
Introdução
Este laboratório trata principalmente dos fundamentos do Hadoop e foi escrito para estudantes com uma certa base em Linux, a fim de compreender a arquitetura do sistema de software Hadoop, bem como os métodos básicos de implantação.
Por favor, insira todo o código de exemplo no documento por conta própria e não apenas copie e cole, tanto quanto possível. Somente dessa forma você poderá se familiarizar mais com o código. Se tiver problemas, revise cuidadosamente a documentação, caso contrário, você pode ir ao fórum para obter ajuda e comunicação.
Introdução ao Hadoop
Lançado sob a Licença Apache 2.0, o Apache Hadoop é um framework de software de código aberto que suporta aplicações distribuídas intensivas em dados.
A biblioteca de software Apache Hadoop é um framework que permite o processamento distribuído de grandes conjuntos de dados em clusters de computação, usando um modelo de programação simples. Ele é projetado para escalar de um único servidor para milhares de máquinas, cada uma fornecendo computação e armazenamento locais, em vez de depender de hardware para fornecer alta disponibilidade.
Conceitos Principais
Um projeto Hadoop inclui principalmente os quatro módulos a seguir:
- Hadoop Common: Uma aplicação pública que fornece suporte para outros módulos Hadoop.
- Hadoop Distributed File System (HDFS): Um sistema de arquivos distribuído que fornece acesso de alta taxa de transferência aos dados da aplicação.
- Hadoop YARN: Framework de agendamento de tarefas e gerenciamento de recursos do cluster.
- Hadoop MapReduce: Um framework de computação paralela de conjuntos de dados em larga escala baseado no YARN.
Para usuários que são novos no Hadoop, você deve se concentrar no HDFS e no MapReduce. Como um framework de computação distribuída, o HDFS satisfaz os requisitos de armazenamento de dados do framework e o MapReduce satisfaz os requisitos de cálculo de dados do framework.
A imagem a seguir mostra a arquitetura básica de um cluster Hadoop:
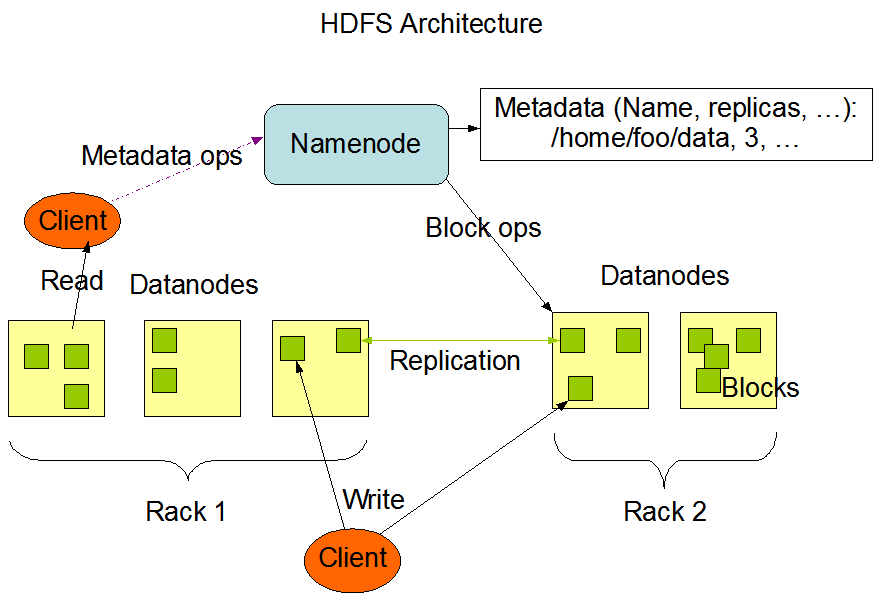
Esta imagem é citada do site oficial do Hadoop.
Ecossistema Hadoop
Assim como o Facebook derivou o repositório de dados Hive com base no Hadoop, existem muitos projetos de código aberto relacionados a ele na comunidade. Aqui estão alguns projetos ativos recentes:
- HBase: Um banco de dados distribuído e escalável que suporta o armazenamento de dados estruturados para grandes tabelas.
- Hive: Uma infraestrutura de repositório de dados que fornece resumo de dados e consultas temporárias.
- Pig: Linguagem de fluxo de dados avançada e framework de execução para computação paralela.
- ZooKeeper: Serviço de coordenação de alto desempenho para aplicações distribuídas.
- Spark: Um motor de cálculo de dados Hadoop rápido e versátil com um modelo de programação simples e expressivo que suporta ETL de dados (extração, transformação e carregamento), aprendizado de máquina, processamento de fluxo e computação gráfica.
Este laboratório começará com o Hadoop, introduzindo os usos básicos dos componentes relacionados.
Vale a pena notar que o Spark, um framework de computação de memória distribuída, nasceu do sistema Hadoop. Ele tem boa herança para componentes como HDFS e YARN, e também melhora algumas das deficiências existentes do Hadoop.
Alguns de vocês podem ter dúvidas sobre a sobreposição entre os cenários de uso do Hadoop e do Spark, mas aprender o padrão de trabalho e o padrão de programação do Hadoop ajudará a aprofundar a compreensão do framework Spark, razão pela qual você deve aprender Hadoop primeiro.
Implantação do Hadoop
Para iniciantes, há pouca diferença entre as versões do Hadoop posteriores à versão 2.0. Esta seção tomará a versão 3.3.6 como exemplo.
O Hadoop tem três padrões principais de implantação:
- Padrão Stand-alone: Executa em um único processo em um único computador.
- Padrão Pseudo-distribuído: Executa em vários processos em um único computador. Este padrão simula um cenário "multi-nó" em um único nó.
- Padrão Totalmente distribuído: Executa em um único processo em cada um de vários computadores.
Em seguida, instalaremos a versão Hadoop 3.3.6 em um único computador.
Configuração de Usuários e Grupos de Usuários
Dê um duplo clique para abrir o terminal Xfce em sua área de trabalho e insira o seguinte comando para criar um usuário chamado hadoop:
cd ~
sudo adduser hadoop
E, siga as instruções para inserir a senha do usuário hadoop; por exemplo, uma para definir a senha como hadoop.
Observação: Ao inserir a senha, não há nenhum prompt no comando. Você pode simplesmente pressionar a tecla Enter quando terminar.
Em seguida, adicione o usuário hadoop criado ao grupo de usuários sudo para dar ao usuário privilégios mais altos:
sudo usermod -G sudo hadoop
Verifique se o usuário hadoop foi adicionado ao grupo sudo inserindo o seguinte comando:
sudo cat /etc/group | grep hadoop
Você deve ver a seguinte saída:
sudo:x:27:shiyanlou,labex,hadoop
Instalação do JDK
Como mencionado no conteúdo anterior, o Hadoop é desenvolvido principalmente em Java. Portanto,, executá-lo requer um ambiente Java.
Diferentes versões do Hadoop têm diferenças sutis nos requisitos da versão Java. Para descobrir qual versão do JDK você deve escolher para o seu Hadoop, você pode ler Hadoop Java Versions no site Hadoop Wiki.
Mude o usuário:
su - hadoop
Instale a versão JDK 11 inserindo o seguinte comando no terminal:
sudo apt update
sudo apt install openjdk-11-jdk -y
Depois de instalá-lo com sucesso, verifique a versão atual do Java:
java -version
Visualize a saída:
openjdk version "11.0.22" 2024-01-16
OpenJDK Runtime Environment (build 11.0.22+7-post-Ubuntu-0ubuntu222.04.1)
OpenJDK 64-Bit Server VM (build 11.0.22+7-post-Ubuntu-0ubuntu222.04.1, mixed mode, sharing)
Configuração de Login SSH sem Senha
O objetivo de instalar e configurar o SSH é facilitar a execução de scripts relacionados ao daemon de gerenciamento remoto pelo Hadoop. Esses scripts exigem o serviço sshd.
Ao configurar, primeiro mude para o usuário hadoop. Insira o seguinte comando no terminal para fazer isso:
su hadoop
Se houver um prompt que exija que você insira uma senha, basta inserir a senha que foi especificada quando o usuário (hadoop) foi criado anteriormente:
Após mudar o usuário com sucesso, o prompt de comando deve ser como mostrado acima. As etapas subsequentes realizarão as operações como usuário hadoop.
Em seguida, gere a chave para o login SSH sem senha.
O chamado "sem senha" é para mudar o padrão de autenticação do SSH de login por senha para login por chave, de modo que cada componente do Hadoop não precise inserir a senha por meio da interação do usuário ao acessar um ao outro, o que pode reduzir muitas operações redundantes.
Primeiro, mude para o diretório home do usuário e, em seguida, use o comando ssh-keygen para gerar a chave RSA.
Por favor, insira o seguinte comando no terminal:
cd /home/hadoop
ssh-keygen -t rsa
Quando você encontrar informações como o local onde a chave é armazenada, você pode pressionar a tecla Enter para usar o valor padrão.
The key's randomart image is:
+---[RSA 3072]----+
| ..+. |
| . = . o |
| .o o * . |
| o .. . + o |
| = +.S. . + |
| + + +++. . |
| . B.O+. |
| o +oXo*E |
| =.+==o. |
+----[SHA256]-----+
Depois que a chave é gerada, a chave pública será gerada no diretório .ssh sob o diretório home do usuário.
A operação específica é mostrada na figura abaixo:
Em seguida, continue a inserir o seguinte comando para adicionar a chave pública gerada ao registro de autenticação do host. Dê a permissão de escrita ao arquivo authorized_keys, caso contrário, ele não será executado corretamente durante a verificação:
cat .ssh/id_rsa.pub >> .ssh/authorized_keys
chmod 600 .ssh/authorized_keys
Após a adição ter sido bem-sucedida, tente fazer login no localhost. Por favor, insira o seguinte comando no terminal:
ssh localhost
Ao fazer login pela primeira vez, você será solicitado a confirmar a impressão digital da chave pública, basta digitar yes e confirmar. Então, ao fazer login novamente, seria um login sem senha:
...
Welcome to Alibaba Cloud Elastic Compute Service !
To run a command as administrator (user "root"), use "sudo <command>".
See "man sudo_root" for details.
hadoop:~$
Você precisa digitar history -w ou sair do terminal para salvar as alterações para passar o script de verificação.
Instalação do Hadoop
Agora, você pode baixar o pacote de instalação do Hadoop. O site oficial fornece o link para download da versão mais recente do Hadoop. Você também pode usar o comando wget para baixar o pacote diretamente no terminal.
Insira o seguinte comando no terminal para baixar o pacote:
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz
Depois que o download for concluído, você pode usar o comando tar para extrair o pacote:
tar zxvf hadoop-3.3.6.tar.gz
sudo mv hadoop-3.3.6 hadoop
sudo chown -R hadoop:hadoop /home/hadoop
Você pode encontrar a localização do JAVA_HOME executando o comando dirname $(dirname $(readlink -f $(which java))) no terminal.
dirname $(readlink -f $(which java))
Em seguida, abra o arquivo .zshrc com um editor de texto no terminal:
vim /home/hadoop/.bashrc
Adicione o seguinte ao final do arquivo /home/hadoop/.bashrc:
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
export HADOOP_HOME=/home/hadoop/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
Salve e saia do editor vim. Em seguida, insira o comando source no terminal para ativar as variáveis de ambiente recém-adicionadas:
source /home/hadoop/.bashrc
Verifique a instalação executando o comando hadoop version no terminal.
hadoop@iZj6cgdabeniugz9ypibzxZ:~$ hadoop version
Hadoop 3.3.6
Source code repository https://github.com/apache/hadoop.git -r 1be78238728da9266a4f88195058f08fd012bf9c
Compiled by ubuntu on 2023-06-18T08:22Z
Compiled on platform linux-x86_64
Compiled with protoc 3.7.1
From source with checksum 5652179ad55f76cb287d9c633bb53bbd
This command was run using /home/hadoop/hadoop/share/hadoop/common/hadoop-common-3.3.6.jar
Configuração do Padrão Pseudo-Distribuído
Na maioria dos casos, o Hadoop é usado em um ambiente em cluster, ou seja, precisamos implantar o Hadoop em vários nós. Ao mesmo tempo, o Hadoop também pode ser executado em um único nó no padrão pseudo-distribuído, simulando cenários de vários nós por meio de vários processos Java independentes. Na fase inicial de aprendizado, não há necessidade de gastar muitos recursos para criar nós diferentes. Portanto, esta seção e os capítulos subsequentes usarão principalmente o padrão pseudo-distribuído para a implantação do "cluster" Hadoop.
Criar Diretórios
Para começar, crie os diretórios namenode e datanode dentro do diretório home do usuário Hadoop. Execute o comando abaixo para criar esses diretórios:
rm -rf ~/hadoopdata
mkdir -p ~/hadoopdata/hdfs/{namenode,datanode}
Em seguida, você precisa modificar os arquivos de configuração do Hadoop para fazê-lo rodar no padrão pseudo-distribuído.
Editar core-site.xml
Abra o arquivo core-site.xml com um editor de texto no terminal:
vim /home/hadoop/hadoop/etc/hadoop/core-site.xml
No arquivo de configuração, modifique o valor da tag configuration para o seguinte conteúdo:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
O item de configuração fs.defaultFS é usado para indicar a localização do sistema de arquivos que o cluster usa por padrão:
Salve o arquivo e saia do vim após a edição.
Editar hdfs-site.xml
Abra outro arquivo de configuração hdfs-site.xml:
vim /home/hadoop/hadoop/etc/hadoop/hdfs-site.xml
No arquivo de configuração, modifique o valor da tag configuration para o seguinte:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopdata/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopdata/hdfs/datanode</value>
</property>
</configuration>
Este item de configuração é usado para indicar o número de cópias de arquivos no HDFS, que é 3 por padrão. Como o implantamos de forma pseudo-distribuída em um único nó, ele é modificado para 1:
Salve o arquivo e saia do vim após a edição.
Editar hadoop-env.sh
Em seguida, edite o arquivo hadoop-env.sh:
vim /home/hadoop/hadoop/etc/hadoop/hadoop-env.sh
Altere o valor de JAVA_HOME para a localização real do JDK instalado, ou seja, /usr/lib/jvm/java-11-openjdk-amd64.
Observação: Você pode usar o comando
echo $JAVA_HOMEpara verificar a localização real do JDK instalado.
Salve o arquivo e saia do editor vim após a edição.
Editar yarn-site.xml
Em seguida, edite o arquivo yarn-site.xml:
vim /home/hadoop/hadoop/etc/hadoop/yarn-site.xml
Adicione o seguinte à tag configuration:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
Salve o arquivo e saia do editor vim após a edição.
Editar mapred-site.xml
Finalmente, você precisa editar o arquivo mapred-site.xml.
Abra o arquivo com o editor vim:
vim /home/hadoop/hadoop/etc/hadoop/mapred-site.xml
Da mesma forma, adicione o seguinte à tag configuration:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/home/hadoop/hadoop</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/home/hadoop/hadoop</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/home/hadoop/hadoop</value>
</property>
</configuration>
Salve o arquivo e saia do editor vim após a edição.
Teste de Inicialização do Hadoop
Primeiro, abra o terminal Xfce na área de trabalho e mude para o usuário Hadoop:
su -l hadoop
A inicialização do HDFS é principalmente a formatação:
/home/hadoop/hadoop/bin/hdfs namenode -format
Dica: você precisa excluir o diretório de dados do HDFS antes de formatar.
Veja esta mensagem, você quer dizer que foi bem-sucedido:
2024-02-29 18:24:53,887 INFO common.Storage: Storage directory /home/hadoop/hadoopdata/hdfs/namenode has been successfully formatted.
Você precisa digitar history -w ou sair do terminal para salvar o histórico para passar no script de verificação.
Iniciar HDFS
Uma vez que a inicialização do HDFS esteja completa, você pode iniciar os daemons para NameNode e DataNode. Tendo sido iniciado, as aplicações Hadoop (como tarefas MapReduce) podem ler e escrever arquivos de/para o HDFS.
Inicie o daemon digitando o seguinte comando no terminal:
/home/hadoop/hadoop/sbin/start-dfs.sh
Veja a saída:
Starting namenodes on [localhost]
Starting datanodes
Starting secondary namenodes [iZj6cjditp4l7k0fylhhfbZ]
iZj6cjditp4l7k0fylhhfbZ: Warning: Permanently added 'izj6cjditp4l7k0fylhhfbz' (ED25519) to the list of known hosts.
Para confirmar que o Hadoop foi executado com sucesso no padrão pseudo-distribuído, você pode usar a ferramenta de visualização de processos do Java jps para ver se há um processo correspondente.
Digite o seguinte comando no terminal:
jps
Como mostrado na figura, se você vir os processos de NameNode, DataNode e SecondaryNameNode, isso indica que o serviço do Hadoop está funcionando corretamente:
Visualizar Arquivos de Log e WebUI
Quando o Hadoop falha ao iniciar ou erros são relatados enquanto uma tarefa (ou outra coisa) está sendo executada, além das informações de prompt do terminal, visualizar os logs é a melhor maneira de localizar um problema. A maioria dos problemas pode ser encontrada através dos logs do software relacionado para encontrar a causa e uma solução. Como um aprendiz no campo de big data, a capacidade de analisar logs é tão importante quanto a capacidade de aprender a estrutura de computação e deve ser levada a sério.
A saída padrão dos logs do daemon do Hadoop está no diretório de logs (logs) sob o diretório de instalação. Digite o seguinte comando no terminal para entrar no diretório de logs:
ls /home/hadoop/hadoop/logs
hadoop-hadoop-datanode-iZj6cjditp4l7k0fylhhfbZ.log
hadoop-hadoop-datanode-iZj6cjditp4l7k0fylhhfbZ.out
hadoop-hadoop-namenode-iZj6cjditp4l7k0fylhhfbZ.log
hadoop-hadoop-namenode-iZj6cjditp4l7k0fylhhfbZ.out
hadoop-hadoop-secondarynamenode-iZj6cjditp4l7k0fylhhfbZ.log
hadoop-hadoop-secondarynamenode-iZj6cjditp4l7k0fylhhfbZ.out
SecurityAuth-hadoop.audit
Você pode usar o editor vim para visualizar qualquer arquivo de log.
Após o HDFS ter sido iniciado, uma página web que exibe o status do cluster também é fornecida pelo serviço web interno. Mude para o topo da VM LabEx e clique em "Web 8088" para abrir a página web:
Após abrir a página web, você pode ver a visão geral do cluster, o status do DataNode e assim por diante:
Sinta-se à vontade para clicar no menu no topo da página para explorar as dicas e recursos.
Você precisa digitar history -w ou sair do terminal para salvar o histórico para passar no script de verificação.
Teste de Upload de Arquivos HDFS
Uma vez que o HDFS está em execução, ele pode ser considerado como um sistema de arquivos. Aqui, para testar a funcionalidade de upload de arquivos, você precisa criar um diretório (um nível de profundidade por etapa, até o nível de diretório necessário) e tentar fazer o upload de alguns arquivos no sistema Linux para o HDFS:
cd ~
/home/hadoop/hadoop/bin/hdfs dfs -mkdir /user
/home/hadoop/hadoop/bin/hdfs dfs -mkdir /user/hadoop
Após o diretório ter sido criado com sucesso, use o comando hdfs dfs -put para fazer o upload dos arquivos no disco local (os arquivos de configuração do Hadoop selecionados aleatoriamente aqui) para o HDFS:
/home/hadoop/hadoop/bin/hdfs dfs -put /home/hadoop/hadoop/etc/hadoop /user/hadoop/input
Casos de Teste PI
A grande maioria das aplicações Hadoop implantadas em ambientes de produção do mundo real e que resolvem problemas do mundo real são baseadas no modelo de programação MapReduce representado por WordCount. Portanto, WordCount pode ser usado como um programa "HelloWorld" para começar com o Hadoop, ou você pode adicionar suas próprias ideias para resolver problemas específicos.
Iniciar a Tarefa
No final da seção anterior, carregamos alguns arquivos de configuração para o HDFS, como exemplo. Em seguida, podemos tentar executar o caso de teste PI para obter estatísticas de frequência de palavras desses arquivos e exibi-las de acordo com nossas regras de filtragem.
Inicie o serviço de cálculo YARN no terminal primeiro:
/home/hadoop/hadoop/sbin/start-yarn.sh
Em seguida, digite o seguinte comando para iniciar a tarefa:
/home/hadoop/hadoop/bin/hadoop jar /home/hadoop/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar pi 3 3
Visualize os resultados da saída:
Estimated value of Pi is 3.55555555555555555556
Entre os parâmetros acima, existem três parâmetros sobre o caminho. Eles são: a localização do pacote jar, a localização do arquivo de entrada e a localização de armazenamento do resultado da saída. Ao especificar o caminho, você deve desenvolver o hábito de especificar um caminho absoluto. Isso ajudará a localizar problemas rapidamente e entregar o trabalho em breve.
Complete a tarefa, você pode visualizar os Resultados.
Fechar o Serviço HDFS
Após o cálculo, se não houver outro programa de software que use os arquivos no HDFS, você deve fechar o daemon HDFS a tempo.
Como usuário de clusters distribuídos e estruturas de computação relacionadas, você deve desenvolver o bom hábito de verificar ativamente o status do hardware e software relacionados sempre que envolver a abertura e fechamento do cluster, instalação de hardware e software ou qualquer tipo de atualização.
Use o seguinte comando no terminal para fechar os daemons HDFS e YARN:
/home/hadoop/hadoop/sbin/stop-yarn.sh
/home/hadoop/hadoop/sbin/stop-dfs.sh
Você precisa digitar history -w ou sair do terminal para salvar o histórico para passar no script de verificação.
Resumo
Este laboratório introduziu a arquitetura do Hadoop, a instalação e os métodos de implantação do padrão stand-alone e do padrão pseudo-distribuído, e executou o WordCount para testes básicos.
Aqui estão os principais pontos deste laboratório:
- Arquitetura Hadoop
- Módulo principal do Hadoop
- Como usar o padrão stand-alone do Hadoop
- Implantação do padrão pseudo-distribuído do Hadoop
- Usos básicos do HDFS
- Caso de teste WordCount
Em geral, o Hadoop é uma estrutura de computação e armazenamento comumente usada no campo de big data. Suas funções precisam ser exploradas mais a fundo. Por favor, mantenha o hábito de consultar materiais técnicos e continue aprendendo os próximos passos.


