
Introdução
Nas versões Hadoop 2.0 e posteriores, foi introduzido o novo padrão de gerenciamento de recursos do YARN, que facilita o cluster em termos de utilização, gerenciamento unificado de recursos e compartilhamento de dados. Com base na construção do cluster Hadoop pseudo-distribuído, esta seção permitirá que você aprenda a arquitetura, o princípio de funcionamento, a configuração e as técnicas de desenvolvimento e monitoramento do framework YARN.
Este laboratório requer uma certa base em programação Java.
Por favor, insira todo o código de exemplo no documento por conta própria; não apenas copie e cole o máximo possível. Desta forma, você poderá se familiarizar mais com o código. Se tiver problemas, revise cuidadosamente a documentação ou pode ir ao fórum para obter ajuda e comunicação.
Arquitetura e Componentes do YARN
O YARN, introduzido no Hadoop 0.23 como parte do MapReduce 2.0 (MRv2), revolucionou o gerenciamento de recursos e o agendamento de tarefas em clusters Hadoop:
- Decomposição do JobTracker:
MRv2decompõe as funções doJobTrackerem daemons separados -ResourceManagerpara gerenciamento de recursos eApplicationMasterpara agendamento e monitoramento de tarefas. - ResourceManager Global: Cada aplicação possui um
ApplicationMastercorrespondente, que pode ser uma tarefa MapReduce ou um DAG que descreve a tarefa. - Framework de Cálculo de Dados: O
ResourceManager,SlaveeNodeManagerformam um framework onde o ResourceManager governa todos os recursos da aplicação. - Componentes do ResourceManager: O
Scheduleraloca recursos com base em restrições como capacidade e filas, enquanto oApplicationsManagerlida com as submissões de tarefas e a execução do ApplicationMaster. - Alocação de Recursos: Os requisitos de recursos são definidos usando contêineres de recursos com elementos como memória, CPU, disco e rede.
- Função do NodeManager: O NodeManager monitora o uso de recursos do contêiner e relata ao ResourceManager e ao Scheduler.
- Tarefas do ApplicationMaster: O ApplicationMaster negocia contêineres de recursos com o Scheduler, acompanha o status e monitora o progresso.
A figura a seguir ilustra a relação:

O YARN garante a compatibilidade da API com versões anteriores, permitindo uma transição perfeita para a execução de tarefas MapReduce. Compreender a arquitetura e os componentes do YARN é essencial para o gerenciamento eficiente de recursos e o agendamento de tarefas em clusters Hadoop.
Iniciando o Daemon Hadoop
Antes de aprender os parâmetros de configuração relevantes e as técnicas de desenvolvimento de aplicações YARN, precisamos iniciar o daemon Hadoop para que ele possa ser usado a qualquer momento.
Primeiro, clique duas vezes para abrir o terminal Xfce na área de trabalho e digite o seguinte comando para mudar para o usuário hadoop:
su - hadoop
Dica: A senha é 'hadoop' para o usuário 'hadoop'.
Após a conclusão da mudança, você pode iniciar os daemons relacionados ao Hadoop, incluindo os frameworks HDFS e YARN.
Por favor, insira os seguintes comandos no terminal para iniciar os daemons:
/home/hadoop/hadoop/sbin/start-dfs.sh
/home/hadoop/hadoop/sbin/start-yarn.sh
Após a conclusão da inicialização, você pode optar por usar o comando jps para verificar se os daemons associados estão em execução.
hadoop:~$ jps
3378 NodeManager
3028 SecondaryNameNode
3717 Jps
2791 DataNode
2648 NameNode
3240 ResourceManager
Preparando o Arquivo de Configuração
Nesta seção, aprenderemos sobre o yarn-site.xml, que é um dos principais arquivos de configuração do Hadoop, para ver quais configurações podem ser feitas para o cluster YARN neste arquivo.
Para evitar o uso indevido de alterações no arquivo de configuração, é melhor copiar o arquivo de configuração do Hadoop para outro diretório e, em seguida, abri-lo.
Para fazer isso, insira o seguinte comando no terminal para criar um novo diretório para o arquivo de configuração:
mkdir /home/hadoop/hadoop_conf
Em seguida, copie o arquivo de configuração principal yarn-site.xml do YARN do diretório de instalação para o diretório recém-criado.
Insira o seguinte comando no terminal para realizar a operação:
cp /home/hadoop/hadoop/etc/hadoop/yarn-site.xml /home/hadoop/hadoop_conf/yarn-site.xml
Em seguida, use o editor vim para abrir o arquivo e visualizar seu conteúdo:
vim /home/hadoop/hadoop_conf/yarn-site.xml
Como o Arquivo de Configuração Funciona
Sabemos que existem dois papéis importantes no framework YARN: ResourceManager e NodeManager. Portanto, cada item de configuração no arquivo é uma configuração dos dois componentes acima.
Existem muitos itens de configuração que podem ser definidos neste arquivo, mas, por padrão, este arquivo não contém nenhum item de configuração personalizado. Por exemplo, o arquivo que abrimos agora tem apenas o atributo aux-services que foi especificado quando o cluster Hadoop pseudo-distribuído foi configurado anteriormente, conforme mostrado na figura a seguir:
hadoop:~$ cat /home/hadoop/hadoop/etc/hadoop/mapred-site.xml
...
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
Este item de configuração é usado para definir os serviços dependentes que precisam ser executados no NodeManager. O valor de configuração que especificamos é mapreduce_shuffle, indicando que o valor padrão do programa MapReduce precisa ser executado no YARN.
Os itens de configuração que não estão escritos nele não estão funcionando? Não exatamente. Quando os parâmetros de configuração não são explicitamente especificados no arquivo, o framework YARN do Hadoop lerá os valores padrão armazenados em arquivos internos. Todos os itens de configuração explicitamente especificados no arquivo yarn-site.xml substituirão os valores padrão, o que é uma maneira eficaz para o sistema Hadoop se adaptar a diferentes cenários de uso.
Itens de Configuração do ResourceManager
Compreender e configurar corretamente as configurações do ResourceManager no arquivo yarn-site.xml é essencial para o gerenciamento eficiente de recursos e a execução de tarefas em um cluster Hadoop. Aqui está um resumo dos principais itens de configuração relacionados ao ResourceManager:
yarn.resourcemanager.address: Expõe o endereço aos clientes para enviar aplicações e encerrar aplicações. A porta padrão é 8032.yarn.resourcemanager.scheduler.address: Expõe o endereço ao ApplicationMaster para solicitar e liberar recursos. A porta padrão é 8030.yarn.resourcemanager.resource-tracker.address: Expõe o endereço ao NodeManager para enviar heartbeats e buscar tarefas. A porta padrão é 8031.yarn.resourcemanager.admin.address: Expõe o endereço aos administradores para comandos de gerenciamento. A porta padrão é 8033.yarn.resourcemanager.webapp.address: Endereço da WebUI para visualizar informações do cluster. A porta padrão é 8088.yarn.resourcemanager.scheduler.class: Especifica o nome da classe principal do scheduler (por exemplo, FIFO, CapacityScheduler, FairScheduler).- Configuração de Threads:
yarn.resourcemanager.resource-tracker.client.thread-countyarn.resourcemanager.scheduler.client.thread-count
- Alocação de Recursos:
yarn.scheduler.minimum-allocation-mbyarn.scheduler.maximum-allocation-mbyarn.scheduler.minimum-allocation-vcoresyarn.scheduler.maximum-allocation-vcores
- Gerenciamento do NodeManager:
yarn.resourcemanager.nodes.exclude-pathyarn.resourcemanager.nodes.include-path
- Configuração de Heartbeat:
yarn.resourcemanager.nodemanagers.heartbeat-interval-ms
A configuração desses parâmetros permite o ajuste fino do comportamento do ResourceManager, alocação de recursos, tratamento de threads, gerenciamento do NodeManager e intervalos de heartbeat em um cluster Hadoop. Compreender esses itens de configuração ajuda a prevenir problemas e garante a operação suave do cluster.
Itens de Configuração do NodeManager
Configurar as configurações do NodeManager no arquivo yarn-site.xml é crucial para gerenciar recursos e tarefas de forma eficiente dentro de um cluster Hadoop. Aqui está um resumo dos principais itens de configuração relacionados ao NodeManager:
yarn.nodemanager.resource.memory-mb: Especifica a memória física total disponível para o NodeManager. Este valor permanece constante durante o tempo de execução do YARN.yarn.nodemanager.vmem-pmem-ratio: Define a proporção de memória virtual para alocação de memória física. A proporção padrão é2.1.yarn.nodemanager.resource.cpu-vcores: Define o número total de CPUs virtuais disponíveis para o NodeManager. O valor padrão é8.yarn.nodemanager.local-dirs: Caminho para armazenar resultados intermediários no NodeManager, permitindo a configuração de vários diretórios.yarn.nodemanager.log-dirs: Caminho para o diretório de logs do NodeManager, suportando a configuração de vários diretórios.yarn.nodemanager.log.retain-seconds: Tempo máximo de retenção para os logs do NodeManager, o padrão é 10800 segundos (3 horas).
A configuração desses parâmetros permite o ajuste fino da alocação de recursos, gerenciamento de memória, caminhos de diretórios e configurações de retenção de logs para desempenho ideal e utilização de recursos pelo NodeManager em um cluster Hadoop. Compreender esses itens de configuração ajuda a garantir a operação suave e a execução eficiente de tarefas dentro do cluster.
Consulta de Itens de Configuração e Referências Padrão
Para explorar todos os itens de configuração disponíveis no YARN e outros componentes comuns do Hadoop, você pode consultar os arquivos de configuração padrão fornecidos pelo Apache Hadoop. Aqui estão os links para acessar as configurações padrão:
Itens de Configuração do YARN:
Arquivos de Configuração Comuns:
- core-default.xml (core-site.xml)
- hdfs-default.xml (hdfs-site.xml)
- mapred-default.xml (mapred-site.xml)
Explorar essas configurações padrão fornece descrições detalhadas de cada item de configuração e seus propósitos, ajudando você a entender o papel de cada parâmetro no projeto da arquitetura Hadoop.
Após revisar as configurações, você pode fechar o editor vim para concluir sua exploração das configurações do Hadoop.
Criando Diretórios e Arquivos do Projeto
Vamos aprender o processo de desenvolvimento da aplicação YARN imitando uma aplicação de instância YARN oficial.
Primeiro, crie um diretório de projeto. Insira o seguinte comando no terminal para realizar a criação do diretório:
mkdir /home/hadoop/yarn_app
Em seguida, crie dois arquivos de código-fonte no projeto separadamente.
O primeiro é Client.java. Use o comando touch no terminal para criar o arquivo:
touch /home/hadoop/yarn_app/Client.java
Em seguida, crie o arquivo ApplicationMaster.java:
touch /home/hadoop/yarn_app/ApplicationMaster.java
hadoop:~$ tree /home/hadoop/yarn_app/
/home/hadoop/yarn_app/
├── ApplicationMaster.java
└── Client.java
0 directories, 2 files
Escrevendo o Código do Cliente
Ao escrever o código para o Cliente, você poderá entender as APIs e seus papéis necessários para desenvolver o Cliente sob o framework YARN.
O conteúdo do código é um pouco longo. Uma maneira mais eficiente do que lê-lo linha por linha é inseri-lo linha por linha no arquivo de código-fonte que você acabou de criar.
Primeiro, abra o arquivo Client.java recém-criado com o editor vim (ou outro editor de texto):
vim /home/hadoop/yarn_app/Client.java
Em seguida, adicione o corpo principal do programa para indicar o nome da classe e o nome do pacote para a classe:
package com.labex.yarn.app;
public class Client {
public static void main(String[] args){
//TODO: Edite o código aqui.
}
}
O código a seguir está na forma de segmentação. Ao escrever, escreva o código a seguir na classe Client (ou seja, o bloco de código onde o comentário //TODO: Edite seu código aqui está localizado).
A primeira etapa que o cliente precisa fazer é criar e inicializar o objeto YarnClient e, em seguida, iniciá-lo:
YarnClient yarnClient = YarnClient.createYarnClient();
yarnClient.init(conf);
yarnClient.start();
Depois de criar o Client, precisamos criar um objeto da aplicação YARN e seu ID da aplicação:
YarnClientApplication app = yarnClient.createApplication();
GetNewApplicationResponse appResponse = app.getNewApplicationResponse();
O objeto appResponse contém informações sobre o cluster, como as capacidades mínimas e máximas de recursos do cluster. As informações são necessárias para garantir que possamos definir corretamente os parâmetros quando o ApplicationMaster iniciar o contêiner relevante.
Uma das principais tarefas no Client é definir o ApplicationSubmissionContext. Ele define todas as informações que o RM precisa para iniciar o AM.
Em geral, o Client precisa definir o seguinte no contexto:
- Informações da aplicação: Inclui o ID e o nome do aplicativo.
- Informações da fila e prioridade: Inclui filas e prioridades atribuídas para envios de aplicações.
- Usuários: Quem é o usuário, quem enviou o aplicativo.
- ContainerLaunchContext: Define as informações do contêiner no qual iniciar e executar o AM. Todas as informações necessárias para executar a aplicação são definidas no
ContainerLaunchContext, incluindo recursos locais (arquivos binários, arquivos jar etc.), variáveis de ambiente (CLASSPATHetc.), comandos a serem executados e Token seguro (RECT):
// Define a aplicação para enviar o contexto
ApplicationSubmissionContext appContext = app.getApplicationSubmissionContext();
ApplicationId appId = appContext.getApplicationId();
appContext.setKeepContainersAcrossApplicationAttempts(keepContainers);
appContext.setApplicationName(appName);
// O código a seguir é usado para definir os recursos locais do ApplicationMaster
/ / Recursos locais precisam ser arquivos locais ou pacotes compactados etc.
// Neste cenário, o pacote jar está na forma de um arquivo como um dos recursos locais do AM.
Map<String, LocalResource> localResources = new HashMap<String, LocalResource>();
LOG.info("Copiar o jar do AppMaster do sistema de arquivos local e adicionar ao ambiente local.");
// Copie o pacote jar do ApplicationMaster para o sistema de arquivos
FileSystem fs = FileSystem.get(conf);
// Crie um recurso local que aponte para o caminho do pacote jar
addToLocalResources(fs, appMasterJar, appMasterJarPath, appId.toString(), localResources, null);
// Defina os parâmetros de logs, você pode ignorá-lo
if (!log4jPropFile.isEmpty()) {
addToLocalResources(fs, log4jPropFile, log4jPath, appId.toString(), localResources, null);
}
// O script shell estará disponível no contêiner que o executará eventualmente
// Então, primeiro copie-o para o sistema de arquivos para que o framework YARN possa encontrá-lo
// Você não precisa defini-lo para o recurso local do AM aqui porque este último não precisa dele
String hdfsShellScriptLocation = "";
long hdfsShellScriptLen = 0;
long hdfsShellScriptTimestamp = 0;
if (!shellScriptPath.isEmpty()) {
Path shellSrc = new Path(shellScriptPath);
String shellPathSuffix = appName + "/" + appId.toString() + "/" + SCRIPT_PATH;
Path shellDst = new Path(fs.getHomeDirectory(), shellPathSuffix);
fs.copyFromLocalFile(false, true, shellSrc, shellDst);
hdfsShellScriptLocation = shellDst.toUri().toString();
FileStatus shellFileStatus = fs.getFileStatus(shellDst);
hdfsShellScriptLen = shellFileStatus.getLen();
hdfsShellScriptTimestamp = shellFileStatus.getModificationTime();
}
if (!shellCommand.isEmpty()) {
addToLocalResources(fs, null, shellCommandPath, appId.toString(),
localResources, shellCommand);
}
if (shellArgs.length > 0) {
addToLocalResources(fs, null, shellArgsPath, appId.toString(),
localResources, StringUtils.join(shellArgs, " "));
}
// Defina os parâmetros de ambiente que o AM requer
LOG.info("Definir o ambiente para o master da aplicação");
Map<String, String> env = new HashMap<String, String>();
// Adicione o caminho para o script shell à variável de ambiente
// AM criará o recurso local correto para o contêiner final de acordo
// e o contêiner acima executará o script shell na inicialização
env.put(DSConstants.DISTRIBUTEDSHELLSCRIPTLOCATION, hdfsShellScriptLocation);
env.put(DSConstants.DISTRIBUTEDSHELLSCRIPTTIMESTAMP, Long.toString(hdfsShellScriptTimestamp));
env.put(DSConstants.DISTRIBUTEDSHELLSCRIPTLEN, Long.toString(hdfsShellScriptLen));
// Adicione o caminho para AppMaster.jar ao classpath
// Observe que não há necessidade de fornecer um classpath relacionado ao Hadoop aqui, pois temos uma anotação no arquivo de configuração externo.
// O código a seguir adiciona todas as configurações de caminho relacionadas ao classpath necessárias pelo AM ao diretório atual
StringBuilder classPathEnv = new StringBuilder(Environment.CLASSPATH.$$())
.append(ApplicationConstants.CLASS_PATH_SEPARATOR).append("./*");
for (String c : conf.getStrings(
YarnConfiguration.YARN_APPLICATION_CLASSPATH,
YarnConfiguration.DEFAULT_YARN_CROSS_PLATFORM_APPLICATION_CLASSPATH)) {
classPathEnv.append(ApplicationConstants.CLASS_PATH_SEPARATOR);
classPathEnv.append(c.trim());
}
classPathEnv.append(ApplicationConstants.CLASS_PATH_SEPARATOR).append(
"./log4j.properties");
// Defina o comando para executar o AM
Vector<CharSequence> vargs = new Vector<CharSequence>(30);
// Defina o comando executável para Java
LOG.info("Configurando o comando do master do aplicativo");
vargs.add(Environment.JAVA_HOME.$$() + "/bin/java");
// Defina os números de memória atribuídos pelos parâmetros Xmx sob JVM
vargs.add("-Xmx" + amMemory + "m");
// Defina os nomes das classes
vargs.add(appMasterMainClass);
// Defina o parâmetro do ApplicationMaster
vargs.add("--container_memory " + String.valueOf(containerMemory));
vargs.add("--container_vcores " + String.valueOf(containerVirtualCores));
vargs.add("--num_containers " + String.valueOf(numContainers));
vargs.add("--priority " + String.valueOf(shellCmdPriority));
for (Map.Entry<String, String> entry : shellEnv.entrySet()) {
vargs.add("--shell_env " + entry.getKey() + "=" + entry.getValue());
}
if (debugFlag) {
vargs.add("--debug");
}
vargs.add("1>" + ApplicationConstants.LOG_DIR_EXPANSION_VAR + "/AppMaster.stdout");
vargs.add("2>" + ApplicationConstants.LOG_DIR_EXPANSION_VAR + "/AppMaster.stderr");
// Gere o parâmetro final e configure
StringBuilder command = new StringBuilder();
for (CharSequence str : vargs) {
command.append(str).append(" ");
}
LOG.info("Concluído a configuração do comando do master do aplicativo " + command.toString());
List<String> commands = new ArrayList<String>();
commands.add(command.toString());
// Defina o contêiner para o AM iniciar o contexto
ContainerLaunchContext amContainer = ContainerLaunchContext.newInstance(
localResources, env, commands, null, null, null);
// O requisito de definir tipos de recursos, incluindo memória e núcleos de CPU virtuais.
Resource capability = Resource.newInstance(amMemory, amVCores);
appContext.setResource(capability);
// Se necessário, os dados do serviço YARN são passados para as aplicações em formato binário. Mas não é necessário neste exemplo.
// amContainer.setServiceData(serviceData);
// Defina o Token
if (UserGroupInformation.isSecurityEnabled()) {
Credentials credentials = new Credentials();
String tokenRenewer = conf.get(YarnConfiguration.RM_PRINCIPAL);
if (tokenRenewer == null || tokenRenewer.length() == 0) {
throw new IOException(
"Não é possível obter o principal Kerberos Master para o RM usar como renovador");
}
// Obtenha o token do sistema de arquivos padrão
final Token<?> tokens[] =
fs.addDelegationTokens(tokenRenewer, credentials);
if (tokens != null) {
for (Token<?> token : tokens) {
LOG.info("Obteve dt para " + fs.getUri() + "; " + token);
}
}
DataOutputBuffer dob = new DataOutputBuffer();
credentials.writeTokenStorageToStream(dob);
ByteBuffer fsTokens = ByteBuffer.wrap(dob.getData(), 0, dob.getLength());
amContainer.setTokens(fsTokens);
}
appContext.setAMContainerSpec(amContainer);
Depois que o processo de configuração estiver concluído, o cliente pode enviar aplicações com a prioridade e a fila especificadas:
/ / Defina a prioridade do AM
Priority pri = Priority.newInstance(amPriority);
appContext.setPriority(pri);
// Defina a fila para onde a aplicação envia para o RM
appContext.setQueue(amQueue);
// Envie o aplicativo para o AM
yarnClient.submitApplication(appContext);
Neste ponto, o RM aceitará a aplicação e configurará e iniciará o AM no contêiner atribuído em segundo plano.
Os clientes podem rastrear o progresso das tarefas reais de várias maneiras.
(1) Uma delas é que você pode se comunicar com o RM por meio do método getApplicationReport() do objeto YarnClient e solicitar um relatório da aplicação:
// Use o ID do aplicativo para obter seu relatório
ApplicationReport report = yarnClient.getApplicationReport(appId);
Os relatórios recebidos do RM incluem o seguinte:
- Informações gerais: Inclui o número (posição) da aplicação, a fila para enviar a aplicação, o usuário que enviou a aplicação e a hora de início da aplicação.
- Detalhes do ApplicationMaster: O host que está executando o AM, a porta RPC que está ouvindo as solicitações dos Clientes e os Tokens que o Cliente e o AM precisam para se comunicar.
- Informações de rastreamento da aplicação: Se a aplicação suportar alguma forma de rastreamento de progresso, ela pode definir a URL rastreada por meio do método
getTrackingUrl()relatado pela aplicação e o cliente pode monitorar o progresso por este método. - Status da aplicação: Você pode ver o status da aplicação do
ResourceManageremgetYarnApplicationState. SeYarnApplicationStateestiver definido comocomplete, o Cliente deve referenciargetFinalApplicationStatuspara verificar se a tarefa da aplicação foi realmente executada com sucesso. Em caso de falha, mais informações sobre a falha podem ser encontradas comgetDiagnostics.
(2) Se o ApplicationMaster o suportar, o Cliente pode consultar diretamente o progresso do próprio AM usando as informações hostname:rpcport obtidas do relatório da aplicação.
Em alguns casos, se a aplicação estiver em execução por muito tempo, o Cliente pode desejar encerrar a aplicação. YarnClient suporta a chamada killApplication. Ele permite que o Cliente envie um sinal de encerramento para o AM por meio do ResourceManager. Se assim projetado, o gerenciador de aplicações também pode encerrar a chamada por meio de seu suporte de camada RPC, do qual o cliente pode se beneficiar.
O código específico é o seguinte, mas o código é apenas para referência e não precisa ser escrito em Client.java:
yarnClient.killApplication(appId);
Depois de editar o conteúdo acima, salve o conteúdo e saia do editor vim.
Escrevendo o Código do ApplicationMaster
Da mesma forma, use o editor vim para abrir o arquivo ApplicationMaster.java para escrever o código:
vim /home/hadoop/yarn_app/ApplicationMaster.java
package com.labex.yarn.app;
public class ApplicationMaster {
public static void main(String[] args){
//TODO:Edite o código aqui.
}
}
A explicação do código ainda está na forma de um segmento. Todo o código mencionado abaixo deve ser escrito na classe ApplicationMaster (ou seja, o bloco de código onde o comentário //TODO:Edite o código aqui. está localizado).
AM é o proprietário real do job, que é iniciado pelo RM e fornece todas as informações e recursos necessários por meio do Cliente para supervisionar e concluir a tarefa.
Como o AM é iniciado em um único contêiner, é provável que o contêiner compartilhe o mesmo host físico com outros contêineres. Dadas as características de multi-tenancy da plataforma de computação em nuvem e outros problemas, é possível não conseguir saber as portas pré-configuradas para ouvir no início.
Portanto, quando o AM inicia, ele pode receber vários parâmetros por meio do ambiente. Esses parâmetros incluem o ContainerId do contêiner AM, o tempo de envio da aplicação e detalhes sobre o host do NodeManager que está executando o AM.
Todas as interações com o RM exigem que uma aplicação seja agendada. Se este processo falhar, cada aplicação pode tentar novamente. Você pode obter o ApplicationAttemptId do ID do contêiner do AM. Existem APIs relacionadas que podem converter valores obtidos do ambiente em objetos.
Escreva o seguinte código:
Map<String, String> envs = System.getenv();
String containerIdString = envs.get(ApplicationConstants.AM_CONTAINER_ID_ENV);
If (containerIdString == null) {
// O ID do contêiner deve ser definido na variável de ambiente do framework
Throw new IllegalArgumentException(
"ID do contêiner não definido no ambiente");
}
ContainerId containerId = ConverterUtils.toContainerId(containerIdString);
ApplicationAttemptId appAttemptID = containerId.getApplicationAttemptId();
Depois que o AM for totalmente inicializado, podemos iniciar dois clientes: um cliente para o ResourceManager e outro para o NodeManager. Usamos um manipulador de eventos personalizado para configurá-lo, e os detalhes são discutidos posteriormente:
AMRMClientAsync.CallbackHandler allocListener = new RMCallbackHandler();
amRMClient = AMRMClientAsync.createAMRMClientAsync(1000, allocListener);
amRMClient.init(conf);
amRMClient.start();
containerListener = createNMCallbackHandler();
nmClientAsync = new NMClientAsyncImpl(containerListener);
nmClientAsync.init(conf);
nmClientAsync.start();
O AM deve enviar heartbeats para o RM periodicamente para que este último saiba que o AM ainda está em execução. O intervalo de expiração no RM é definido por YarnConfiguration e seu valor padrão é definido pelo item de configuração YarnConfiguration.RM_AM_EXPIRY_INTERVAL_MS no arquivo de configuração. O AM precisa se registrar no ResourceManager para começar a enviar heartbeats:
// Registre-se no RM e comece a enviar heartbeats para o RM
appMasterHostname = NetUtils.getHostname();
RegisterApplicationMasterResponse response = amRMClient.registerApplicationMaster(appMasterHostname, appMasterRpcPort, appMasterTrackingUrl);
As informações de resposta do processo de registro podem incluir a capacidade máxima de recursos do cluster. Podemos usar essas informações para verificar a solicitação da aplicação:
// Salve temporariamente informações sobre as capacidades de recursos do cluster no RM
int maxMem = response.getMaximumResourceCapability().getMemory();
LOG.info("Capacidade máxima de memória de recursos neste cluster " + maxMem);
int maxVCores = response.getMaximumResourceCapability().getVirtualCores();
LOG.info("Capacidade máxima de vcores de recursos neste cluster " + maxVCores);
// Use o limite máximo de memória para restringir o valor da solicitação de capacidade de memória do contêiner
if (containerMemory > maxMem) {
LOG.info("Memória do contêiner especificada acima do limite máximo do cluster."
+ " Usando o valor máximo." + ", especificado=" + containerMemory + ", max="
+ maxMem);
containerMemory = maxMem;
}
if (containerVirtualCores > maxVCores) {
LOG.info("Núcleos virtuais do contêiner especificados acima do limite máximo do cluster."
+ " Usando o valor máximo." + ", especificado=" + containerVirtualCores + ", max="
+ maxVCores);
containerVirtualCores = maxVCores;
}
List<Container> previousAMRunningContainers =
response.getContainersFromPreviousAttempts();
LOG.info("Recebido " + previousAMRunningContainers.size()
+ " contêineres em execução do AM anterior no registro do AM.");
Dependendo dos requisitos da tarefa, o AM pode agendar um conjunto de contêineres para executar tarefas. Usamos esses requisitos para calcular quantos contêineres precisamos e solicitar um número correspondente de contêineres:
int numTotalContainersToRequest = numTotalContainers - previousAMRunningContainers.size();
for (int i = 0; i < numTotalContainersToRequest; ++i) {
//Defina o objeto de solicitação para o contêiner de solicitação RM
ContainerRequest containerAsk = setupContainerAskForRM();
//Envie a solicitação do contêiner para o RM
amRMClient.addContainerRequest(containerAsk);
// Este loop significa sondar o RM em busca de contêineres após obter cotas totalmente alocadas
}
O loop acima continuará em execução até que todos os contêineres tenham sido iniciados e o script shell tenha sido executado (independentemente de ter sucesso ou falhar).
Em setupContainerAskForRM(), você precisa definir o seguinte:
- Capacidades de recursos: Atualmente, o YARN suporta requisitos de recursos baseados em memória, portanto, a solicitação deve definir quanta memória é necessária. Este valor é definido em megabytes e deve ser menor que o múltiplo exato das capacidades máximas e mínimas do cluster. Este recurso de memória corresponde ao limite de memória física imposto ao contêiner de tarefas. As capacidades de recursos também incluem recursos baseados em computação (vCore).
- Prioridade: Ao solicitar um conjunto de contêineres, o AM pode definir diferentes prioridades para as coleções. Por exemplo, o MapReduce AM pode atribuir uma prioridade mais alta aos contêineres exigidos pela tarefa Map, enquanto o contêiner da tarefa Reduce tem uma prioridade mais baixa:
Private ContainerRequest setupContainerAskForRM() {
/ / Defina a prioridade da solicitação
Priority pri = Priority.newInstance(requestPriority);
/ / Defina a solicitação para o tipo de recurso, incluindo memória e CPU
Resource capability = Resource.newInstance(containerMemory,
containerVirtualCores);
ContainerRequest request = new ContainerRequest(capability, null, null, pri);
LOG.info("Alocação de contêiner solicitada: " + request.toString());
Return request;
}
Depois que o AM enviou uma solicitação de alocação de contêiner, o contêiner é iniciado de forma assíncrona pelo manipulador de eventos do cliente AMRMClientAsync. Os programas que lidam com essa lógica devem implementar a interface AMRMClientAsync.CallbackHandler.
(1) Quando despachado para um contêiner, o manipulador precisa iniciar uma thread. A thread executa o código relevante para iniciar o contêiner. Aqui, usamos LaunchContainerRunnable para demonstração. Discutiremos esta classe mais tarde:
@Override
public void onContainersAllocated(List<Container> allocatedContainers) {
LOG.info("Recebeu resposta do RM para alocação de contêiner, allocatedCnt=" + allocatedContainers.size());
numAllocatedContainers.addAndGet(allocatedContainers.size());
for (Container allocatedContainer : allocatedContainers) {
LaunchContainerRunnable runnableLaunchContainer =
new LaunchContainerRunnable(allocatedContainer, containerListener);
Thread launchThread = new Thread(runnableLaunchContainer);
// Inicie e execute o contêiner com threads diferentes, o que impede que a thread principal bloqueie quando todos os contêineres não podem ter recursos alocados
launchThreads.add(launchThread);
launchThread.start();
}
}
(2) Ao enviar um heartbeat, o manipulador de eventos deve relatar o progresso da aplicação:
@Override
public float getProgress() {
// Defina as informações de progresso e relate-as ao RM na próxima vez que você enviar um heartbeat
float progress = (float) numCompletedContainers.get() / numTotalContainers;
Return progress;
}
A thread de inicialização do contêiner realmente inicia o contêiner no NM. Depois de atribuir um contêiner ao AM, ele precisa seguir um processo semelhante ao que o Cliente segue ao configurar o ContainerLaunchContext para a tarefa final a ser executada no contêiner alocado. Depois de definir o ContainerLaunchContext, o AM pode iniciá-lo via NMClientAsync:
// Defina os comandos necessários para executar no contêiner alocado
Vector<CharSequence> vargs = new Vector<CharSequence>(5);
// Defina o comando executável
vargs.add(shellCommand);
// Defina o caminho do script shell
if (!scriptPath.isEmpty()) {
vargs.add(Shell.WINDOWS ? ExecBatScripStringtPath
: ExecShellStringPath);
}
// Defina os parâmetros para os comandos shell
vargs.add(shellArgs);
// Adicione parâmetros de redirecionamento de log
vargs.add("1>" + ApplicationConstants.LOG_DIR_EXPANSION_VAR + "/stdout");
vargs.add("2>" + ApplicationConstants.LOG_DIR_EXPANSION_VAR + "/stderr");
// Obtenha o comando final
StringBuilder command = new StringBuilder();
for (CharSequence str : vargs) {
command.append(str).append(" ");
}
List<String> commands = new ArrayList<String>();
commands.add(command.toString());
// Defina ContainerLaunchContext para definir recursos locais, variáveis de ambiente, comandos e tokens para o construtor.
ContainerLaunchContext ctx = ContainerLaunchContext.newInstance(
localResources, shellEnv, commands, null, allTokens.duplicate(), null);
containerListener.addContainer(container.getId(), container);
nmClientAsync.startContainerAsync(container, ctx);
O objeto NMClientAsync e seu manipulador de eventos são responsáveis por lidar com eventos de contêiner. Ele inclui iniciar, parar, atualizações de status e erros para o contêiner.
Depois que o ApplicationMaster determinar que está concluído, ele precisa se desregistrar com o Cliente do AM-RM e, em seguida, parar o Cliente:
try {
amRMClient.unregisterApplicationMaster(appStatus, appMessage, null);
} catch (YarnException ex) {
LOG.error("Falha ao cancelar o registro da aplicação", ex);
} catch (IOException e) {
LOG.error("Falha ao cancelar o registro da aplicação", e);
}
amRMClient.stop();
O conteúdo acima é o código principal do ApplicationMaster. Após a edição, salve o conteúdo e saia do editor vim.
O Processo de Lançamento da Aplicação
O processo de lançamento de uma aplicação em um cluster Hadoop é o seguinte:
Compilando e Lançando a Aplicação
Depois que o código na seção anterior for concluído, você pode compilá-lo em um pacote Jar e enviá-lo para o cluster Hadoop usando uma ferramenta de construção como Maven e Gradle.
Como o processo de compilação requer rede para extrair as dependências relevantes, ele leva muito tempo (cerca de 1 hora no pico). Portanto, ignore o processo de compilação aqui e use o pacote Jar já compilado no diretório de instalação do Hadoop para experimentos subsequentes.
Nesta etapa, usamos o exemplo simples jar para executar a aplicação yarn em vez de construir o jar especificado pelo maven.
Use o comando yarn jar no terminal para enviar a execução. Os parâmetros envolvidos nos seguintes comandos são o caminho para o pacote Jar a ser executado, o nome da classe principal, o caminho para o pacote Jar enviado para o framework YARN, o número de comandos shell a serem executados e o número de contêineres:
/home/hadoop/hadoop/bin/yarn jar /home/hadoop/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar pi 3 3
Visualize a saída no terminal e você poderá ver o progresso da execução da aplicação.
Estimated value of Pi is 3.55555555555555555556
Durante a execução da tarefa, você pode ver os avisos de cada etapa na saída do terminal, como inicializando o Cliente, conectando-se ao RM e obtendo as informações do cluster.
Visualizando os Resultados da Execução da Aplicação
Clique duas vezes para abrir o navegador web Firefox na área de trabalho e insira a seguinte URL na barra de endereço para visualizar as informações de recursos dos nós no padrão YARN do cluster Hadoop:
http://localhost:8088
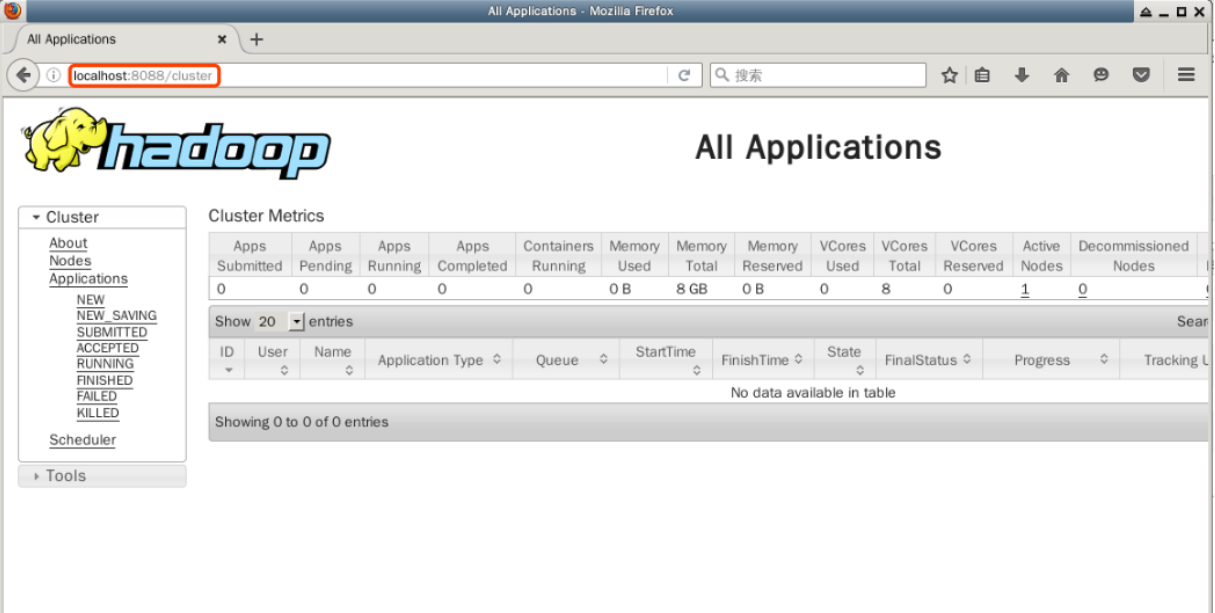
Nesta página, todas as informações sobre o cluster Hadoop são exibidas, incluindo o status dos nós, aplicações e agendadores.
O mais importante é o gerenciamento da aplicação, e podemos ver o status de execução da aplicação enviada aqui mais tarde. Por favor, não feche o navegador Firefox por enquanto.
Resumo
Com base na conclusão do cluster pseudo-distribuído Hadoop, este laboratório continua a nos ensinar a arquitetura, o princípio de funcionamento, a configuração e as técnicas de desenvolvimento e monitoramento do framework YARN. Muitos códigos e arquivos de configuração são fornecidos no curso, portanto, leia-os com atenção.


