
Introduction
Dans ce laboratoire, vous découvrirez les principes fondamentaux de la construction d'un modèle d'apprentissage automatique (machine learning) à l'aide de l'une des bibliothèques Python les plus populaires : scikit-learn. Nous nous concentrerons sur la régression linéaire, un algorithme simple mais puissant utilisé pour prédire une valeur continue, comme un prix ou une température.
Notre objectif est de construire un modèle capable de prédire le prix médian des logements dans les districts de Californie. Nous utiliserons le jeu de données sur les logements en Californie, qui est commodément inclus dans scikit-learn.
Tout au long de ce laboratoire, vous apprendrez à :
- Charger un jeu de données depuis
scikit-learn. - Préparer et diviser les données pour l'entraînement et le test.
- Créer et entraîner un modèle de régression linéaire.
- Utiliser le modèle entraîné pour effectuer des prédictions.
- Visualiser les résultats pour comprendre les performances du modèle.
Vous effectuerez toutes les tâches au sein du WebIDE. Commençons !
Charger le jeu de données des logements en Californie avec datasets.fetch_california_housing()
Dans cette étape, nous commencerons par charger le jeu de données pour notre modèle. scikit-learn est fourni avec plusieurs jeux de données intégrés, parfaits pour l'apprentissage et la pratique. Nous utiliserons le jeu de données sur les logements en Californie.
Tout d'abord, nous devons créer un script Python. Un fichier nommé main.py a déjà été créé pour vous dans le répertoire ~/project. Vous pouvez le trouver dans l'explorateur de fichiers sur le côté gauche du WebIDE.
Ouvrez main.py et ajoutez le code suivant. Ce code importe les bibliothèques nécessaires (fetch_california_housing depuis sklearn.datasets et pandas) et charge le jeu de données. Nous utiliserons pandas pour convertir les données en un DataFrame, qui est une structure de données tabulaire facile à visualiser et à manipuler.
Veuillez ajouter le code suivant à main.py :
import pandas as pd
from sklearn.datasets import fetch_california_housing
## Load the California housing dataset
california = fetch_california_housing()
## Create a DataFrame
california_df = pd.DataFrame(california.data, columns=california.feature_names)
california_df['MedHouseVal'] = california.target
## Print the first 5 rows of the DataFrame
print("California Housing Dataset:")
print(california_df.head())
Maintenant, exécutons le script pour voir le résultat. Ouvrez un terminal dans le WebIDE (vous pouvez utiliser le menu "Terminal" -> "New Terminal") et exécutez la commande suivante :
python3 main.py
Vous devriez voir les cinq premières lignes du jeu de données s'afficher dans la console. La colonne MedHouseVal est notre variable cible, représentant la valeur médiane des logements pour les districts de Californie, exprimée en centaines de milliers de dollars ($100,000).
California Housing Dataset:
MedInc HouseAge AveRooms AveBedrms Population AveOccup Latitude Longitude MedHouseVal
0 8.3252 41.0 6.984127 1.023810 322.0 2.555556 37.88 -122.23 4.526
1 8.3014 21.0 6.238137 0.971880 2401.0 2.109842 37.86 -122.22 3.585
2 7.2574 52.0 8.288136 1.073446 496.0 2.802260 37.85 -122.24 3.521
3 5.6431 52.0 5.817352 1.073059 558.0 2.547945 37.85 -122.25 3.413
4 3.8462 52.0 6.281853 1.081081 565.0 2.181467 37.85 -122.25 3.422
Diviser les données en ensembles d'entraînement et de test avec train_test_split de sklearn.model_selection
Dans cette étape, nous préparerons nos données pour le processus d'entraînement. Une partie cruciale de l'apprentissage automatique consiste à évaluer le modèle sur des données qu'il n'a jamais vues auparavant. Pour ce faire, nous divisons notre jeu de données en deux parties : un ensemble d'entraînement et un ensemble de test. Le modèle apprendra à partir de l'ensemble d'entraînement, et nous utiliserons l'ensemble de test pour vérifier ses performances.
Tout d'abord, nous devons séparer nos caractéristiques (les variables d'entrée, X) de notre cible (la valeur que nous voulons prédire, y). Dans notre cas, X sera constitué de toutes les colonnes sauf MedHouseVal, et y sera la colonne MedHouseVal.
Ensuite, nous utiliserons la fonction train_test_split de sklearn.model_selection pour effectuer la division.
Ajoutez le code suivant à votre fichier main.py.
from sklearn.model_selection import train_test_split
## Prepare the data
X = california_df.drop('MedHouseVal', axis=1) ## Features (input variables)
y = california_df['MedHouseVal'] ## Target variable (what we want to predict)
## Split the data into training and testing sets
## test_size=0.2: Reserve 20% of data for testing, 80% for training
## random_state=42: Ensures reproducible splits (same result every run)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
## Print the shapes of the new datasets to confirm the split
print("\n--- Data Split ---")
print("X_train shape:", X_train.shape) ## Training features
print("X_test shape:", X_test.shape) ## Test features
print("y_train shape:", y_train.shape) ## Training target values
print("y_test shape:", y_test.shape) ## Test target values
Maintenant, exécutez à nouveau le script depuis le terminal :
python3 main.py
Vous verrez les formes (shapes) des ensembles d'entraînement et de test nouvellement créés s'afficher sous le DataFrame. Cela confirme que les données ont été divisées correctement.
--- Data Split ---
X_train shape: (16512, 8)
X_test shape: (4128, 8)
y_train shape: (16512,)
y_test shape: (4128,)
Initialiser le modèle LinearRegression de sklearn.linear_model
Dans cette étape, nous allons créer notre modèle de régression linéaire. scikit-learn rend cela incroyablement simple. Il suffit d'importer la classe LinearRegression du module sklearn.linear_model puis d'en créer une instance.
Cette instance est un objet qui contient l'algorithme de régression linéaire. La régression linéaire trouve la droite la mieux ajustée à travers les points de données, en utilisant la formule : y = mx + b, où m sont les coefficients (poids) pour chaque caractéristique, et b est l'ordonnée à l'origine (intercept). Ici, nous utilisons les paramètres par défaut qui fonctionnent bien pour la plupart des cas de base.
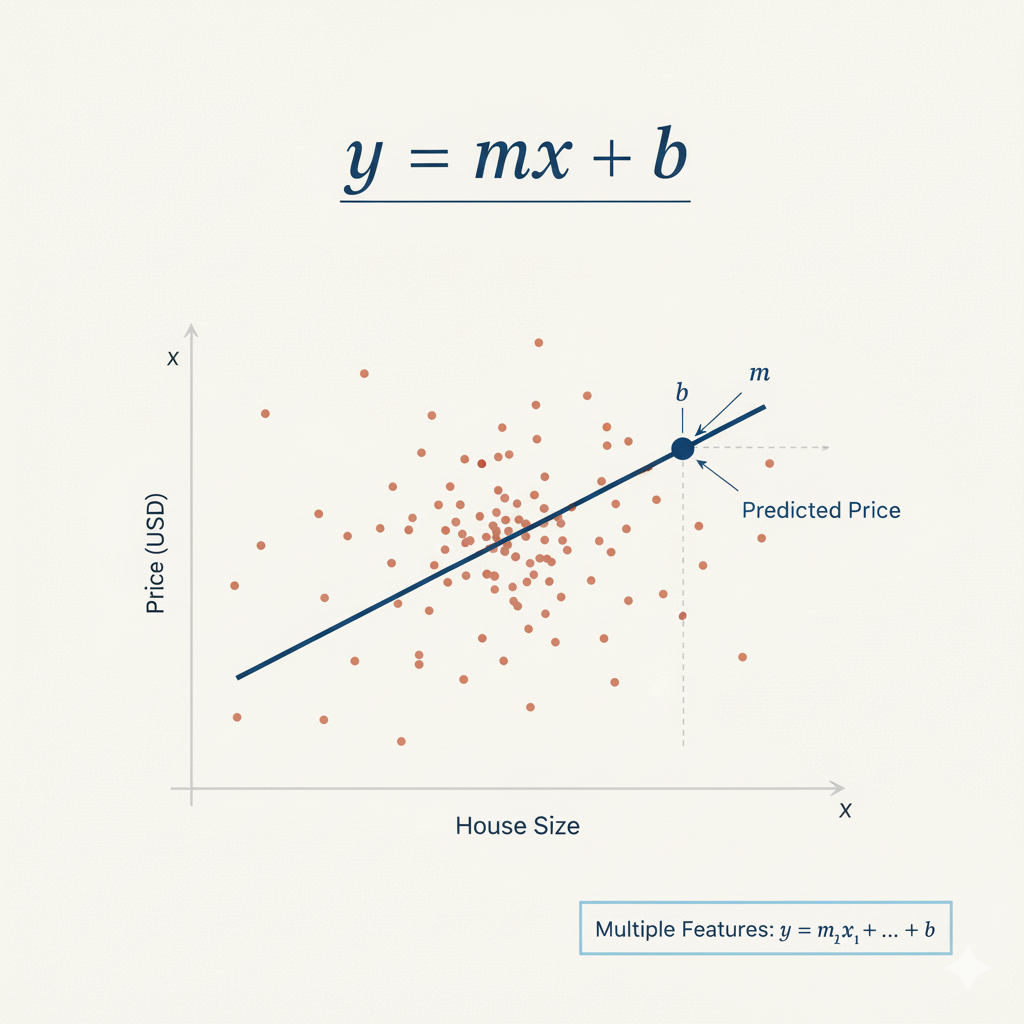 Figure 1 : Formule de régression linéaire y = mx + b, où m est la pente et b est l'ordonnée à l'origine
Figure 1 : Formule de régression linéaire y = mx + b, où m est la pente et b est l'ordonnée à l'origine
Ajoutez le code suivant à votre fichier main.py. Cela importera la classe LinearRegression et créera un objet modèle.
from sklearn.linear_model import LinearRegression
## Initialize the Linear Regression model
model = LinearRegression()
## Print the model to confirm it's created
print("\n--- Model Initialized ---")
print(model)
Exécutez à nouveau votre script main.py depuis le terminal :
python3 main.py
La sortie inclura désormais une ligne montrant l'objet LinearRegression. Cela confirme que le modèle a été initialisé avec succès.
--- Model Initialized ---
LinearRegression()
Ajuster le modèle avec model.fit(X_train, y_train)
Dans cette étape, nous allons entraîner notre modèle. Ce processus est souvent appelé "ajustement" (fitting) du modèle aux données. Pendant l'ajustement, le modèle apprend les relations entre les caractéristiques (X_train) et la variable cible (y_train). Pour la régression linéaire, cela signifie trouver les coefficients optimaux pour chaque caractéristique afin de prédire au mieux la cible.
Nous utiliserons la méthode fit() de notre objet modèle, en passant nos données d'entraînement comme arguments.
Ajoutez le code suivant à votre fichier main.py.
## Fit (train) the model on the training data
## The fit() method learns the relationship between features (X_train) and target (y_train)
## It calculates optimal coefficients for each feature and the intercept using least squares optimization
model.fit(X_train, y_train)
## After fitting, the model has learned the coefficients and intercept.
## The intercept represents the predicted value when all features are zero
print("\n--- Model Trained ---")
print("Intercept:", model.intercept_)
Maintenant, exécutez le script depuis le terminal :
python3 main.py
Une fois le script exécuté, vous verrez une nouvelle section dans la sortie affichant l'ordonnée à l'origine (intercept) du modèle de régression linéaire. L'intercept est la valeur de la prédiction lorsque toutes les valeurs des caractéristiques sont égales à zéro. Voir une valeur numérique ici confirme que le modèle a été entraîné avec succès sur les données.
--- Model Trained ---
Intercept: -37.023277706064185
Prédire sur les données de test avec model.predict(X_test)
Dans cette dernière étape, nous utiliserons notre modèle entraîné pour effectuer des prédictions. C'est l'objectif ultime de la construction d'un modèle prédictif. Nous utiliserons les données de test (X_test), que le modèle n'a pas vues pendant l'entraînement, pour évaluer ses performances.
Nous utiliserons la méthode predict() de notre objet modèle entraîné, en passant les caractéristiques de test (X_test) comme argument. La méthode renverra un tableau de valeurs prédites pour la variable cible.
Ajoutez le code suivant à votre fichier main.py.
## Make predictions on the test data
## The predict() method uses the learned coefficients and intercept to calculate predictions
## Formula: prediction = intercept + (coeff1 * feature1) + (coeff2 * feature2) + ...
predictions = model.predict(X_test)
## Print the first 5 predictions (values are in $100,000 units)
print("\n--- Predictions ---")
print(predictions[:5])
Maintenant, exécutez le script complet une dernière fois depuis le terminal :
python3 main.py
La sortie inclura désormais les cinq premiers prix de logement prédits pour l'ensemble de test. Ces valeurs sont ce que notre modèle estime être les prix médians des logements, basés sur les caractéristiques dans X_test. Vous pouvez comparer conceptuellement ces prédictions aux valeurs réelles dans y_test pour évaluer la précision du modèle.
--- Predictions ---
[0.71912284 1.76401657 2.70965883 2.83892593 2.60465725]
Félicitations ! Vous avez construit, entraîné et utilisé avec succès un modèle de régression linéaire avec scikit-learn.
Visualiser les prédictions du modèle avec matplotlib.pyplot.scatter()
Dans cette étape finale, nous allons créer une visualisation pour mieux comprendre les performances de notre modèle. La visualisation est cruciale en apprentissage automatique car elle nous aide à voir des modèles et des relations qui pourraient ne pas être évidents à partir de chiffres bruts.
Nous allons créer un nuage de points (scatter plot) qui compare les prix réels des logements (y_test) avec les prédictions de notre modèle. Ce type de graphique est appelé un graphique "prédictions vs réel". Si notre modèle était parfait, tous les points se trouveraient sur une ligne diagonale (ligne à 45 degrés) où les valeurs prédites sont égales aux valeurs réelles.
Nous utiliserons matplotlib pour créer cette visualisation et l'enregistrer sous forme de fichier image.
Ajoutez le code suivant à votre fichier main.py :
import matplotlib.pyplot as plt
## Create a scatter plot comparing actual vs predicted values
plt.figure(figsize=(10, 6))
plt.scatter(y_test, predictions, alpha=0.5, color='blue', edgecolors='black')
## Add a diagonal line showing perfect predictions (where predicted = actual)
plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()],
'r--', linewidth=2, label='Perfect Prediction')
## Add labels and title
plt.xlabel('Actual House Prices ($100,000)')
plt.ylabel('Predicted House Prices ($100,000)')
plt.title('Linear Regression: Actual vs Predicted House Prices')
plt.legend()
plt.grid(True, alpha=0.3)
## Save the plot to a file
plt.savefig('housing_predictions.png', dpi=300, bbox_inches='tight')
plt.close()
print("\n--- Visualization Complete ---")
print("Plot saved to housing_predictions.png")
Maintenant, exécutez le script complet depuis le terminal :
python3 main.py
Vous verrez un message de confirmation indiquant que le graphique a été enregistré.
--- Visualization Complete ---
Plot saved to housing_predictions.png
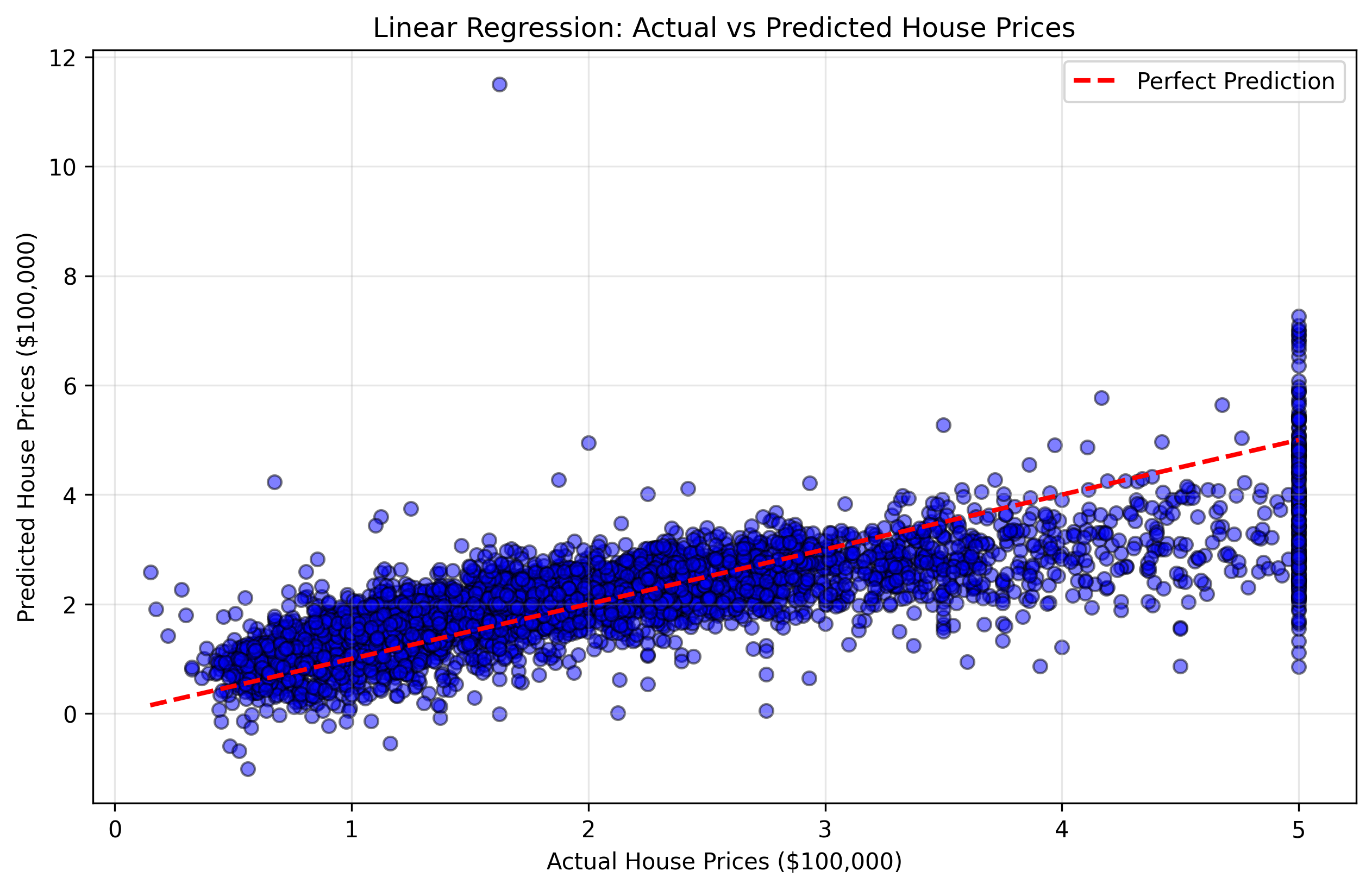 Figure 2 : Nuage de points montrant les prix réels vs prédits des logements. Les points plus proches de la ligne diagonale rouge indiquent de meilleures prédictions.
Figure 2 : Nuage de points montrant les prix réels vs prédits des logements. Les points plus proches de la ligne diagonale rouge indiquent de meilleures prédictions.
Cette visualisation vous aidera à comprendre :
- Points proches de la ligne diagonale : Bonnes prédictions où le modèle a été précis.
- Points éloignés de la ligne diagonale : Mauvaises prédictions où le modèle a commis des erreurs plus importantes.
- Modèle global : Si le modèle a tendance à surestimer ou sous-estimer certaines plages de prix.
Vous pouvez double-cliquer sur le fichier housing_predictions.png dans l'explorateur de fichiers pour visualiser votre graphique.
Félicitations ! Vous avez construit, entraîné, testé et visualisé avec succès un modèle de régression linéaire avec scikit-learn.
Résumé
Dans ce laboratoire, vous avez complété l'intégralité du flux de travail pour construire un modèle d'apprentissage automatique de base en utilisant scikit-learn.
Vous avez commencé par charger le jeu de données des logements en Californie et le préparer en utilisant pandas. Ensuite, vous avez appris l'importance de diviser vos données en ensembles d'entraînement et de test, et vous avez effectué cette division en utilisant train_test_split.
Par la suite, vous avez initialisé un modèle LinearRegression, l'avez entraîné sur vos données d'entraînement en utilisant la méthode fit(), utilisé le modèle entraîné pour effectuer des prédictions sur des données de test inédites avec la méthode predict(), et enfin visualisé les résultats pour comprendre les performances de votre modèle.
Ce laboratoire fournit une base solide en scikit-learn. À partir de là, vous pouvez explorer des sujets plus avancés tels que :
- Évaluation du modèle : Calculer des métriques comme l'erreur quadratique moyenne (MSE) ou le coefficient de détermination (R-squared) pour mesurer la précision du modèle.
- Visualisation des données : Créer des graphiques plus avancés comme des graphiques de résidus, des graphiques d'importance des caractéristiques ou des matrices de corrélation.
- Mise à l'échelle des caractéristiques (Feature scaling) : Standardiser ou normaliser les caractéristiques pour de meilleures performances.
- Régularisation : Utiliser la régression Ridge ou Lasso pour éviter le surapprentissage (overfitting).
- Validation croisée : Évaluation plus robuste utilisant la validation croisée k-fold.
- Autres algorithmes : Essayer les forêts aléatoires (Random Forest), les machines à vecteurs de support (SVM) ou les réseaux de neurones.


