_idé a chave primária.
Exemplo: Criando uma tabela users com uma chave primária
Vamos criar uma tabela users com uma chave primária usando o tipo SERIAL para geração automática de ID:
CREATE TABLE users (
user_id SERIAL PRIMARY KEY,
username VARCHAR(50) UNIQUE,
email VARCHAR(100),
registration_date DATE
);
Nesta tabela:
user_idé a chave primária, gerada automaticamente usandoSERIAL.usernameé um nome de usuário único para cada usuário.emailé o endereço de e-mail do usuário.registration_dateé a data em que o usuário se registrou.
Agora, vamos inserir alguns dados na tabela users:
INSERT INTO users (username, email, registration_date) VALUES ('john_doe', 'john.doe@example.com', '2023-10-26');
INSERT INTO users (username, email, registration_date) VALUES ('jane_smith', 'jane.smith@example.com', '2023-10-27');
Você pode visualizar os dados usando:
SELECT * FROM users;
Saída:
user_id | username | email | registration_date
---------+------------+---------------------+---------------------
1 | john_doe | john.doe@example.com | 2023-10-26
2 | jane_smith | jane.smith@example.com | 2023-10-27
(2 rows)
Tentando inserir uma chave primária duplicada
Se você tentar inserir uma linha com uma chave primária duplicada, o PostgreSQL gerará um erro:
INSERT INTO users (user_id, username, email, registration_date) VALUES (1, 'duplicate_user', 'dup@example.com', '2023-10-28');
Saída:
ERROR: duplicate key value violates unique constraint "users_pkey"
DETAIL: Key (user_id)=(1) already exists.
Isso demonstra a restrição de chave primária em ação, impedindo valores duplicados.
Finalmente, saia do terminal psql:
\q
Você criou com sucesso uma tabela com uma chave primária e observou como ela impõe a unicidade. Este é um conceito fundamental no design de banco de dados.
Adicionar Restrições Básicas (NOT NULL, UNIQUE)
Nesta etapa, aprenderemos como adicionar restrições básicas às tabelas no PostgreSQL. Restrições são regras que impõem a integridade e consistência dos dados. Vamos nos concentrar em duas restrições fundamentais: NOT NULL e UNIQUE.
Primeiro, vamos conectar ao banco de dados PostgreSQL. Abra um terminal e use o comando psql para conectar ao banco de dados postgres como o usuário postgres.
sudo -u postgres psql
Você deve estar agora no terminal interativo do PostgreSQL.
Entendendo as Restrições
As restrições são usadas para limitar o tipo de dados que podem ser inseridos em uma tabela. Isso garante a precisão e a confiabilidade dos dados no banco de dados.
1. Restrição NOT NULL
A restrição NOT NULL garante que uma coluna não pode conter valores NULL. Isso é útil quando uma informação específica é essencial para cada linha na tabela.
2. Restrição UNIQUE
A restrição UNIQUE garante que todos os valores em uma coluna sejam distintos. Isso é útil para colunas que devem ter identificadores ou valores únicos, como nomes de usuário ou endereços de e-mail (além da chave primária).
Adicionando Restrições Durante a Criação da Tabela
Você pode adicionar restrições ao criar uma tabela. Vamos criar uma tabela chamada employees com restrições NOT NULL e UNIQUE:
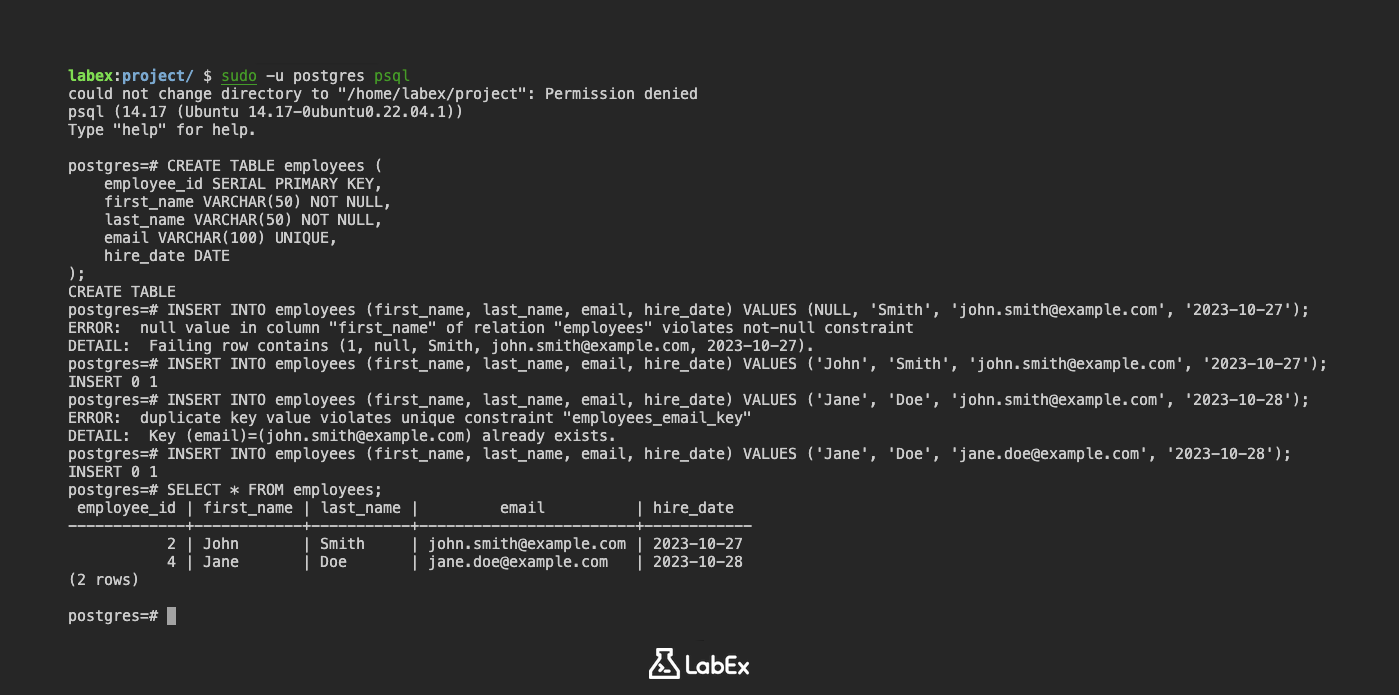
CREATE TABLE employees (
employee_id SERIAL PRIMARY KEY,
first_name VARCHAR(50) NOT NULL,
last_name VARCHAR(50) NOT NULL,
email VARCHAR(100) UNIQUE,
hire_date DATE
);
Nesta tabela:
employee_idé a chave primária.first_nameelast_namesão declarados comoNOT NULL, o que significa que eles devem ter um valor para cada funcionário.emailé declarado comoUNIQUE, garantindo que cada funcionário tenha um endereço de e-mail exclusivo.
Agora, vamos tentar inserir alguns dados que violam essas restrições.
Tentando inserir um valor NULL em uma coluna NOT NULL:
INSERT INTO employees (first_name, last_name, email, hire_date) VALUES (NULL, 'Smith', 'john.smith@example.com', '2023-10-27');
Saída:
ERROR: null value in column "first_name" of relation "employees" violates not-null constraint
DETAIL: Failing row contains (1, null, Smith, john.smith@example.com, 2023-10-27).
Este erro indica que você não pode inserir um valor NULL na coluna first_name por causa da restrição NOT NULL.
Tentando inserir um valor duplicado em uma coluna UNIQUE:
Primeiro, insira uma linha válida:
INSERT INTO employees (first_name, last_name, email, hire_date) VALUES ('John', 'Smith', 'john.smith@example.com', '2023-10-27');
Agora, tente inserir outra linha com o mesmo e-mail:
INSERT INTO employees (first_name, last_name, email, hire_date) VALUES ('Jane', 'Doe', 'john.smith@example.com', '2023-10-28');
Saída:
ERROR: duplicate key value violates unique constraint "employees_email_key"
DETAIL: Key (email)=(john.smith@example.com) already exists.
Este erro indica que você não pode inserir um endereço de e-mail duplicado por causa da restrição UNIQUE.
Inserindo dados válidos:
INSERT INTO employees (first_name, last_name, email, hire_date) VALUES ('Jane', 'Doe', 'jane.doe@example.com', '2023-10-28');
Visualize os dados:
SELECT * FROM employees;
Saída:
employee_id | first_name | last_name | email | hire_date
-------------+------------+-----------+---------------------+------------
1 | John | Smith | john.smith@example.com | 2023-10-27
2 | Jane | Doe | jane.doe@example.com | 2023-10-28
(2 rows)
Finalmente, saia do terminal psql:
\q
Você criou com sucesso uma tabela com restrições NOT NULL e UNIQUE e observou como elas impõem a integridade dos dados.
Inspecionar a Estrutura da Tabela
Nesta etapa, aprenderemos como inspecionar a estrutura das tabelas no PostgreSQL. Compreender a estrutura de uma tabela, incluindo nomes de colunas, tipos de dados, restrições e índices, é essencial para consultar e manipular dados de forma eficaz.
Primeiro, vamos conectar ao banco de dados PostgreSQL. Abra um terminal e use o comando psql para conectar ao banco de dados postgres como o usuário postgres.
sudo -u postgres psql
Você deve estar agora no terminal interativo do PostgreSQL.
O comando \d
A principal ferramenta para inspecionar a estrutura da tabela no psql é o comando \d (describe). Este comando fornece informações detalhadas sobre uma tabela, incluindo:
- Nomes de colunas e tipos de dados
- Restrições (chaves primárias, restrições únicas, restrições not-null)
- Índices
Inspecionando a tabela employees
Vamos inspecionar a estrutura da tabela employees que criamos na etapa anterior:
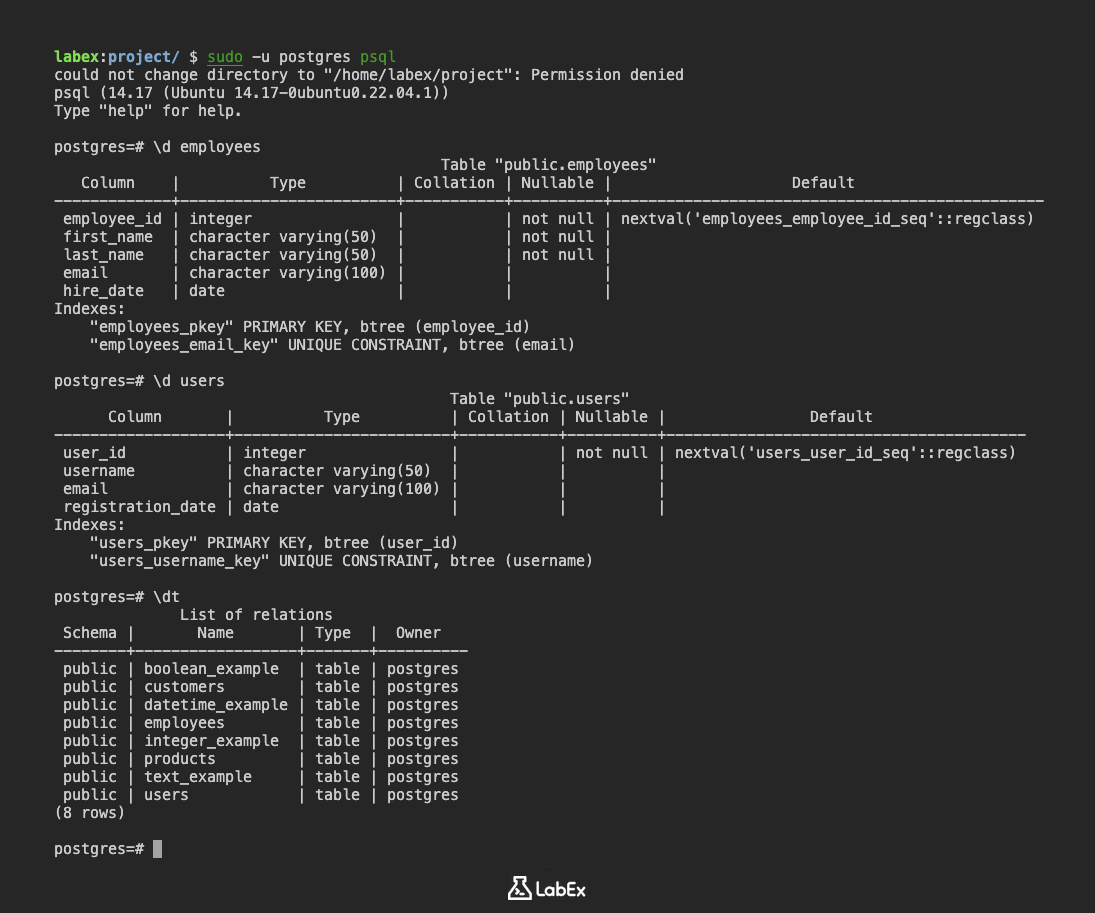
\d employees
Saída:
Table "public.employees"
Column | Type | Collation | Nullable | Default
-------------+------------------------+-----------+----------+------------------------------------------------
employee_id | integer | | not null | nextval('employees_employee_id_seq'::regclass)
first_name | character varying(50) | | not null |
last_name | character varying(50) | | not null |
email | character varying(100) | | |
hire_date | date | | |
Indexes:
"employees_pkey" PRIMARY KEY, btree (employee_id)
"employees_email_key" UNIQUE CONSTRAINT, btree (email)
A saída fornece as seguintes informações:
- Table "public.employees": Indica o nome da tabela e o esquema.
- Column: Lista os nomes das colunas (
employee_id,first_name,last_name,email,hire_date). - Type: Mostra o tipo de dados de cada coluna (
integer,character varying,date). - Nullable: Indica se uma coluna pode conter valores
NULL(not nullou em branco). - Default: Mostra o valor padrão para uma coluna (se houver).
- Indexes: Lista os índices definidos na tabela, incluindo a chave primária (
employees_pkey) e a restrição única na colunaemail(employees_email_key).
Inspecionando outras tabelas
Você pode usar o comando \d para inspecionar qualquer tabela no banco de dados. Por exemplo, para inspecionar a tabela users criada na etapa 2:
\d users
Saída:
Table "public.users"
Column | Type | Collation | Nullable | Default
-------------------+------------------------+-----------+----------+----------------------------------------
user_id | integer | | not null | nextval('users_user_id_seq'::regclass)
username | character varying(50) | | |
email | character varying(100) | | |
registration_date | date | | |
Indexes:
"users_pkey" PRIMARY KEY, btree (user_id)
"users_username_key" UNIQUE CONSTRAINT, btree (username)
Listando todas as tabelas
Para listar todas as tabelas no banco de dados atual, você pode usar o comando \dt:
\dt
Saída (variará dependendo das tabelas que você criou):
List of relations
Schema | Name | Type | Owner
--------+------------------+-------+----------
public | boolean_example | table | postgres
public | customers | table | postgres
public | datetime_example | table | postgres
public | employees | table | postgres
public | integer_example | table | postgres
public | products | table | postgres
public | text_example | table | postgres
public | users | table | postgres
(8 rows)
Finalmente, saia do terminal psql:
\q
Você aprendeu como inspecionar a estrutura das tabelas no PostgreSQL usando os comandos \d e \dt. Esta é uma habilidade fundamental para entender e trabalhar com bancos de dados.
Resumo
Neste laboratório, exploramos os tipos de dados fundamentais do PostgreSQL, com foco em inteiros e texto. Aprendemos sobre INTEGER e SMALLINT para armazenar valores inteiros, compreendendo suas diferentes faixas e casos de uso. Também examinamos TEXT, VARCHAR(n) e CHAR(n) para lidar com dados de texto, observando as distinções entre strings de comprimento variável e comprimento fixo.
Além disso, praticamos a criação de tabelas usando esses tipos de dados, incluindo o uso de SERIAL para gerar automaticamente sequências de chaves primárias. Inserimos dados de exemplo nas tabelas e verificamos os dados usando as instruções SELECT, solidificando nossa compreensão de como esses tipos de dados se comportam em um contexto prático de banco de dados.

