
简介
在本教程中,我们将探索 Python 中的 defaultdict 数据结构,它是标准字典的一个强大变体,能够优雅地处理缺失键的情况。具体来说,我们将学习如何创建一个默认值为 0 的 defaultdict,这在 Python 程序中进行计数和累加值时特别有用。
在本实验结束时,你将理解什么是 defaultdict,如何创建一个默认值为 0 的 defaultdict,以及如何在实际场景中应用它来编写更优雅且抗错误的代码。
理解常规字典的问题
在深入探讨 defaultdict 之前,让我们先了解一下常规字典的局限性,而 defaultdict 正是为解决这些局限性而设计的。
KeyError 问题
在 Python 中,标准字典(dict)用于存储键值对。然而,当你尝试访问常规字典中不存在的键时,Python 会引发 KeyError。
让我们创建一个简单的示例来演示这个问题:
- 在编辑器中创建一个名为
regular_dict_demo.py的新文件:
## 创建一个常规字典来统计水果数量
fruit_counts = {}
## 尝试增加 'apple' 的计数
try:
fruit_counts['apple'] += 1
except KeyError:
print("KeyError: 'apple' 键在字典中不存在")
## 使用常规字典的正确方法
if 'banana' in fruit_counts:
fruit_counts['banana'] += 1
else:
fruit_counts['banana'] = 1
print(f"水果计数:{fruit_counts}")
- 在终端中运行脚本:
python3 regular_dict_demo.py
你应该会看到类似以下的输出:
KeyError: 'apple' 键在字典中不存在
水果计数: {'banana': 1}
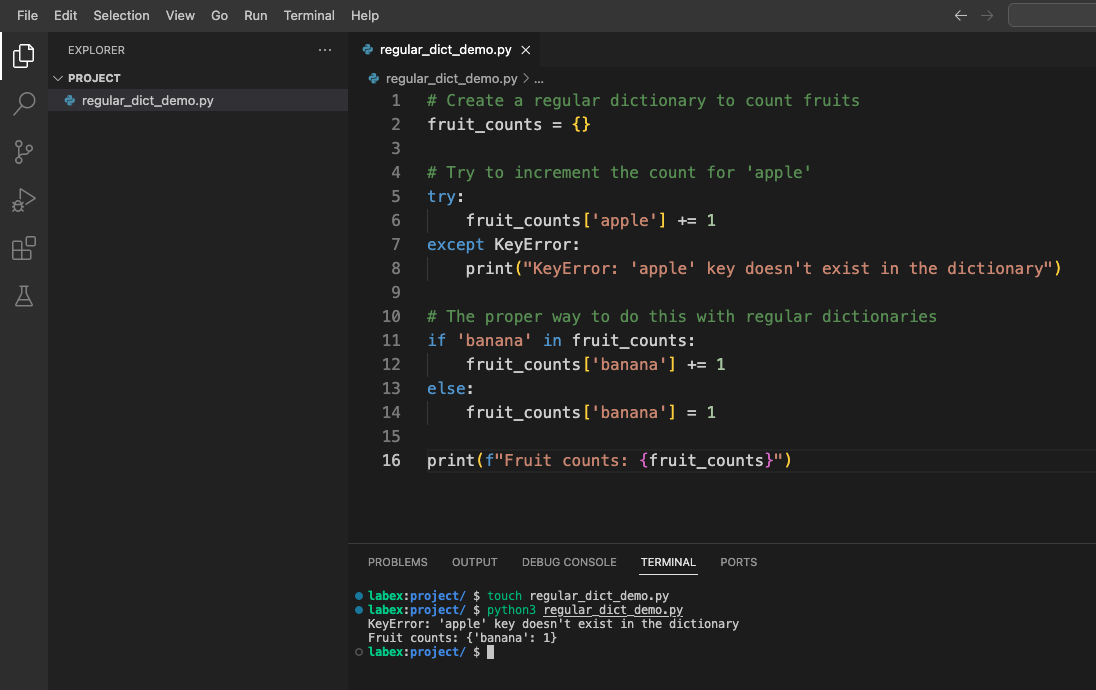
如你所见,尝试增加不存在的键的计数会导致错误。常见的解决方法是在尝试访问键之前检查它是否存在,这会导致代码更加冗长。
这就是 defaultdict 发挥作用的地方——它在访问时通过使用默认值自动创建缺失的键来处理这个问题。
介绍默认值为 0 的 defaultdict
既然我们已经了解了常规字典的问题,那么让我们来学习如何使用 defaultdict 来解决它。
什么是 defaultdict?
defaultdict 是 Python 内置 dict 类的一个子类,它接受一个函数(称为“默认工厂函数”)作为其第一个参数。当访问一个不存在的键时,defaultdict 会自动使用默认工厂函数返回的值创建该键。
创建默认值为 0 的 defaultdict
让我们创建一个 defaultdict,为任何缺失的键提供默认值 0:
- 在编辑器中创建一个名为
default_dict_zero.py的新文件:
## 首先,从 collections 模块导入 defaultdict 类
from collections import defaultdict
## 方法 1:使用 int 作为默认工厂函数
## 不带参数调用 int() 函数会返回 0
counter = defaultdict(int)
print("计数器的初始状态:", dict(counter))
## 访问一个尚不存在的键
print("'apple' 的值(之前):", counter['apple'])
## 增加计数
counter['apple'] += 1
counter['apple'] += 1
counter['banana'] += 1
print("'apple' 的值(之后):", counter['apple'])
print("操作后的字典:", dict(counter))
## 方法 2:使用 lambda 函数(另一种方法)
counter2 = defaultdict(lambda: 0)
print("\n使用 lambda 函数:")
print("'cherry' 的值(之前):", counter2['cherry'])
counter2['cherry'] += 5
print("'cherry' 的值(之后):", counter2['cherry'])
print("操作后的字典:", dict(counter2))
- 在终端中运行脚本:
python3 default_dict_zero.py
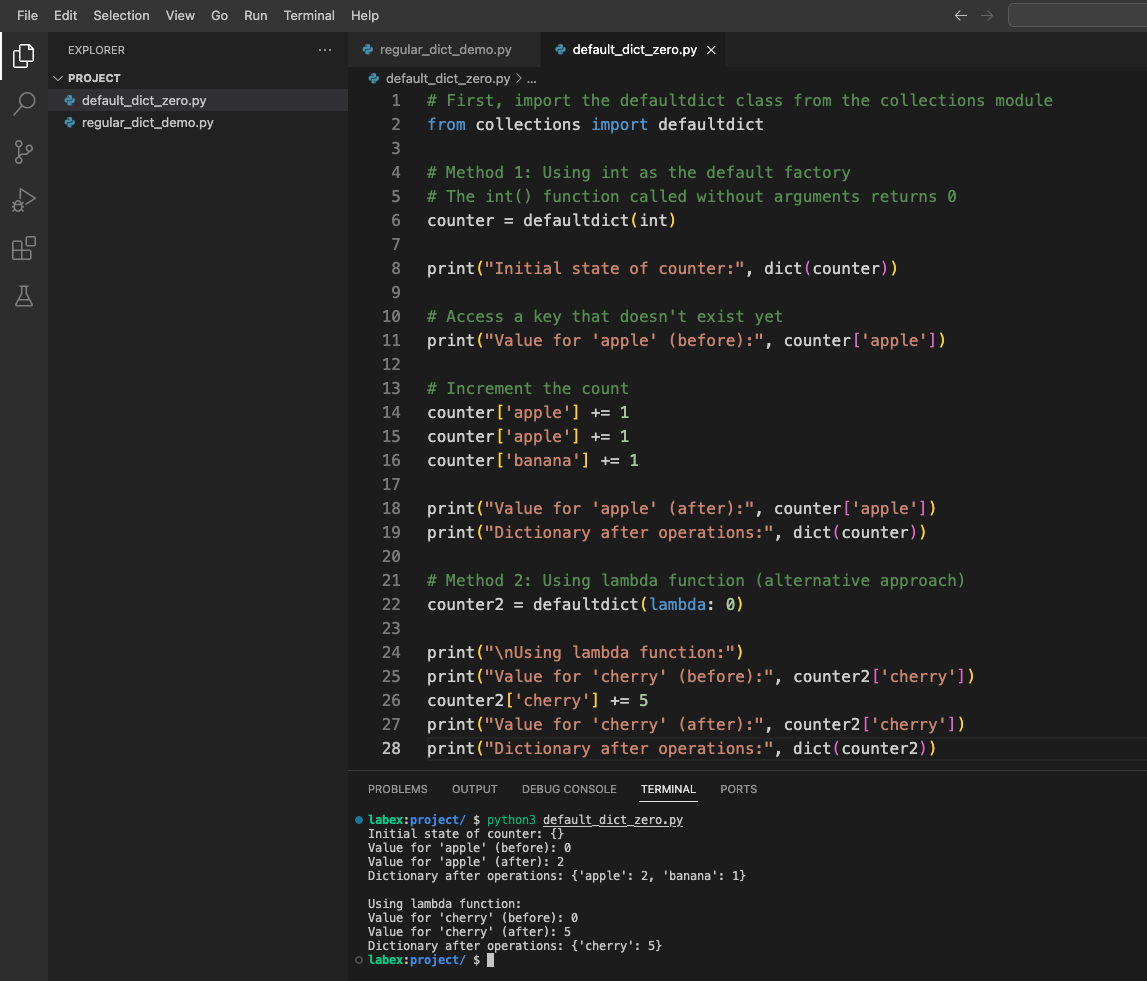
你应该会看到类似以下的输出:
计数器的初始状态: {}
'apple' 的值(之前): 0
'apple' 的值(之后): 2
操作后的字典: {'apple': 2, 'banana': 1}
使用 lambda 函数:
'cherry' 的值(之前): 0
'cherry' 的值(之后): 5
操作后的字典: {'cherry': 5}
它是如何工作的
当我们创建 defaultdict(int) 时,我们告诉 Python 使用 int() 函数作为默认工厂函数。不带参数调用时,int() 返回 0,这将成为任何缺失键的默认值。
同样,我们可以使用一个 lambda 函数 lambda: 0,它在被调用时只返回 0。
注意我们如何能够直接访问并增加之前不存在的键的值,而不会出现任何错误。
实际应用案例:统计单词频率
默认值为 0 的 defaultdict 最常见的应用之一就是统计频率。让我们通过实现一个单词频率计数器来演示这个实际应用案例。
- 在编辑器中创建一个名为
word_counter.py的新文件:
from collections import defaultdict
def count_word_frequencies(text):
## 创建一个默认值为 0 的 defaultdict
word_counts = defaultdict(int)
## 将文本拆分成单词并转换为小写
words = text.lower().split()
## 清理每个单词(去除标点符号)并统计出现次数
for word in words:
## 去除常见标点符号
clean_word = word.strip('.,!?:;()"\'')
if clean_word: ## 跳过空字符串
word_counts[clean_word] += 1
return word_counts
## 使用示例文本测试函数
sample_text = """
Python 很棒!Python 很容易学,而且 Python 非常强大。
使用 Python,你可以创建 Web 应用程序、分析数据、构建游戏,
还能自动化任务。Python 的语法清晰易读。
"""
word_frequencies = count_word_frequencies(sample_text)
## 打印结果
print("单词频率:")
for word, count in sorted(word_frequencies.items()):
print(f" {word}: {count}")
## 找出最常见的单词
print("\n最常见的单词:")
sorted_words = sorted(word_frequencies.items(), key=lambda x: x[1], reverse=True)
for word, count in sorted_words[:5]: ## 前 5 个单词
print(f" {word}: {count}")
- 在终端中运行脚本:
python3 word_counter.py
你应该会看到类似以下的输出:
单词频率:
amazing: 1
analyze: 1
and: 3
applications: 1
automate: 1
build: 1
can: 1
clear: 1
create: 1
data: 1
easy: 1
games: 1
is: 4
learn: 1
powerful: 1
python: 4
python's: 1
readable: 1
syntax: 1
tasks: 1
to: 1
very: 1
web: 1
with: 1
you: 1
最常见的单词:
python: 4
is: 4
and: 3
amazing: 1
easy: 1
这是如何工作的
- 我们创建一个
defaultdict(int)来存储单词计数,默认值为 0 - 我们处理文本中的每个单词,清理标点符号
- 我们使用
word_counts[word] += 1简单地增加每个单词的计数 - 对于首次出现的单词,会自动分配默认值 0
这种方法比使用带有存在检查的常规字典要简洁得多且效率更高。
使用默认值为 0 的 defaultdict 的好处
- 简化代码:无需在增加计数前检查键是否存在
- 减少代码行数:去除了样板式的键存在检查
- 减少错误:消除了潜在的
KeyError异常 - 更具可读性:使计数逻辑更清晰、简洁
默认值为 0 的 defaultdict 对于任何涉及计数或累加值的任务都特别有用,例如:
- 频率分析
- 直方图
- 按类别聚合数据
- 跟踪日志或数据集中的出现次数
性能比较:defaultdict 与常规字典
让我们比较一下默认值为 0 的 defaultdict 和常规字典在常见计数任务中的性能。这将帮助你了解何时选择使用其中一个。
- 在编辑器中创建一个名为
performance_comparison.py的新文件:
import time
from collections import defaultdict
def count_with_regular_dict(data):
"""使用常规字典统计频率。"""
counts = {}
for item in data:
if item in counts:
counts[item] += 1
else:
counts[item] = 1
return counts
def count_with_defaultdict(data):
"""使用默认值为 0 的 defaultdict 统计频率。"""
counts = defaultdict(int)
for item in data:
counts[item] += 1
return counts
## 生成测试数据 - 0 到 99 之间的随机数列表
import random
random.seed(42) ## 为了可重复的结果
data = [random.randint(0, 99) for _ in range(1000000)]
## 测量常规字典方法的时间
start_time = time.time()
result1 = count_with_regular_dict(data)
regular_dict_time = time.time() - start_time
## 测量 defaultdict 方法的时间
start_time = time.time()
result2 = count_with_defaultdict(data)
defaultdict_time = time.time() - start_time
## 打印结果
print(f"常规字典时间:{regular_dict_time:.4f} 秒")
print(f"defaultdict 时间: {defaultdict_time:.4f} 秒")
print(f"defaultdict 快 {regular_dict_time/defaultdict_time:.2f} 倍")
## 验证两种方法的结果是否相同
assert dict(result2) == result1, "计数结果不匹配!"
print("\n两种方法产生了相同的计数结果 ✓")
## 打印一些计数结果示例
print("\n计数结果示例(前 5 项):")
for i, (key, value) in enumerate(sorted(result1.items())):
if i >= 5:
break
print(f" 数字 {key}: {value} 次出现")
- 在终端中运行脚本:
python3 performance_comparison.py
你应该会看到类似以下的输出:
常规字典时间: 0.1075 秒
defaultdict 时间: 0.0963 秒
defaultdict 快 1.12 倍
两种方法产生了相同的计数结果 ✓
计数结果示例(前 5 项):
数字 0: 10192 次出现
数字 1: 9949 次出现
数字 2: 9929 次出现
数字 3: 9881 次出现
数字 4: 9922 次出现
注意:根据你的系统,你得到的精确计时结果可能会有所不同。
结果分析
性能比较表明,在计数任务中,defaultdict 通常比常规字典更快,原因如下:
- 它无需进行键存在检查(
if key in dictionary) - 它减少了每个项目的字典查找次数
- 它简化了代码,这可能会使 Python 解释器进行优化
除了性能优势外,defaultdict 还具有以下优点:
- 代码简洁性:代码更简洁且易读
- 认知负担减轻:你无需记住处理缺失键的情况
- 出错机会减少:代码越少,出错的机会就越少
这使得默认值为 0 的 defaultdict 成为 Python 中计数操作、频率分析和其他累加任务的绝佳选择。
总结
在本实验中,你已经了解了 Python 的 defaultdict 以及如何使用默认值 0 来使用它。让我们回顾一下我们所涵盖的内容:
- 我们确定了常规字典的局限性,即在访问不存在的键时会引发
KeyError - 我们学习了如何使用
defaultdict(int)和defaultdict(lambda: 0)创建默认值为 0 的defaultdict - 我们通过实现一个单词频率计数器探索了一个实际用例
- 我们比较了
defaultdict和常规字典的性能,发现defaultdict不仅更方便,而且在计数任务中更快
默认值为 0 的 defaultdict 是一个强大的工具,它简化了 Python 中的计数、累加和频率分析。通过自动处理缺失的键,它使你的代码更简洁、更高效且更不易出错。
这种模式通常用于:
- 数据处理与分析
- 自然语言处理
- 日志分析
- 游戏开发(用于评分系统)
- 任何涉及计数器或累加器的场景
通过掌握默认值为 0 的 defaultdict,你在 Python 编程工具包中添加了一个重要工具,这将帮助你编写更优雅、高效的代码。


