Introduction
In Python, snake case is a naming convention where words are separated by underscores. This naming style is commonly used for variables, functions, and other identifiers in Python. For example, calculate_total_price and user_authentication are in snake case format.
Sometimes, we may encounter strings that are in different formats like camelCase, PascalCase, or even strings with spaces and hyphens. In such situations, we need to convert these strings to snake case for consistency in our code.
In this lab, you will learn how to write a Python function that converts strings from various formats to snake case.
Understanding the Problem
Before we write our snake case conversion function, let's understand what we need to accomplish:
- We need to convert a string from any format to snake case
- Snake case means all lowercase letters with underscores between words
- We need to handle different input formats:
- camelCase (e.g.,
camelCase→camel_case) - Strings with spaces (e.g.,
some text→some_text) - Strings with mixed formatting (e.g., hyphens, underscores, and mixed case)
- camelCase (e.g.,
Let's start by creating a new Python file for our snake case function. In the WebIDE, navigate to the project directory and create a new file called snake_case.py:
## This function will convert a string to snake case
def snake(s):
## We'll implement this function step by step
pass ## Placeholder for now
## Test with a simple example
if __name__ == "__main__":
test_string = "helloWorld"
result = snake(test_string)
print(f"Original: {test_string}")
print(f"Snake case: {result}")
Save this file. In the next step, we'll start implementing the function.
For now, let's run our placeholder function to make sure our file is set up correctly. Open a terminal and run:
python3 ~/project/snake_case.py
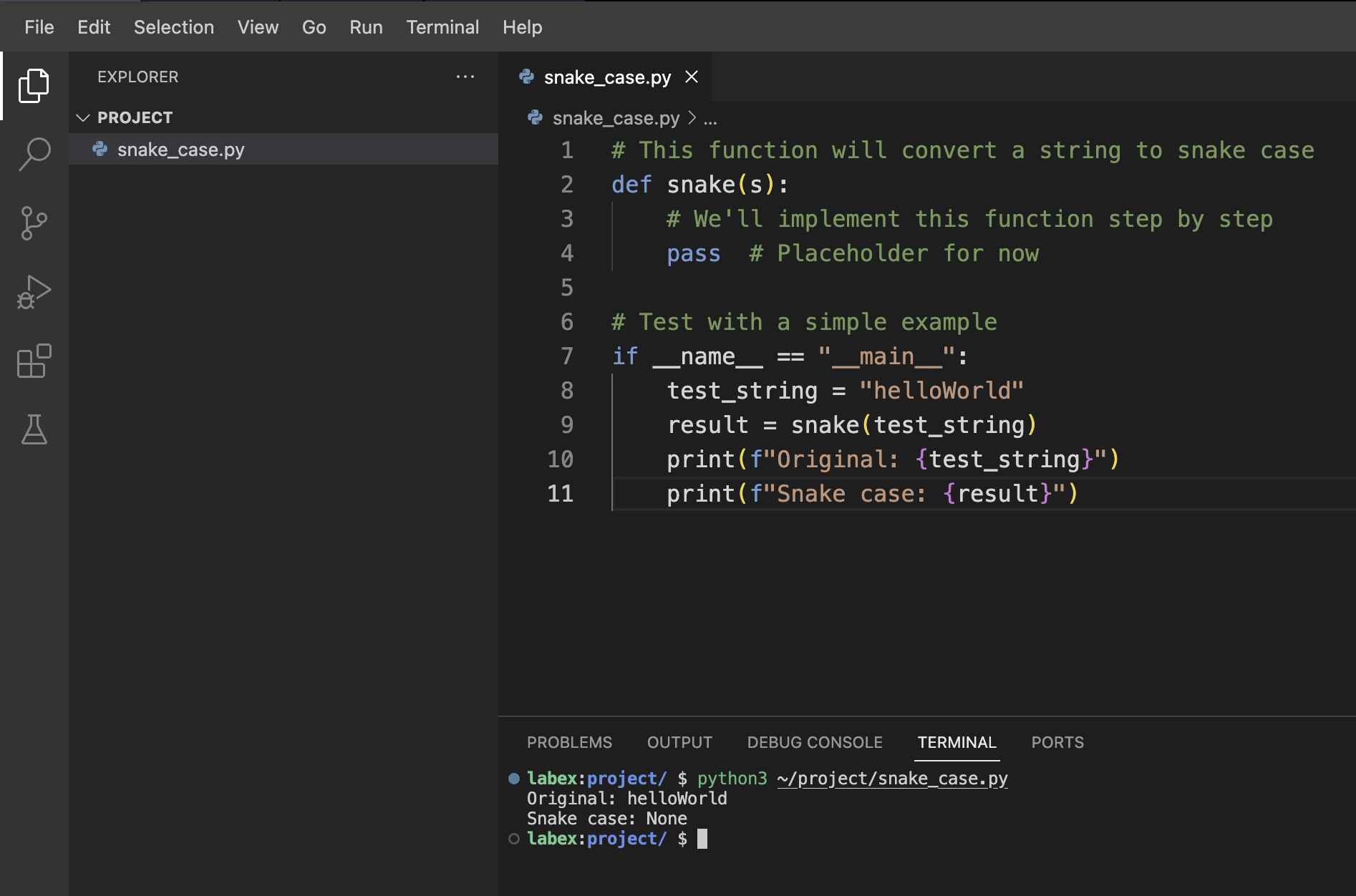
You should see an output like:
Original: helloWorld
Snake case: None
The result is None because our function is currently just returning the default Python None value. In the next step, we'll add the actual conversion logic.
Using Regular Expressions for Pattern Matching
To convert strings to snake case, we'll use regular expressions (regex) to identify word boundaries. The re module in Python provides powerful pattern matching capabilities that we can use for this task.
Let's update our function to handle camelCase strings:
- First, we need to identify the pattern where a lowercase letter is followed by an uppercase letter (like in "camelCase")
- Then, we'll insert a space between them
- Finally, we'll convert everything to lowercase and replace spaces with underscores
Update your snake_case.py file with this improved function:
import re
def snake(s):
## Replace pattern of a lowercase letter followed by uppercase with lowercase, space, uppercase
s1 = re.sub('([a-z])([A-Z])', r'\1 \2', s)
## Replace spaces with underscores and convert to lowercase
return s1.lower().replace(' ', '_')
## Test with a simple example
if __name__ == "__main__":
test_string = "helloWorld"
result = snake(test_string)
print(f"Original: {test_string}")
print(f"Snake case: {result}")
Let's break down what this function does:
re.sub('([a-z])([A-Z])', r'\1 \2', s)looks for patterns where a lowercase letter([a-z])is followed by an uppercase letter([A-Z]). It then replaces this pattern with the same letters but adds a space between them using\1and\2which refer to the captured groups.- Then we convert everything to lowercase with
lower()and replace spaces with underscores.
Run your script again to see if it works for camelCase:
python3 ~/project/snake_case.py
The output should now be:
Original: helloWorld
Snake case: hello_world
Great! Our function can now handle camelCase strings. In the next step, we'll enhance it to handle more complex cases.
Handling More Complex Patterns
Our current function works for camelCase, but we need to enhance it to handle additional patterns like:
- PascalCase (e.g.,
HelloWorld) - Strings with hyphens (e.g.,
hello-world) - Strings that already have underscores (e.g.,
hello_world)
Let's update our function to handle these cases:
import re
def snake(s):
## Replace hyphens with spaces
s = s.replace('-', ' ')
## Handle PascalCase pattern (sequences of uppercase letters)
s = re.sub('([A-Z]+)', r' \1', s)
## Handle camelCase pattern (lowercase followed by uppercase)
s = re.sub('([a-z])([A-Z])', r'\1 \2', s)
## Split by spaces, join with underscores, and convert to lowercase
return '_'.join(s.split()).lower()
## Test with multiple examples
if __name__ == "__main__":
test_strings = [
"helloWorld",
"HelloWorld",
"hello-world",
"hello_world",
"some text"
]
for test in test_strings:
result = snake(test)
print(f"Original: {test}")
print(f"Snake case: {result}")
print("-" * 20)
The enhancements we made:
- First, we replace any hyphens with spaces.
- The new regex
re.sub('([A-Z]+)', r' \1', s)adds a space before any sequence of uppercase letters, which helps with PascalCase. - We keep our camelCase handling regex.
- Finally, we split the string by spaces, join with underscores, and convert to lowercase, which handles any remaining spaces and ensures consistent output.
Run your script to test with various input formats:
python3 ~/project/snake_case.py
You should see output like:
Original: helloWorld
Snake case: hello_world
--------------------
Original: HelloWorld
Snake case: hello_world
--------------------
Original: hello-world
Snake case: hello_world
--------------------
Original: hello_world
Snake case: hello_world
--------------------
Original: some text
Snake case: some_text
--------------------
Our function is now more robust and can handle various input formats. In the next step, we'll make our final refinements and test against the full test suite.
Final Implementation and Testing
Now let's complete our implementation to handle all the required cases and verify that it passes all the test cases.
Update your snake_case.py file with the final implementation:
import re
def snake(s):
## Replace hyphens with spaces
s = s.replace('-', ' ')
## Handle PascalCase pattern
s = re.sub('([A-Z][a-z]+)', r' \1', s)
## Handle sequences of uppercase letters
s = re.sub('([A-Z]+)', r' \1', s)
## Split by whitespace and join with underscores
return '_'.join(s.split()).lower()
## Test with a complex example
if __name__ == "__main__":
test_string = "some-mixed_string With spaces_underscores-and-hyphens"
result = snake(test_string)
print(f"Original: {test_string}")
print(f"Snake case: {result}")
This final implementation:
- Replaces hyphens with spaces
- Adds a space before patterns like "Word" with
re.sub('([A-Z][a-z]+)', r' \1', s) - Adds a space before sequences of uppercase letters with
re.sub('([A-Z]+)', r' \1', s) - Splits by spaces, joins with underscores, and converts to lowercase
Now let's run our function against the test suite that was created in the setup step:
python3 ~/project/test_snake.py
If your implementation is correct, you should see:
All tests passed! Your snake case function works correctly.
Congratulations! You've successfully implemented a robust snake case conversion function that can handle various input formats.
Let's make sure our function accurately follows the specification by testing it with the examples from the original problem:
## Add this to the end of your snake_case.py file:
if __name__ == "__main__":
examples = [
'camelCase',
'some text',
'some-mixed_string With spaces_underscores-and-hyphens',
'AllThe-small Things'
]
for ex in examples:
result = snake(ex)
print(f"Original: {ex}")
print(f"Snake case: {result}")
print("-" * 20)
Run your updated script:
python3 ~/project/snake_case.py
You should see that all examples are correctly converted to snake case:
Original: some-mixed_string With spaces_underscores-and-hyphens
Snake case: some_mixed_string_with_spaces_underscores_and_hyphens
Original: camelCase
Snake case: camel_case
--------------------
Original: some text
Snake case: some_text
--------------------
Original: some-mixed_string With spaces_underscores-and-hyphens
Snake case: some_mixed_string_with_spaces_underscores_and_hyphens
--------------------
Original: AllThe-small Things
Snake case: all_the_small_things
--------------------
Summary
In this lab, you learned how to create a Python function that converts strings from various formats to snake case. Here's what you accomplished:
- You learned how regular expressions can be used for pattern matching and string transformation
- You implemented a function that can handle different input formats:
- camelCase (e.g.,
camelCase→camel_case) - PascalCase (e.g.,
HelloWorld→hello_world) - Strings with spaces (e.g.,
some text→some_text) - Strings with hyphens (e.g.,
hello-world→hello_world) - Mixed formats with various delimiters and capitalization
- camelCase (e.g.,
The key techniques you used:
- Regular expressions with capture groups using
re.sub() - String methods like
replace(),lower(),split(), andjoin() - Pattern recognition for different naming conventions
These skills are valuable for data cleaning, processing text input, and maintaining consistent coding standards. The ability to convert between different case formats is particularly useful when working with APIs or libraries that use different naming conventions.