Introducción
En Python, el snake case es una convención de nomenclatura en la que las palabras se separan por guiones bajos. Este estilo de nomenclatura se utiliza comúnmente para variables, funciones y otros identificadores en Python. Por ejemplo, calculate_total_price y user_authentication están en formato snake case.
A veces, podemos encontrar cadenas de texto en diferentes formatos, como camelCase, PascalCase, o incluso cadenas con espacios y guiones. En tales situaciones, necesitamos convertir estas cadenas a snake case para mantener la coherencia en nuestro código.
En este laboratorio (lab), aprenderás cómo escribir una función de Python que convierta cadenas de varios formatos a snake case.
Comprendiendo el problema
Antes de escribir nuestra función de conversión a snake case, entendamos lo que necesitamos lograr:
- Necesitamos convertir una cadena de cualquier formato a snake case.
- Snake case significa que todas las letras son minúsculas y hay guiones bajos entre las palabras.
- Necesitamos manejar diferentes formatos de entrada:
- camelCase (por ejemplo,
camelCase→camel_case) - Cadenas con espacios (por ejemplo,
some text→some_text) - Cadenas con formato mixto (por ejemplo, guiones, guiones bajos y mayúsculas y minúsculas mezcladas)
- camelCase (por ejemplo,
Comencemos creando un nuevo archivo de Python para nuestra función de snake case. En el WebIDE, navega al directorio del proyecto y crea un nuevo archivo llamado snake_case.py:
## This function will convert a string to snake case
def snake(s):
## We'll implement this function step by step
pass ## Placeholder for now
## Test with a simple example
if __name__ == "__main__":
test_string = "helloWorld"
result = snake(test_string)
print(f"Original: {test_string}")
print(f"Snake case: {result}")
Guarda este archivo. En el siguiente paso, comenzaremos a implementar la función.
Por ahora, ejecutemos nuestra función de marcador de posición para asegurarnos de que nuestro archivo esté configurado correctamente. Abre una terminal y ejecuta:
python3 ~/project/snake_case.py
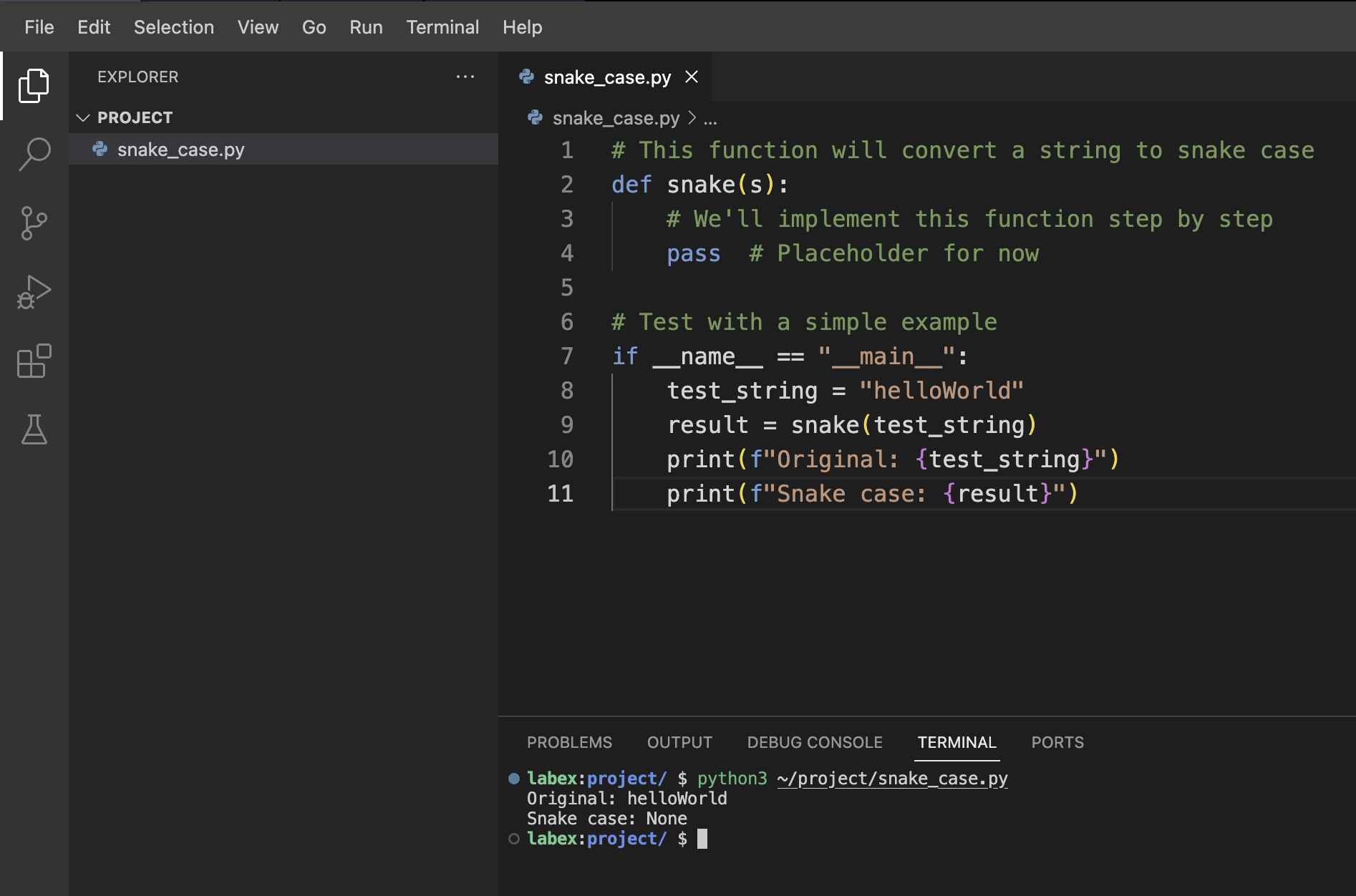
Deberías ver una salida como esta:
Original: helloWorld
Snake case: None
El resultado es None porque nuestra función actualmente solo devuelve el valor predeterminado de Python None. En el siguiente paso, agregaremos la lógica real de conversión.
Uso de expresiones regulares para la coincidencia de patrones
Para convertir cadenas a snake case, utilizaremos expresiones regulares (regex) para identificar los límites de las palabras. El módulo re en Python proporciona poderosas capacidades de coincidencia de patrones que podemos utilizar para esta tarea.
Actualicemos nuestra función para manejar cadenas en camelCase:
- Primero, necesitamos identificar el patrón en el que una letra minúscula va seguida de una letra mayúscula (como en "camelCase").
- Luego, insertaremos un espacio entre ellas.
- Finalmente, convertiremos todo a minúsculas y reemplazaremos los espacios por guiones bajos.
Actualiza tu archivo snake_case.py con esta función mejorada:
import re
def snake(s):
## Replace pattern of a lowercase letter followed by uppercase with lowercase, space, uppercase
s1 = re.sub('([a-z])([A-Z])', r'\1 \2', s)
## Replace spaces with underscores and convert to lowercase
return s1.lower().replace(' ', '_')
## Test with a simple example
if __name__ == "__main__":
test_string = "helloWorld"
result = snake(test_string)
print(f"Original: {test_string}")
print(f"Snake case: {result}")
Desglosemos lo que hace esta función:
re.sub('([a-z])([A-Z])', r'\1 \2', s)busca patrones en los que una letra minúscula([a-z])va seguida de una letra mayúscula([A-Z]). Luego, reemplaza este patrón con las mismas letras pero agrega un espacio entre ellas utilizando\1y\2, que se refieren a los grupos capturados.- Luego convertimos todo a minúsculas con
lower()y reemplazamos los espacios por guiones bajos.
Ejecuta tu script nuevamente para ver si funciona con cadenas en camelCase:
python3 ~/project/snake_case.py
La salida ahora debería ser:
Original: helloWorld
Snake case: hello_world
¡Genial! Nuestra función ahora puede manejar cadenas en camelCase. En el siguiente paso, la mejoraremos para manejar casos más complejos.
Manejo de patrones más complejos
Nuestra función actual funciona para camelCase, pero necesitamos mejorarla para manejar patrones adicionales como:
- PascalCase (por ejemplo,
HelloWorld) - Cadenas con guiones (por ejemplo,
hello-world) - Cadenas que ya tienen guiones bajos (por ejemplo,
hello_world)
Actualicemos nuestra función para manejar estos casos:
import re
def snake(s):
## Replace hyphens with spaces
s = s.replace('-', ' ')
## Handle PascalCase pattern (sequences of uppercase letters)
s = re.sub('([A-Z]+)', r' \1', s)
## Handle camelCase pattern (lowercase followed by uppercase)
s = re.sub('([a-z])([A-Z])', r'\1 \2', s)
## Split by spaces, join with underscores, and convert to lowercase
return '_'.join(s.split()).lower()
## Test with multiple examples
if __name__ == "__main__":
test_strings = [
"helloWorld",
"HelloWorld",
"hello-world",
"hello_world",
"some text"
]
for test in test_strings:
result = snake(test)
print(f"Original: {test}")
print(f"Snake case: {result}")
print("-" * 20)
Las mejoras que hicimos:
- Primero, reemplazamos cualquier guión con un espacio.
- La nueva expresión regular
re.sub('([A-Z]+)', r' \1', s)agrega un espacio antes de cualquier secuencia de letras mayúsculas, lo que ayuda con PascalCase. - Mantenemos nuestra expresión regular para manejar camelCase.
- Finalmente, dividimos la cadena por espacios, la unimos con guiones bajos y la convertimos a minúsculas, lo que maneja cualquier espacio restante y asegura una salida consistente.
Ejecuta tu script para probar con varios formatos de entrada:
python3 ~/project/snake_case.py
Deberías ver una salida como esta:
Original: helloWorld
Snake case: hello_world
--------------------
Original: HelloWorld
Snake case: hello_world
--------------------
Original: hello-world
Snake case: hello_world
--------------------
Original: hello_world
Snake case: hello_world
--------------------
Original: some text
Snake case: some_text
--------------------
Nuestra función ahora es más robusta y puede manejar varios formatos de entrada. En el siguiente paso, haremos nuestros refinamientos finales y la probaremos con la suite de pruebas completa.
Implementación final y pruebas
Ahora completemos nuestra implementación para manejar todos los casos requeridos y verifiquemos que pase todas las pruebas.
Actualiza tu archivo snake_case.py con la implementación final:
import re
def snake(s):
## Replace hyphens with spaces
s = s.replace('-', ' ')
## Handle PascalCase pattern
s = re.sub('([A-Z][a-z]+)', r' \1', s)
## Handle sequences of uppercase letters
s = re.sub('([A-Z]+)', r' \1', s)
## Split by whitespace and join with underscores
return '_'.join(s.split()).lower()
## Test with a complex example
if __name__ == "__main__":
test_string = "some-mixed_string With spaces_underscores-and-hyphens"
result = snake(test_string)
print(f"Original: {test_string}")
print(f"Snake case: {result}")
Esta implementación final:
- Reemplaza los guiones con espacios.
- Agrega un espacio antes de patrones como "Word" con
re.sub('([A-Z][a-z]+)', r' \1', s). - Agrega un espacio antes de secuencias de letras mayúsculas con
re.sub('([A-Z]+)', r' \1', s). - Divide por espacios, une con guiones bajos y convierte a minúsculas.
Ahora ejecutemos nuestra función contra la suite de pruebas creada en el paso de configuración:
python3 ~/project/test_snake.py
Si tu implementación es correcta, deberías ver:
All tests passed! Your snake case function works correctly.
¡Felicidades! Has implementado con éxito una función robusta de conversión a snake case que puede manejar varios formatos de entrada.
Asegurémonos de que nuestra función siga con precisión la especificación probándola con los ejemplos del problema original:
## Add this to the end of your snake_case.py file:
if __name__ == "__main__":
examples = [
'camelCase',
'some text',
'some-mixed_string With spaces_underscores-and-hyphens',
'AllThe-small Things'
]
for ex in examples:
result = snake(ex)
print(f"Original: {ex}")
print(f"Snake case: {result}")
print("-" * 20)
Ejecuta tu script actualizado:
python3 ~/project/snake_case.py
Deberías ver que todos los ejemplos se convierten correctamente a snake case:
Original: some-mixed_string With spaces_underscores-and-hyphens
Snake case: some_mixed_string_with_spaces_underscores_and_hyphens
Original: camelCase
Snake case: camel_case
--------------------
Original: some text
Snake case: some_text
--------------------
Original: some-mixed_string With spaces_underscores-and-hyphens
Snake case: some_mixed_string_with_spaces_underscores_and_hyphens
--------------------
Original: AllThe-small Things
Snake case: all_the_small_things
--------------------
Resumen
En este laboratorio, aprendiste cómo crear una función de Python que convierte cadenas de varios formatos a snake case. Esto es lo que lograste:
- Aprendiste cómo se pueden utilizar las expresiones regulares para la coincidencia de patrones y la transformación de cadenas.
- Implementaste una función que puede manejar diferentes formatos de entrada:
- camelCase (por ejemplo,
camelCase→camel_case) - PascalCase (por ejemplo,
HelloWorld→hello_world) - Cadenas con espacios (por ejemplo,
some text→some_text) - Cadenas con guiones (por ejemplo,
hello-world→hello_world) - Formatos mixtos con varios delimitadores y mayúsculas/minúsculas.
- camelCase (por ejemplo,
Las técnicas clave que utilizaste:
- Expresiones regulares con grupos de captura utilizando
re.sub() - Métodos de cadenas como
replace(),lower(),split()yjoin() - Reconocimiento de patrones para diferentes convenciones de nomenclatura.
Estas habilidades son valiosas para la limpieza de datos, el procesamiento de entrada de texto y el mantenimiento de estándares de codificación consistentes. La capacidad de convertir entre diferentes formatos de mayúsculas y minúsculas es especialmente útil cuando se trabaja con APIs o bibliotecas que utilizan diferentes convenciones de nomenclatura.