
介绍
在 Hadoop 2.0 及之后的版本中,引入了 YARN 这一新的资源管理模式,它在集群利用率、统一资源管理和数据共享方面提供了便利。基于构建 Hadoop 伪分布式集群的基础,本节将让你学习 YARN 框架的架构、工作原理、配置、开发以及监控技术。
本实验需要一定的 Java 编程基础。
请尽量手动输入文档中的所有示例代码,而不是直接复制粘贴。这样可以让你更熟悉代码。如果遇到问题,请仔细查阅文档,或者你可以前往论坛寻求帮助和交流。
YARN 架构与组件
YARN 作为 MapReduce 2.0 (MRv2) 的一部分,在 Hadoop 0.23 中引入,彻底改变了 Hadoop 集群中的资源管理和作业调度方式:
- JobTracker 的分解:
MRv2将JobTracker的功能分解为独立的守护进程——ResourceManager负责资源管理,ApplicationMaster负责作业调度和监控。 - 全局 ResourceManager:每个应用程序都有一个对应的
ApplicationMaster,它可以是一个 MapReduce 作业,也可以是一个描述作业的 DAG(有向无环图)。 - 数据计算框架:
ResourceManager、Slave和NodeManager构成了一个框架,其中 ResourceManager 管理所有应用程序的资源。 - ResourceManager 组件:
Scheduler根据容量和队列等约束条件分配资源,而ApplicationsManager处理作业提交和 ApplicationMaster 的执行。 - 资源分配:资源需求通过资源容器定义,包含内存、CPU、磁盘和网络等元素。
- NodeManager 的角色:NodeManager 监控容器的资源使用情况,并向 ResourceManager 和 Scheduler 报告。
- ApplicationMaster 的任务:ApplicationMaster 与 Scheduler 协商资源容器,跟踪状态并监控进度。
下图展示了它们之间的关系:

YARN 确保了与之前版本的 API 兼容性,使得运行 MapReduce 任务能够无缝过渡。理解 YARN 的架构和组件对于在 Hadoop 集群中实现高效的资源管理和作业调度至关重要。
启动 Hadoop 守护进程
在学习相关配置参数和 YARN 应用开发技术之前,我们需要先启动 Hadoop 守护进程,以便随时使用。
首先双击桌面上的 Xfce 终端并输入以下命令切换到 hadoop 用户:
su - hadoop
提示:用户 'hadoop' 的密码是 'hadoop'。
切换完成后,你可以启动包括 HDFS 和 YARN 框架在内的 Hadoop 相关守护进程。
请在终端中输入以下命令来启动守护进程:
/home/hadoop/hadoop/sbin/start-dfs.sh
/home/hadoop/hadoop/sbin/start-yarn.sh
启动完成后,你可以选择使用 jps 命令检查相关守护进程是否正在运行。
hadoop:~$ jps
3378 NodeManager
3028 SecondaryNameNode
3717 Jps
2791 DataNode
2648 NameNode
3240 ResourceManager
准备配置文件
在本节中,我们将学习 yarn-site.xml,这是 Hadoop 的主要配置文件之一,了解在该文件中可以为 YARN 集群进行哪些设置。
为了防止误操作导致配置文件被修改,最好将 Hadoop 的配置文件复制到另一个目录中,然后再打开它。
为此,请在终端中输入以下命令,为配置文件创建一个新目录:
mkdir /home/hadoop/hadoop_conf
然后从安装目录中将 YARN 的主配置文件 yarn-site.xml 复制到新创建的目录中。
请在终端中输入以下命令以执行此操作:
cp /home/hadoop/hadoop/etc/hadoop/yarn-site.xml /home/hadoop/hadoop_conf/yarn-site.xml
接着使用 vim 编辑器打开文件以查看其内容:
vim /home/hadoop/hadoop_conf/yarn-site.xml
配置文件的工作原理
我们知道,YARN 框架中有两个重要角色:ResourceManager 和 NodeManager。因此,文件中的每个配置项都是针对上述两个组件的设置。
该文件中可以设置许多配置项,但默认情况下,此文件不包含任何自定义配置项。例如,我们现在打开的文件中仅包含之前在配置伪分布式 Hadoop 集群时指定的 aux-services 属性,如下图所示:
hadoop:~$ cat /home/hadoop/hadoop/etc/hadoop/mapred-site.xml
...
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
此配置项用于设置在 NodeManager 上需要运行的依赖服务。我们指定的配置值为 mapreduce_shuffle,表示需要在 YARN 上运行 MapReduce 程序的默认值。
文件中未写入的配置项是否不起作用?并非如此。当文件中未明确指定配置参数时,Hadoop 的 YARN 框架会读取存储在内部文件中的默认值。所有在 yarn-site.xml 文件中明确指定的配置项将覆盖默认值,这是 Hadoop 系统适应不同使用场景的有效方式。
ResourceManager 配置项
理解并正确配置 yarn-site.xml 文件中的 ResourceManager 设置对于 Hadoop 集群中的高效资源管理和作业执行至关重要。以下是与 ResourceManager 相关的关键配置项总结:
- **
yarn.resourcemanager.address**:向客户端暴露的地址,用于提交应用程序和终止应用程序。默认端口为 8032。 - **
yarn.resourcemanager.scheduler.address**:向 ApplicationMaster 暴露的地址,用于请求和释放资源。默认端口为 8030。 - **
yarn.resourcemanager.resource-tracker.address**:向 NodeManager 暴露的地址,用于发送心跳和拉取任务。默认端口为 8031。 - **
yarn.resourcemanager.admin.address**:向管理员暴露的地址,用于管理命令。默认端口为 8033。 - **
yarn.resourcemanager.webapp.address**:用于查看集群信息的 WebUI 地址。默认端口为 8088。 - **
yarn.resourcemanager.scheduler.class**:指定调度器的主类名(例如 FIFO、CapacityScheduler、FairScheduler)。 - 线程配置:
yarn.resourcemanager.resource-tracker.client.thread-countyarn.resourcemanager.scheduler.client.thread-count
- 资源分配:
yarn.scheduler.minimum-allocation-mbyarn.scheduler.maximum-allocation-mbyarn.scheduler.minimum-allocation-vcoresyarn.scheduler.maximum-allocation-vcores
- NodeManager 管理:
yarn.resourcemanager.nodes.exclude-pathyarn.resourcemanager.nodes.include-path
- 心跳配置:
yarn.resourcemanager.nodemanagers.heartbeat-interval-ms
配置这些参数可以微调 ResourceManager 的行为、资源分配、线程处理、NodeManager 管理以及 Hadoop 集群中的心跳间隔。理解这些配置项有助于防止问题并确保集群的平稳运行。
NodeManager 配置项
在 yarn-site.xml 文件中配置 NodeManager 设置对于在 Hadoop 集群中高效管理资源和任务至关重要。以下是与 NodeManager 相关的关键配置项总结:
- **
yarn.nodemanager.resource.memory-mb**:指定 NodeManager 可用的总物理内存。此值在 YARN 运行时保持不变。 - **
yarn.nodemanager.vmem-pmem-ratio**:设置虚拟内存与物理内存分配的比率。默认比率为2.1。 - **
yarn.nodemanager.resource.cpu-vcores**:定义 NodeManager 可用的虚拟 CPU 总数。默认值为8。 - **
yarn.nodemanager.local-dirs**:用于在 NodeManager 上存储中间结果的路径,允许配置多个目录。 - **
yarn.nodemanager.log-dirs**:NodeManager 日志目录的路径,支持配置多个目录。 - **
yarn.nodemanager.log.retain-seconds**:NodeManager 日志的最大保留时间,默认为 10800 秒(3 小时)。
配置这些参数可以微调资源分配、内存管理、目录路径和日志保留设置,以实现 NodeManager 在 Hadoop 集群中的最佳性能和资源利用率。理解这些配置项有助于确保集群的平稳运行和任务的高效执行。
配置项查询与默认参考
要探索 YARN 和其他常见 Hadoop 组件中可用的所有配置项,可以参考 Apache Hadoop 提供的默认配置文件。以下是访问默认配置的链接:
YARN 配置项:
常见配置文件:
- core-default.xml (core-site.xml)
- hdfs-default.xml (hdfs-site.xml)
- mapred-default.xml (mapred-site.xml)
探索这些默认配置提供了每个配置项的详细描述及其用途,帮助你理解每个参数在 Hadoop 架构设计中的作用。
查看配置后,你可以关闭 vim 编辑器,结束对 Hadoop 配置设置的探索。
创建项目目录和文件
让我们通过模仿一个官方的 YARN 实例应用来学习 YARN 应用的开发过程。
首先创建一个项目目录。请在终端中输入以下命令以执行目录创建:
mkdir /home/hadoop/yarn_app
然后在项目中分别创建两个源代码文件。
第一个是 Client.java。请在终端中使用 touch 命令创建该文件:
touch /home/hadoop/yarn_app/Client.java
接着创建 ApplicationMaster.java 文件:
touch /home/hadoop/yarn_app/ApplicationMaster.java
hadoop:~$ tree /home/hadoop/yarn_app/
/home/hadoop/yarn_app/
├── ApplicationMaster.java
└── Client.java
0 directories, 2 files
编写客户端代码
通过编写 Client 的代码,你将能够理解在 YARN 框架下开发 Client 所需的 API 及其作用。
代码内容较长。比起逐行阅读,更高效的方式是将其逐行输入到你刚刚创建的源代码文件中。
首先使用 vim 编辑器(或其他文本编辑器)打开刚刚创建的 Client.java 文件:
vim /home/hadoop/yarn_app/Client.java
然后添加程序的主体部分,指明类名和类的包名:
package com.labex.yarn.app;
public class Client {
public static void main(String[] args){
//TODO: 在此编辑代码。
}
}
以下代码以分段形式呈现。编写时,请将以下代码写入 Client 类中(即注释 //TODO: 在此编辑代码 所在的代码块)。
客户端的第一步是创建并初始化 YarnClient 对象,然后启动它:
YarnClient yarnClient = YarnClient.createYarnClient();
yarnClient.init(conf);
yarnClient.start();
创建 Client 后,我们需要创建 YARN 应用程序的对象及其应用程序 ID:
YarnClientApplication app = yarnClient.createApplication();
GetNewApplicationResponse appResponse = app.getNewApplicationResponse();
appResponse 对象包含集群的信息,例如集群的最小和最大资源能力。这些信息是确保在 ApplicationMaster 启动相关容器时能够正确设置参数所必需的。
Client 的主要任务之一是设置 ApplicationSubmissionContext。它定义了 RM 启动 AM 所需的所有信息。
通常,Client 需要在上下文中设置以下内容:
- 应用程序信息:包括应用程序的 ID 和名称。
- 队列和优先级信息:包括应用程序提交的队列和分配的优先级。
- 用户:提交应用程序的用户。
- ContainerLaunchContext:定义启动和运行 AM 的容器的信息。运行应用程序所需的所有必要信息都在
ContainerLaunchContext中定义,包括本地资源(二进制文件、jar 文件等)、环境变量(如CLASSPATH)、要执行的命令和安全令牌(RECT):
// 设置应用程序提交上下文
ApplicationSubmissionContext appContext = app.getApplicationSubmissionContext();
ApplicationId appId = appContext.getApplicationId();
appContext.setKeepContainersAcrossApplicationAttempts(keepContainers);
appContext.setApplicationName(appName);
// 以下代码用于设置 ApplicationMaster 的本地资源
// 本地资源需要是本地文件或压缩包等。
// 在此场景中,jar 包以文件形式作为 AM 的本地资源之一。
Map<String, LocalResource> localResources = new HashMap<String, LocalResource>();
LOG.info("从本地文件系统复制 AppMaster jar 并添加到本地环境。");
// 将 ApplicationMaster 的 jar 包复制到文件系统中
FileSystem fs = FileSystem.get(conf);
// 创建一个指向 jar 包路径的本地资源
addToLocalResources(fs, appMasterJar, appMasterJarPath, appId.toString(), localResources, null);
// 设置日志参数,可以跳过
if (!log4jPropFile.isEmpty()) {
addToLocalResources(fs, log4jPropFile, log4jPath, appId.toString(), localResources, null);
}
// shell 脚本将在最终执行它的容器中可用
// 因此首先将其复制到文件系统中,以便 YARN 框架可以找到它
// 这里不需要将其设置为 AM 的本地资源,因为后者不需要它
String hdfsShellScriptLocation = "";
long hdfsShellScriptLen = 0;
long hdfsShellScriptTimestamp = 0;
if (!shellScriptPath.isEmpty()) {
Path shellSrc = new Path(shellScriptPath);
String shellPathSuffix = appName + "/" + appId.toString() + "/" + SCRIPT_PATH;
Path shellDst = new Path(fs.getHomeDirectory(), shellPathSuffix);
fs.copyFromLocalFile(false, true, shellSrc, shellDst);
hdfsShellScriptLocation = shellDst.toUri().toString();
FileStatus shellFileStatus = fs.getFileStatus(shellDst);
hdfsShellScriptLen = shellFileStatus.getLen();
hdfsShellScriptTimestamp = shellFileStatus.getModificationTime();
}
if (!shellCommand.isEmpty()) {
addToLocalResources(fs, null, shellCommandPath, appId.toString(),
localResources, shellCommand);
}
if (shellArgs.length > 0) {
addToLocalResources(fs, null, shellArgsPath, appId.toString(),
localResources, StringUtils.join(shellArgs, " "));
}
// 设置 AM 所需的环境参数
LOG.info("为应用程序主节点设置环境");
Map<String, String> env = new HashMap<String, String>();
// 将 shell 脚本的路径添加到环境变量中
// AM 将相应地创建最终容器的正确本地资源
// 上述容器将在启动时执行 shell 脚本
env.put(DSConstants.DISTRIBUTEDSHELLSCRIPTLOCATION, hdfsShellScriptLocation);
env.put(DSConstants.DISTRIBUTEDSHELLSCRIPTTIMESTAMP, Long.toString(hdfsShellScriptTimestamp));
env.put(DSConstants.DISTRIBUTEDSHELLSCRIPTLEN, Long.toString(hdfsShellScriptLen));
// 将 AppMaster.jar 的路径添加到类路径中
// 注意,这里不需要提供 Hadoop 相关的类路径,因为我们在外部配置文件中有一个注解。
// 以下代码将所有 AM 所需的类路径相关路径设置添加到当前目录
StringBuilder classPathEnv = new StringBuilder(Environment.CLASSPATH.$$())
.append(ApplicationConstants.CLASS_PATH_SEPARATOR).append("./*");
for (String c : conf.getStrings(
YarnConfiguration.YARN_APPLICATION_CLASSPATH,
YarnConfiguration.DEFAULT_YARN_CROSS_PLATFORM_APPLICATION_CLASSPATH)) {
classPathEnv.append(ApplicationConstants.CLASS_PATH_SEPARATOR);
classPathEnv.append(c.trim());
}
classPathEnv.append(ApplicationConstants.CLASS_PATH_SEPARATOR).append(
"./log4j.properties");
// 设置执行 AM 的命令
Vector<CharSequence> vargs = new Vector<CharSequence>(30);
// 设置 Java 的可执行命令
LOG.info("设置应用程序主节点命令");
vargs.add(Environment.JAVA_HOME.$$() + "/bin/java");
// 设置 JVM 下 Xmx 参数分配的内存大小
vargs.add("-Xmx" + amMemory + "m");
// 设置类名
vargs.add(appMasterMainClass);
// 设置 ApplicationMaster 的参数
vargs.add("--container_memory " + String.valueOf(containerMemory));
vargs.add("--container_vcores " + String.valueOf(containerVirtualCores));
vargs.add("--num_containers " + String.valueOf(numContainers));
vargs.add("--priority " + String.valueOf(shellCmdPriority));
for (Map.Entry<String, String> entry : shellEnv.entrySet()) {
vargs.add("--shell_env " + entry.getKey() + "=" + entry.getValue());
}
if (debugFlag) {
vargs.add("--debug");
}
vargs.add("1>" + ApplicationConstants.LOG_DIR_EXPANSION_VAR + "/AppMaster.stdout");
vargs.add("2>" + ApplicationConstants.LOG_DIR_EXPANSION_VAR + "/AppMaster.stderr");
// 生成最终参数并配置
StringBuilder command = new StringBuilder();
for (CharSequence str : vargs) {
command.append(str).append(" ");
}
LOG.info("完成设置应用程序主节点命令 " + command.toString());
List<String> commands = new ArrayList<String>();
commands.add(command.toString());
// 设置 AM 启动上下文的容器
ContainerLaunchContext amContainer = ContainerLaunchContext.newInstance(
localResources, env, commands, null, null, null);
// 设置资源类型的要求,包括内存和虚拟 CPU 核心。
Resource capability = Resource.newInstance(amMemory, amVCores);
appContext.setResource(capability);
// 如果需要,YARN 服务的数据以二进制格式传递给应用程序。但在此示例中不需要。
// amContainer.setServiceData(serviceData);
// 设置令牌
if (UserGroupInformation.isSecurityEnabled()) {
Credentials credentials = new Credentials();
String tokenRenewer = conf.get(YarnConfiguration.RM_PRINCIPAL);
if (tokenRenewer == null || tokenRenewer.length() == 0) {
throw new IOException(
"无法获取 RM 的主 Kerberos 主体以用作续订者");
}
// 获取默认文件系统的令牌
final Token<?> tokens[] =
fs.addDelegationTokens(tokenRenewer, credentials);
if (tokens != null) {
for (Token<?> token : tokens) {
LOG.info("获取 dt 为 " + fs.getUri() + "; " + token);
}
}
DataOutputBuffer dob = new DataOutputBuffer();
credentials.writeTokenStorageToStream(dob);
ByteBuffer fsTokens = ByteBuffer.wrap(dob.getData(), 0, dob.getLength());
amContainer.setTokens(fsTokens);
}
appContext.setAMContainerSpec(amContainer);
设置过程完成后,客户端可以提交具有指定优先级和队列的应用程序:
/ / 设置 AM 的优先级
Priority pri = Priority.newInstance(amPriority);
appContext.setPriority(pri);
// 设置应用程序提交到 RM 的队列
appContext.setQueue(amQueue);
// 将应用程序提交到 AM
yarnClient.submitApplication(appContext);
此时,RM 将接受应用程序并在后台在分配的容器上设置并启动 AM。
客户端可以通过多种方式跟踪实际任务的进度。
(1) 其中一种方式是通过 YarnClient 对象的 getApplicationReport() 方法与 RM 通信并请求应用程序报告:
// 使用应用程序 ID 获取其报告
ApplicationReport report = yarnClient.getApplicationReport(appId);
从 RM 收到的报告包括以下内容:
- 一般信息:包括应用程序的编号(位置)、提交应用程序的队列、提交应用程序的用户以及应用程序的启动时间。
- ApplicationMaster 详细信息:运行 AM 的主机、监听 Client 请求的 RPC 端口以及 Client 和 AM 通信所需的令牌。
- 应用程序跟踪信息:如果应用程序支持某种形式的进度跟踪,它可以通过应用程序报告的
getTrackingUrl()方法设置跟踪 URL,客户端可以通过此方法监控进度。 - 应用程序状态:你可以在
getYarnApplicationState中查看ResourceManager的应用程序状态。如果YarnApplicationState设置为complete,客户端应参考getFinalApplicationStatus检查应用程序的任务是否实际执行成功。如果失败,可以通过getDiagnostics获取更多失败信息。
(2) 如果 ApplicationMaster 支持,Client 可以直接通过从应用程序报告中获取的 hostname:rpcport 信息查询 AM 本身的进度。
在某些情况下,如果应用程序运行时间过长,客户端可能希望终止应用程序。YarnClient 支持调用 killApplication。它允许客户端通过 ResourceManager 向 AM 发送终止信号。如果设计如此,应用程序管理器也可以通过其 RPC 层支持终止调用,客户端可以利用这一点。
具体代码如下,但代码仅供参考,无需写入 Client.java:
yarnClient.killApplication(appId);
编辑完上述内容后,保存内容并退出 vim 编辑器。
编写 ApplicationMaster 代码
同样地,使用 vim 编辑器打开 ApplicationMaster.java 文件以编写代码:
vim /home/hadoop/yarn_app/ApplicationMaster.java
package com.labex.yarn.app;
public class ApplicationMaster {
public static void main(String[] args){
//TODO: 在此编辑代码。
}
}
代码解释仍以分段形式呈现。以下提到的所有代码都应写入 ApplicationMaster 类中(即注释 //TODO: 在此编辑代码。 所在的代码块)。
AM 是 任务 的实际所有者,它由 RM 启动,并通过 Client 提供所有必要的信息和资源来监督和完成任务。
由于 AM 是在单个容器中启动的,因此该容器可能与其他容器共享同一物理主机。鉴于云计算平台的多租户特性及其他问题,可能无法预先知道要监听的端口。
因此,当 AM 启动时,可以通过环境传递几个参数。这些参数包括 AM 容器的 ContainerId、应用程序的提交时间以及运行 AM 的 NodeManager 主机的详细信息。
所有与 RM 的交互都需要应用程序进行调度。如果此过程失败,每个应用程序可能会重试。你可以从 AM 的容器 ID 中获取 ApplicationAttemptId。有相关的 API 可以将从环境中获取的值转换为对象。
编写以下代码:
Map<String, String> envs = System.getenv();
String containerIdString = envs.get(ApplicationConstants.AM_CONTAINER_ID_ENV);
If (containerIdString == null) {
// 容器 ID 应在框架的环境变量中设置
Throw new IllegalArgumentException(
"容器 ID 未在环境中设置");
}
ContainerId containerId = ConverterUtils.toContainerId(containerIdString);
ApplicationAttemptId appAttemptID = containerId.getApplicationAttemptId();
在 AM 完全初始化后,我们可以启动两个客户端:一个连接到 ResourceManager,另一个连接到 NodeManager。我们使用自定义事件处理程序来设置它,具体细节稍后讨论:
AMRMClientAsync.CallbackHandler allocListener = new RMCallbackHandler();
amRMClient = AMRMClientAsync.createAMRMClientAsync(1000, allocListener);
amRMClient.init(conf);
amRMClient.start();
containerListener = createNMCallbackHandler();
nmClientAsync = new NMClientAsyncImpl(containerListener);
nmClientAsync.init(conf);
nmClientAsync.start();
AM 必须定期向 RM 发送心跳,以便后者知道 AM 仍在运行。RM 上的过期间隔由 YarnConfiguration 定义,其默认值由配置文件中的 YarnConfiguration.RM_AM_EXPIRY_INTERVAL_MS 配置项定义。AM 需要在 ResourceManager 中注册自己以开始发送心跳:
// 向 RM 注册自己并开始向 RM 发送心跳
appMasterHostname = NetUtils.getHostname();
RegisterApplicationMasterResponse response = amRMClient.registerApplicationMaster(appMasterHostname, appMasterRpcPort, appMasterTrackingUrl);
注册过程的响应信息可能包括集群的最大资源容量。我们可以使用此信息来检查应用程序的请求:
// 临时保存 RM 中集群资源容量的信息
int maxMem = response.getMaximumResourceCapability().getMemory();
LOG.info("集群中资源的最大内存容量 " + maxMem);
int maxVCores = response.getMaximumResourceCapability().getVirtualCores();
LOG.info("集群中资源的最大虚拟核心容量 " + maxVCores);
// 使用最大内存限制来约束容器的内存容量请求值
if (containerMemory > maxMem) {
LOG.info("容器内存指定值超过集群的最大阈值。"
+ " 使用最大值。" + ", 指定值=" + containerMemory + ", 最大值="
+ maxMem);
containerMemory = maxMem;
}
if (containerVirtualCores > maxVCores) {
LOG.info("容器虚拟核心指定值超过集群的最大阈值。"
+ " 使用最大值。" + ", 指定值=" + containerVirtualCores + ", 最大值="
+ maxVCores);
containerVirtualCores = maxVCores;
}
List<Container> previousAMRunningContainers =
response.getContainersFromPreviousAttempts();
LOG.info("在 AM 注册时收到 " + previousAMRunningContainers.size()
+ " 个之前 AM 的运行容器。");
根据任务需求,AM 可以调度一组容器来运行任务。我们使用这些需求来计算需要多少个容器,并请求相应数量的容器:
int numTotalContainersToRequest = numTotalContainers - previousAMRunningContainers.size();
for (int i = 0; i < numTotalContainersToRequest; ++i) {
// 将请求对象设置为 RM 请求容器
ContainerRequest containerAsk = setupContainerAskForRM();
// 向 RM 发送容器请求
amRMClient.addContainerRequest(containerAsk);
// 此循环意味着在获得完全分配的配额后轮询 RM 以获取容器
}
上述循环将持续运行,直到所有容器都已启动并且 shell 脚本已执行(无论成功还是失败)。
在 setupContainerAskForRM() 中,你需要设置以下内容:
- 资源容量:目前,YARN 支持基于内存的资源需求,因此请求应定义需要多少内存。此值以兆字节为单位定义,并且必须小于集群最大和最小容量的确切倍数。此内存资源对应于任务容器上施加的物理内存限制。资源容量还包括基于计算的资源(vCore)。
- 优先级:当请求容器集时,AM 可以为集合定义不同的优先级。例如,MapReduce AM 可以为 Map 任务 所需的容器分配更高的优先级,而 Reduce 任务 容器的优先级较低:
Private ContainerRequest setupContainerAskForRM() {
/ / 设置请求的优先级
Priority pri = Priority.newInstance(requestPriority);
/ / 设置资源类型的请求,包括内存和 CPU
Resource capability = Resource.newInstance(containerMemory,
containerVirtualCores);
ContainerRequest request = new ContainerRequest(capability, null, null, pri);
LOG.info("请求的容器分配:" + request.toString());
Return request;
}
在 AM 发送容器分配请求后,容器由 AMRMClientAsync 客户端的事件处理程序异步启动。处理此逻辑的程序应实现 AMRMClientAsync.CallbackHandler 接口。
(1) 当分配到容器时,处理程序需要启动一个线程。该线程运行相关代码以启动容器。这里我们使用 LaunchContainerRunnable 进行演示。我们稍后将讨论此类:
@Override
public void onContainersAllocated(List<Container> allocatedContainers) {
LOG.info("从 RM 获取容器分配的响应,分配数量=" + allocatedContainers.size());
numAllocatedContainers.addAndGet(allocatedContainers.size());
for (Container allocatedContainer : allocatedContainers) {
LaunchContainerRunnable runnableLaunchContainer =
new LaunchContainerRunnable(allocatedContainer, containerListener);
Thread launchThread = new Thread(runnableLaunchContainer);
// 使用不同的线程启动和运行容器,这可以防止主线程在所有容器无法分配资源时阻塞
launchThreads.add(launchThread);
launchThread.start();
}
}
(2) 当发送心跳时,事件处理程序应报告应用程序的进度:
@Override
public float getProgress() {
// 设置进度信息并在下次发送心跳时报告给 RM
float progress = (float) numCompletedContainers.get() / numTotalContainers;
Return progress;
}
容器的启动线程实际上在 NM 上启动容器。在将容器分配给 AM 后,它需要遵循与 Client 设置 ContainerLaunchContext 类似的过程,以便在分配的容器上运行最终任务。在定义 ContainerLaunchContext 后,AM 可以通过 NMClientAsync 启动它:
// 设置在分配的容器上执行的必要命令
Vector<CharSequence> vargs = new Vector<CharSequence>(5);
// 设置可执行命令
vargs.add(shellCommand);
// 设置 shell 脚本的路径
if (!scriptPath.isEmpty()) {
vargs.add(Shell.WINDOWS ? ExecBatScripStringtPath
: ExecShellStringPath);
}
// 设置 shell 命令的参数
vargs.add(shellArgs);
// 添加日志重定向参数
vargs.add("1>" + ApplicationConstants.LOG_DIR_EXPANSION_VAR + "/stdout");
vargs.add("2>" + ApplicationConstants.LOG_DIR_EXPANSION_VAR + "/stderr");
// 获取最终命令
StringBuilder command = new StringBuilder();
for (CharSequence str : vargs) {
command.append(str).append(" ");
}
List<String> commands = new ArrayList<String>();
commands.add(command.toString());
// 设置 ContainerLaunchContext 以设置本地资源、环境变量、命令和令牌。
ContainerLaunchContext ctx = ContainerLaunchContext.newInstance(
localResources, shellEnv, commands, null, allTokens.duplicate(), null);
containerListener.addContainer(container.getId(), container);
nmClientAsync.startContainerAsync(container, ctx);
NMClientAsync 对象及其事件处理程序负责处理容器事件。它包括容器的启动、停止、状态更新和错误。
在 ApplicationMaster 确定任务完成后,它需要向 AM-RM 的 Client 注销,然后停止 Client:
try {
amRMClient.unregisterApplicationMaster(appStatus, appMessage, null);
} catch (YarnException ex) {
LOG.error("注销应用程序失败", ex);
} catch (IOException e) {
LOG.error("注销应用程序失败", e);
}
amRMClient.stop();
以上内容是 ApplicationMaster 的主要代码。编辑完成后,保存内容并退出 vim 编辑器。
应用程序启动流程
在 Hadoop 集群上启动应用程序的过程如下:
编译并启动应用程序
完成上一节的代码后,你可以使用 Maven 或 Gradle 等构建工具将其编译为 Jar 包并提交到 Hadoop 集群。
由于编译过程需要联网拉取相关依赖,因此耗时较长(大约 1 小时的高峰期)。因此,这里跳过编译过程,直接使用 Hadoop 安装目录中已编译的 Jar 包进行后续实验。
在此步骤中,我们使用简单的示例 jar 来运行 yarn 应用程序,而不是通过 maven 构建指定的 jar。
请在终端中使用 yarn jar 命令提交执行。以下命令涉及的参数包括要运行的 Jar 包路径、主类名称、提交到 YARN 框架的 Jar 包路径、要执行的 shell 命令数量以及容器数量:
/home/hadoop/hadoop/bin/yarn jar /home/hadoop/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar pi 3 3
查看终端中的输出,你可以看到应用程序执行的进度。
Pi 的估计值为 3.55555555555555555556
在任务执行期间,你可以从终端的输出中看到每个阶段的提示,例如 初始化 Client、连接到 RM 和 获取集群信息。
查看应用程序执行结果
双击打开桌面上的 Firefox 浏览器,并在地址栏中输入以下 URL 以查看 Hadoop 集群 YARN 模式下节点的资源信息:
http://localhost:8088
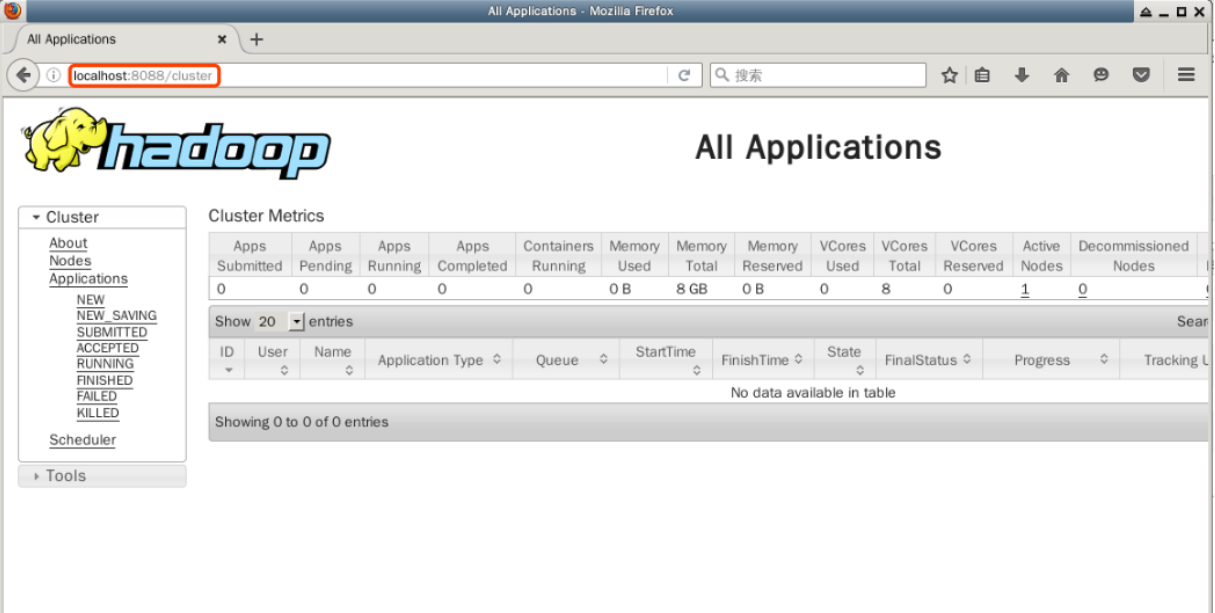
在此页面中,显示了有关 Hadoop 集群的所有信息,包括节点、应用程序和调度器的状态。
其中最重要的是应用程序的管理,我们稍后可以在此处查看提交的应用程序的执行状态。请暂时不要关闭 Firefox 浏览器。
总结
在完成 Hadoop 伪分布式集群的基础上,本实验继续向我们讲解了 YARN 框架的架构、工作原理、配置以及开发和监控技术。课程中提供了大量代码和配置文件,请仔细阅读。


