
Введение
В версиях Hadoop 2.0 и выше была введена новая модель управления ресурсами YARN, которая облегчает использование кластера,统一ное управление ресурсами и обмен данными. На основе построения псевдо-распределенного кластера Hadoop в этом разделе вы узнаете об архитектуре, принципах работы, настройке, а также методах разработки и мониторинга фреймворка YARN.
Этот практикум требует определенных знаний в Java-программировании.
Пожалуйста, вводите все примеры кода из документа самостоятельно; старайтесь не просто копировать и вставлять. Таким образом вы будете более знакомы с кодом. Если у вас возникнут проблемы, внимательно пересмотрите документацию, или вы можете обратиться за помощью и обсудить проблему на форуме.
Архитектура и компоненты YARN
YARN, представленный в Hadoop 0.23 в составе MapReduce 2.0 (MRv2), revolutionized the resource management and job scheduling in Hadoop clusters:
- Разделение функций JobTracker:
MRv2разбивает функцииJobTrackerна отдельные демоны -ResourceManagerдля управления ресурсами иApplicationMasterдля планирования и мониторинга задач. - Глобальный ResourceManager: Каждая программа имеет соответствующего
ApplicationMaster, который может быть задачей MapReduce или DAG, описывающим задачу. - Фреймворк для вычислений данных:
ResourceManager,SlaveиNodeManagerобразуют фреймворк, в которомResourceManagerконтролирует все ресурсы приложений. - Компоненты ResourceManager:
Schedulerраспределяет ресурсы на основе ограничений, таких как емкость и очереди, в то время какApplicationsManagerобрабатывает подачу задач и выполнениеApplicationMaster. - Выделение ресурсов: Требования к ресурсам определяются с использованием контейнеров ресурсов с элементами, такими как память, процессор, диск и сеть.
- Роль NodeManager:
NodeManagerотслеживает использование ресурсов контейнера и отчетит о нихResourceManagerиScheduler. - Задачи ApplicationMaster:
ApplicationMasterпереговывает сSchedulerо контейнерах ресурсов, отслеживает статус и контролирует ход выполнения.
На следующей картинке показано отношение между компонентами:

YARN обеспечивает совместимость API с предыдущими версиями, что позволяет безболезненно переключаться на выполнение задач MapReduce. Понимание архитектуры и компонентов YARN необходимо для эффективного управления ресурсами и планирования задач в кластерах Hadoop.
Запуск демона Hadoop
Прежде чем изучать соответствующие параметры конфигурации и методы разработки приложений YARN, нам нужно запустить демон Hadoop, чтобы он был随时 доступен для использования.
Сначала двойным щелчком откройте терминал Xfce на рабочем столе и введите следующую команду, чтобы переключиться на пользователя hadoop:
su - hadoop
Совет: Пароль - это 'hadoop' для пользователя 'hadoop'.
После завершения переключения вы можете запустить демоны, связанные с Hadoop, включая фреймворки HDFS и YARN.
Введите следующие команды в терминале, чтобы запустить демоны:
/home/hadoop/hadoop/sbin/start-dfs.sh
/home/hadoop/hadoop/sbin/start-yarn.sh
После завершения запуска вы можете использовать команду jps, чтобы проверить, запущены ли связанные демоны.
hadoop:~$ jps
3378 NodeManager
3028 SecondaryNameNode
3717 Jps
2791 DataNode
2648 NameNode
3240 ResourceManager
Подготовка файла конфигурации
В этом разделе мы узнаем о yarn-site.xml, который является одним из основных файлов конфигурации Hadoop, и посмотрим, какие настройки можно сделать для кластера YARN в этом файле.
Чтобы предотвратить неправильное использование изменений в файле конфигурации, лучше скопировать файл конфигурации Hadoop в другой каталог и затем открыть его.
Для этого введите следующую команду в терминале, чтобы создать новый каталог для файла конфигурации:
mkdir /home/hadoop/hadoop_conf
Затем скопируйте главный файл конфигурации YARN yarn-site.xml из каталога установки в новый каталог.
Введите следующую команду в терминале, чтобы выполнить операцию:
cp /home/hadoop/hadoop/etc/hadoop/yarn-site.xml /home/hadoop/hadoop_conf/yarn-site.xml
Затем используйте редактор vim, чтобы открыть файл и просмотреть его содержимое:
vim /home/hadoop/hadoop_conf/yarn-site.xml
Как работает файл конфигурации
Мы знаем, что в фреймворке YARN есть две важные роли: ResourceManager и NodeManager. Поэтому каждый параметр конфигурации в файле - это настройка этих двух компонентов.
В этом файле можно установить множество параметров конфигурации, но по умолчанию он не содержит никаких пользовательских параметров конфигурации. Например, в файле, который мы сейчас открываем, есть только атрибут aux-services, заданный при предыдущей настройке псевдо-распределенного кластера Hadoop, как показано на следующем рисунке:
hadoop:~$ cat /home/hadoop/hadoop/etc/hadoop/mapred-site.xml
...
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
Этот параметр конфигурации используется для настройки зависимых служб, которые необходимо запускать на NodeManager. Значение конфигурации, которое мы указали, - это mapreduce_shuffle, что означает, что по умолчанию программа MapReduce должна запускаться на YARN.
То, что параметры конфигурации не записаны в файл, не означает, что они не работают. Когда параметры конфигурации не указаны явно в файле, фреймворк YARN Hadoop будет читать значения по умолчанию, хранящиеся в внутренних файлах. Все параметры конфигурации, явно указанные в файле yarn-site.xml, будут переопределять значения по умолчанию, что является эффективным способом адаптации системы Hadoop к различным сценариям использования.
Параметры конфигурации ResourceManager
Понимание и правильная настройка параметров ResourceManager в файле yarn-site.xml является важным для эффективного управления ресурсами и выполнения задач в кластере Hadoop. Вот краткое описание основных параметров конфигурации, связанных с ResourceManager:
yarn.resourcemanager.address: Предоставляет адрес для клиентов для подачи и завершения приложений. По умолчанию порт - 8032.yarn.resourcemanager.scheduler.address: Предоставляет адрес для ApplicationMaster для запроса и освобождения ресурсов. По умолчанию порт - 8030.yarn.resourcemanager.resource-tracker.address: Предоставляет адрес для NodeManager для отправки сердцебиений и извлечения задач. По умолчанию порт - 8031.yarn.resourcemanager.admin.address: Предоставляет адрес для администраторов для управления командами. По умолчанию порт - 8033.yarn.resourcemanager.webapp.address: Адрес веб-интерфейса для просмотра информации о кластере. По умолчанию порт - 8088.yarn.resourcemanager.scheduler.class: Указывает имя главного класса планировщика (например, FIFO, CapacityScheduler, FairScheduler).- Конфигурация потоков:
yarn.resourcemanager.resource-tracker.client.thread-countyarn.resourcemanager.scheduler.client.thread-count
- Выделение ресурсов:
yarn.scheduler.minimum-allocation-mbyarn.scheduler.maximum-allocation-mbyarn.scheduler.minimum-allocation-vcoresyarn.scheduler.maximum-allocation-vcores
- Управление NodeManager:
yarn.resourcemanager.nodes.exclude-pathyarn.resourcemanager.nodes.include-path
- Конфигурация сердцебиений:
yarn.resourcemanager.nodemanagers.heartbeat-interval-ms
Настройка этих параметров позволяет точно настроить поведение ResourceManager, выделение ресурсов, обработку потоков, управление NodeManager и интервалы сердцебиений в кластере Hadoop. Понимание этих параметров конфигурации помогает предотвратить проблемы и обеспечить гладкую работу кластера.
Параметры конфигурации NodeManager
Настройка параметров NodeManager в файле yarn-site.xml является важной для эффективного управления ресурсами и задачами в кластере Hadoop. Вот краткое описание основных параметров конфигурации, связанных с NodeManager:
yarn.nodemanager.resource.memory-mb: Указывает общую доступную физическую память для NodeManager. Это значение остается постоянным на протяжении работы YARN.yarn.nodemanager.vmem-pmem-ratio: Задает отношение выделения виртуальной памяти к физической памяти. По умолчанию отношение -2.1.yarn.nodemanager.resource.cpu-vcores: Определяет общее количество виртуальных процессоров, доступных для NodeManager. По умолчанию значение -8.yarn.nodemanager.local-dirs: Путь для хранения промежуточных результатов на NodeManager, позволяет настроить несколько директорий.yarn.nodemanager.log-dirs: Путь к директории с логами NodeManager, поддерживает настройку нескольких директорий.yarn.nodemanager.log.retain-seconds: Максимальное время хранения логов NodeManager, по умолчанию - 10800 секунд (3 часа).
Настройка этих параметров позволяет точно настроить выделение ресурсов, управление памятью, пути директорий и настройки хранения логов для оптимальной производительности и использования ресурсов NodeManager в кластере Hadoop. Понимание этих параметров конфигурации помогает обеспечить гладкую работу и эффективное выполнение задач в кластере.
Поиск параметров конфигурации и ссылки на значения по умолчанию
Для изучения всех параметров конфигурации, доступных в YARN и других распространенных компонентах Hadoop, можно обратиться к файлам конфигурации по умолчанию, предоставляемым Apache Hadoop. Вот ссылки на доступ к настройкам по умолчанию:
Параметры конфигурации YARN:
Общие файлы конфигурации:
- core-default.xml (core-site.xml)
- hdfs-default.xml (hdfs-site.xml)
- mapred-default.xml (mapred-site.xml)
Изучение этих настроек по умолчанию предоставляет подробное описание каждого параметра конфигурации и его назначения, помогая понять роль каждого параметра в проектировании архитектуры Hadoop.
После ознакомления с настройками можно закрыть редактор vim, чтобы завершить изучение настроек конфигурации Hadoop.
Создание директорий и файлов проекта
Давайте узнаем о процессе разработки приложения YARN, имитируя официальное приложение YARN.
Сначала создайте директорию проекта. Введите следующую команду в терминале для создания директории:
mkdir /home/hadoop/yarn_app
Затем создайте два файла исходного кода в проекте отдельно.
Первый файл - это Client.java. Создайте файл с помощью команды touch в терминале:
touch /home/hadoop/yarn_app/Client.java
Затем создайте файл ApplicationMaster.java:
touch /home/hadoop/yarn_app/ApplicationMaster.java
hadoop:~$ tree /home/hadoop/yarn_app/
/home/hadoop/yarn_app/
├── ApplicationMaster.java
└── Client.java
0 directories, 2 files
Написание кода клиента
Написав код для Client, вы сможете понять API и их роли, необходимые для разработки Client в рамках фреймворка YARN.
Содержание кода довольно длинное. Более эффективный способ, чем читать его построчно, - это вводить его построчно в файл исходного кода, который вы только что создали.
Сначала откройте файл Client.java, который только что создан, с помощью редактора vim (или другого текстового редактора):
vim /home/hadoop/yarn_app/Client.java
Затем добавьте тело программы, чтобы указать имя класса и имя пакета для класса:
package com.labex.yarn.app;
public class Client {
public static void main(String[] args){
//TODO: Edit code here.
}
}
Следующий код представлен в виде сегментов. При написании вставьте следующий код в класс Client (то есть в блок кода, где находится комментарий //TODO: Edit your code here).
Первым делом клиент должен создать и инициализировать объект YarnClient, а затем запустить его:
YarnClient yarnClient = YarnClient.createYarnClient();
yarnClient.init(conf);
yarnClient.start();
После создания Client нам нужно создать объект YARN-приложения и его идентификатор приложения:
YarnClientApplication app = yarnClient.createApplication();
GetNewApplicationResponse appResponse = app.getNewApplicationResponse();
Объект appResponse содержит информацию о кластере, такой как минимальные и максимальные ресурсные возможности кластера. Эта информация нужна, чтобы мы могли правильно настроить параметры, когда ApplicationMaster запускает соответствующий контейнер.
Одной из основных задач в Client является настройка ApplicationSubmissionContext. Он определяет все информацию, которую RM 需要 для запуска AM.
В целом, Client должен настроить следующее в контексте:
- Информация о приложении: Включает идентификатор и имя приложения.
- Информация о очереди и приоритете: Включает очереди и назначенные приоритеты для подачи приложений.
- Пользователи: Кто является пользователем, отправившим приложение.
- ContainerLaunchContext: Определяет информацию о контейнере, в котором нужно запустить и запустить AM. Все необходимые для запуска приложения сведения определяются в
ContainerLaunchContext, включая локальные ресурсы (бинарные файлы, jar-файлы и т.д.), переменные окружения (CLASSPATHи т.д.), команды для выполнения и безопасный токен (RECT):
// Set the application to submit the context
ApplicationSubmissionContext appContext = app.getApplicationSubmissionContext();
ApplicationId appId = appContext.getApplicationId();
appContext.setKeepContainersAcrossApplicationAttempts(keepContainers);
appContext.setApplicationName(appName);
// The following code is used to set the local resources of ApplicationMaster
/ / Local resources need to be local files or compressed packages etc.
// In this scenario, the jar package is in the form of a file as one of AM's local resources.
Map<String, LocalResource> localResources = new HashMap<String, LocalResource>();
LOG.info("Copy AppMaster jar from local filesystem and add to local environment.");
// Copy the jar package of ApplicationMaster into the file system
FileSystem fs = FileSystem.get(conf);
// Create a local resource that points to the jar package path
addToLocalResources(fs, appMasterJar, appMasterJarPath, appId.toString(), localResources, null);
// Set the parameters of logs, you can skip it
if (!log4jPropFile.isEmpty()) {
addToLocalResources(fs, log4jPropFile, log4jPath, appId.toString(), localResources, null);
}
// The shell script will be available in the container that will eventually execute it
// So first copy it to the file system so that the YARN framework can find it
// You don't need to set it to the local resource of AM here because the latter doesn't need it
String hdfsShellScriptLocation = "";
long hdfsShellScriptLen = 0;
long hdfsShellScriptTimestamp = 0;
if (!shellScriptPath.isEmpty()) {
Path shellSrc = new Path(shellScriptPath);
String shellPathSuffix = appName + "/" + appId.toString() + "/" + SCRIPT_PATH;
Path shellDst = new Path(fs.getHomeDirectory(), shellPathSuffix);
fs.copyFromLocalFile(false, true, shellSrc, shellDst);
hdfsShellScriptLocation = shellDst.toUri().toString();
FileStatus shellFileStatus = fs.getFileStatus(shellDst);
hdfsShellScriptLen = shellFileStatus.getLen();
hdfsShellScriptTimestamp = shellFileStatus.getModificationTime();
}
if (!shellCommand.isEmpty()) {
addToLocalResources(fs, null, shellCommandPath, appId.toString(),
localResources, shellCommand);
}
if (shellArgs.length > 0) {
addToLocalResources(fs, null, shellArgsPath, appId.toString(),
localResources, StringUtils.join(shellArgs, " "));
}
// Set the environment parameters that AM requires
LOG.info("Set the environment for the application master");
Map<String, String> env = new HashMap<String, String>();
// Add the path to the shell script to the environment variable
// AM will create the correct local resource for the final container accordingly
// and the above container will execute the shell script at startup
env.put(DSConstants.DISTRIBUTEDSHELLSCRIPTLOCATION, hdfsShellScriptLocation);
env.put(DSConstants.DISTRIBUTEDSHELLSCRIPTTIMESTAMP, Long.toString(hdfsShellScriptTimestamp));
env.put(DSConstants.DISTRIBUTEDSHELLSCRIPTLEN, Long.toString(hdfsShellScriptLen));
// Add the path to AppMaster.jar to the classpath
// Note that there is no need to provide a Hadoop-related classpath here, as we have an annotation in the external configuration file.
// The following code adds all the classpath-related path settings required by AM to the current directory
StringBuilder classPathEnv = new StringBuilder(Environment.CLASSPATH.$$())
.append(ApplicationConstants.CLASS_PATH_SEPARATOR).append("./*");
for (String c : conf.getStrings(
YarnConfiguration.YARN_APPLICATION_CLASSPATH,
YarnConfiguration.DEFAULT_YARN_CROSS_PLATFORM_APPLICATION_CLASSPATH)) {
classPathEnv.append(ApplicationConstants.CLASS_PATH_SEPARATOR);
classPathEnv.append(c.trim());
}
classPathEnv.append(ApplicationConstants.CLASS_PATH_SEPARATOR).append(
"./log4j.properties");
// Set the command to execute AM
Vector<CharSequence> vargs = new Vector<CharSequence>(30);
// Set the executable command for Java
LOG.info("Setting up app master command");
vargs.add(Environment.JAVA_HOME.$$() + "/bin/java");
// Set the memory numbers assigned by Xmx parameters under JVM
vargs.add("-Xmx" + amMemory + "m");
// Set class names
vargs.add(appMasterMainClass);
// Set the parameter of ApplicationMaster
vargs.add("--container_memory " + String.valueOf(containerMemory));
vargs.add("--container_vcores " + String.valueOf(containerVirtualCores));
vargs.add("--num_containers " + String.valueOf(numContainers));
vargs.add("--priority " + String.valueOf(shellCmdPriority));
for (Map.Entry<String, String> entry : shellEnv.entrySet()) {
vargs.add("--shell_env " + entry.getKey() + "=" + entry.getValue());
}
if (debugFlag) {
vargs.add("--debug");
}
vargs.add("1>" + ApplicationConstants.LOG_DIR_EXPANSION_VAR + "/AppMaster.stdout");
vargs.add("2>" + ApplicationConstants.LOG_DIR_EXPANSION_VAR + "/AppMaster.stderr");
// Generate the final parameter and configure
StringBuilder command = new StringBuilder();
for (CharSequence str : vargs) {
command.append(str).append(" ");
}
LOG.info("Completed setting up app master command " + command.toString());
List<String> commands = new ArrayList<String>();
commands.add(command.toString());
// Set container for AM to start context
ContainerLaunchContext amContainer = ContainerLaunchContext.newInstance(
localResources, env, commands, null, null, null);
// The requirement of setting resource types, including memory and virtual CPU cores.
Resource capability = Resource.newInstance(amMemory, amVCores);
appContext.setResource(capability);
// If needed, the data of YARN service is passed to the applications in binary format. But it's not needed in this example.
// amContainer.setServiceData(serviceData);
// Set the Token
if (UserGroupInformation.isSecurityEnabled()) {
Credentials credentials = new Credentials();
String tokenRenewer = conf.get(YarnConfiguration.RM_PRINCIPAL);
if (tokenRenewer == null || tokenRenewer.length() == 0) {
throw new IOException(
"Can't get Master Kerberos principal for the RM to use as renewer");
}
// Get the token of the default file system
final Token<?> tokens[] =
fs.addDelegationTokens(tokenRenewer, credentials);
if (tokens!= null) {
for (Token<?> token : tokens) {
LOG.info("Got dt for " + fs.getUri() + "; " + token);
}
}
DataOutputBuffer dob = new DataOutputBuffer();
credentials.writeTokenStorageToStream(dob);
ByteBuffer fsTokens = ByteBuffer.wrap(dob.getData(), 0, dob.getLength());
amContainer.setTokens(fsTokens);
}
appContext.setAMContainerSpec(amContainer);
После завершения настройки процесс клиент может отправить приложение с указанным приоритетом и очередью:
/ / Set the priority of AM
Priority pri = Priority.newInstance(amPriority);
appContext.setPriority(pri);
// Set the queue where the application submits to RM
appContext.setQueue(amQueue);
// Submit the app to AM
yarnClient.submitApplication(appContext);
В этом случае RM примет приложение и запустит и настроит AM в заднем фоне на назначенном контейнере.
Клиенты могут отслеживать ход выполнения фактических задач разными способами.
(1) Одним из них является то, что вы можете общаться с RM с помощью метода getApplicationReport() объекта YarnClient и запросить отчет о приложении:
// Use the app ID to get its report
ApplicationReport report = yarnClient.getApplicationReport(appId);
Отчеты, полученные от RM, включают следующее:
- Общая информация: Включает номер (положение) приложения, очередь для подачи приложения, пользователя, отправившего приложение и время начала приложения.
- Детали ApplicationMaster: Хост, на котором запущен AM, RPC-порт, который слушает запросы от Clientов и токены, которые Client и AM 需要 для общения.
- Информация о отслеживании приложения: Если приложение поддерживает некоторую форму отслеживания прогресса, оно может установить отслеживаемую URL-адрес с помощью метода
getTrackingUrl(), отчет которого сообщает приложение, и клиент может отслеживать прогресс с помощью этого метода. - Статус приложения: Вы можете увидеть статус приложения в
ResourceManagerвgetYarnApplicationState. ЕслиYarnApplicationStateустановлен вcomplete, клиент должен ссылаться наgetFinalApplicationStatus, чтобы проверить, успешно ли фактически выполнены задачи приложения. В случае неудачи можно найти дополнительную информацию о причине неудачи с помощьюgetDiagnostics.
(2) Если ApplicationMaster поддерживает это, Client может напрямую запросить прогресс самого AM, используя информацию hostname:rpcport, полученную из отчета о приложении.
В некоторых случаях, если приложение выполняется слишком долго, клиент может захотеть завершить приложение. YarnClient поддерживает вызов killApplication. Это позволяет клиенту отправить сигнал завершения AM через ResourceManager. Если так спроектировано, менеджер приложений также может завершить вызов с помощью его поддержки RPC-слоя, которое клиент может использовать.
Сpecific код выглядит следующим образом, но код приведен только в качестве примера и не нужно писать его в Client.java:
yarnClient.killApplication(appId);
После редактирования вышеуказанного содержания сохраните его и выйдите из редактора vim.
Написание кода ApplicationMaster
Аналогично, используйте редактор vim, чтобы открыть файл ApplicationMaster.java и написать код:
vim /home/hadoop/yarn_app/ApplicationMaster.java
package com.labex.yarn.app;
public class ApplicationMaster {
public static void main(String[] args){
//TODO:Edit code here.
}
}
Пояснения к коду также будут представлены в виде сегментов. Все код, упоминаемый ниже, должен быть написан в классе ApplicationMaster (то есть в блоке кода, где находится комментарий //TODO:Edit code here.).
AM - это фактический владелец задачи, который запускается RM и предоставляет все необходимые сведения и ресурсы через Клиента для управления и завершения задачи.
Поскольку AM запускается в одном контейнере,很可能该容器与其他容器共享同一物理主机。考虑到云计算平台的多租户特性和其他问题,一开始可能无法知道预先配置的要监听的端口。
因此,当 AM 启动时,可以通过环境为其提供几个参数。这些参数包括 AM 容器的 ContainerId、应用程序的提交时间以及运行 AM 的 NodeManager 主机的详细信息。
与 RM 的所有交互都需要应用程序进行调度。如果此过程失败,每个应用程序可能会再次尝试。您可以从 AM 的容器 ID 中获取 ApplicationAttemptId。有相关的 API 可以将从环境中获取的值转换为对象。
Напишите следующий код:
Map<String, String> envs = System.getenv();
String containerIdString = envs.get(ApplicationConstants.AM_CONTAINER_ID_ENV);
If (containerIdString == null) {
// The container ID should be set in the environment variable of the framework
Throw new IllegalArgumentException(
"Container ID not set in the environment");
}
ContainerId containerId = ConverterUtils.toContainerId(containerIdString);
ApplicationAttemptId appAttemptID = containerId.getApplicationAttemptId();
После полной инициализации AM мы можем запустить двух клиентов: одного клиента к ResourceManager и другого - к NodeManager. Мы используем пользовательский обработчик событий для настройки этого, и подробности будут обсуждаться позже:
AMRMClientAsync.CallbackHandler allocListener = new RMCallbackHandler();
amRMClient = AMRMClientAsync.createAMRMClientAsync(1000, allocListener);
amRMClient.init(conf);
amRMClient.start();
containerListener = createNMCallbackHandler();
nmClientAsync = new NMClientAsyncImpl(containerListener);
nmClientAsync.init(conf);
nmClientAsync.start();
AM должен периодически отправлять сердцебиения RM, чтобы последний знал, что AM все еще работает. Интервал истечения срока действия на RM определяется YarnConfiguration, а его значение по умолчанию определяется конфигурационным параметром YarnConfiguration.RM_AM_EXPIRY_INTERVAL_MS в файле конфигурации. AM должен зарегистрироваться в ResourceManager, чтобы начать отправлять сердцебиения:
// Register yourself with RM and start sending heartbeats to RM
appMasterHostname = NetUtils.getHostname();
RegisterApplicationMasterResponse response = amRMClient.registerApplicationMaster(appMasterHostname, appMasterRpcPort, appMasterTrackingUrl);
Информация ответа процесса регистрации может включать максимальные ресурсные возможности кластера. Мы можем использовать эту информацию для проверки запроса приложения:
// Temporarily save information about cluster resource capabilities in RM
int maxMem = response.getMaximumResourceCapability().getMemory();
LOG.info("Max mem capability of resources in this cluster " + maxMem);
int maxVCores = response.getMaximumResourceCapability().getVirtualCores();
LOG.info("Max vcores capability of resources in this cluster " + maxVCores);
// Use the maximum memory limit to constrain the container's memory capacity request value
if (containerMemory > maxMem) {
LOG.info("Container memory specified above max threshold of cluster."
+ " Using max value." + ", specified=" + containerMemory + ", max="
+ maxMem);
containerMemory = maxMem;
}
if (containerVirtualCores > maxVCores) {
LOG.info("Container virtual cores specified above max threshold of cluster."
+ " Using max value." + ", specified=" + containerVirtualCores + ", max="
+ maxVCores);
containerVirtualCores = maxVCores;
}
List<Container> previousAMRunningContainers =
response.getContainersFromPreviousAttempts();
LOG.info("Received " + previousAMRunningContainers.size()
+ " previous AM's running containers on AM registration.");
В зависимости от требований к задаче AM может планировать запуск набора контейнеров для выполнения задач. Мы используем эти требования, чтобы вычислить, сколько контейнеров нам нужно, и запросить соответствующее количество контейнеров:
int numTotalContainersToRequest = numTotalContainers - previousAMRunningContainers.size();
for (int i = 0; i < numTotalContainersToRequest; ++i) {
//Set the request object to the RM request container
ContainerRequest containerAsk = setupContainerAskForRM();
//Send container request to RM
amRMClient.addContainerRequest(containerAsk);
// This loop means polling RM for containers after getting fully allocated quotas
}
Вышеприведенный цикл будет выполняться до тех пор, пока все контейнеры не будут запущены и не будет выполнен shell-скрипт (независимо от того, будет ли это успешным или нет).
В setupContainerAskForRM() вам нужно настроить следующее:
- **Resource capabilities:**Currently, YARN supports memory-based resource requirements, so the request should define how much memory is needed. This value is defined in megabytes and must be less than the exact multiple of the cluster's maximum and minimum capabilities. This memory resource corresponds to the physical memory limit imposed on the task container. Resource capabilities also include computation-based resources (vCore).
- Priority: When requesting a container set, AM can define different priorities for collections. For example, MapReduce AM can assign a higher priority to the containers required by the Map task, while the Reduce task container has a lower priority:
Private ContainerRequest setupContainerAskForRM() {
/ / Set the priority of the request
Priority pri = Priority.newInstance(requestPriority);
/ / Set the request for the resource type, including memory and CPU
Resource capability = Resource.newInstance(containerMemory,
containerVirtualCores);
ContainerRequest request = new ContainerRequest(capability, null, null, pri);
LOG.info("Requested container allocation: " + request.toString());
Return request;
}
После того, как AM отправил запрос на выделение контейнера, контейнер запускается асинхронно обработчиком событий клиента AMRMClientAsync. Программы, обрабатывающие эту логику, должны реализовать интерфейс AMRMClientAsync.CallbackHandler.
(1) Когда контейнер разрешен на обработку, обработчик должен запустить поток. Поток выполняет соответствующий код для запуска контейнера. Здесь мы используем LaunchContainerRunnable для демонстрации. Мы обсудим этот класс позже:
@Override
public void onContainersAllocated(List<Container> allocatedContainers) {
LOG.info("Got response from RM for container allocation, allocatedCnt=" + allocatedContainers.size());
numAllocatedContainers.addAndGet(allocatedContainers.size());
for (Container allocatedContainer : allocatedContainers) {
LaunchContainerRunnable runnableLaunchContainer =
new LaunchContainerRunnable(allocatedContainer, containerListener);
Thread launchThread = new Thread(runnableLaunchContainer);
// Start and run the container with different threads, which prevents the main thread from blocking when all the containers cannot be allocated resources
launchThreads.add(launchThread);
launchThread.start();
}
}
(2) Когда отправляется сердцебиение, обработчик событий должен сообщать о прогрессе приложения:
@Override
public float getProgress() {
// Set the progress information and report it to RM the next time you send a heartbeat
float progress = (float) numCompletedContainers.get() / numTotalContainers;
Return progress;
}
Поток запуска контейнера фактически запускает контейнер на NM. После назначения контейнера AM ему нужно следовать аналогичному процессу, который следует Клиент при настройке ContainerLaunchContext для выполнения конечной задачи на выделенном контейнере. После определения ContainerLaunchContext, AM может запустить его с помощью NMClientAsync:
// Set the necessary commands to execute on the allocated container
Vector<CharSequence> vargs = new Vector<CharSequence>(5);
// Set the executable command
vargs.add(shellCommand);
// Set the path of the shell script
if (!scriptPath.isEmpty()) {
vargs.add(Shell.WINDOWS? ExecBatScripStringtPath
: ExecShellStringPath);
}
// Set parameters for shell commands
vargs.add(shellArgs);
// Add log redirection parameters
vargs.add("1>" + ApplicationConstants.LOG_DIR_EXPANSION_VAR + "/stdout");
vargs.add("2>" + ApplicationConstants.LOG_DIR_EXPANSION_VAR + "/stderr");
// Get the final command
StringBuilder command = new StringBuilder();
for (CharSequence str : vargs) {
command.append(str).append(" ");
}
List<String> commands = new ArrayList<String>();
commands.add(command.toString());
// Set ContainerLaunchContext to set local resources, environment variables, commands and tokens for the constructor.
ContainerLaunchContext ctx = ContainerLaunchContext.newInstance(
localResources, shellEnv, commands, null, allTokens.duplicate(), null);
containerListener.addContainer(container.getId(), container);
nmClientAsync.startContainerAsync(container, ctx);
Объект NMClientAsync и его обработчик событий отвечают за обработку событий контейнера. Это включает в себя запуск, остановку, обновление статуса и ошибки для контейнера.
После того, как ApplicationMaster определит, что все сделано, ему нужно отменить регистрацию с Клиентом AM-RM и затем остановить Клиента:
try {
amRMClient.unregisterApplicationMaster(appStatus, appMessage, null);
} catch (YarnException ex) {
LOG.error("Failed to unregister application", ex);
} catch (IOException e) {
LOG.error("Failed to unregister application", e);
}
amRMClient.stop();
Вышеприведенное содержание - это основной код ApplicationMaster. После редактирования сохраните содержание и выйдите из редактора vim.
Процесс запуска приложения
Процесс запуска приложения на кластере Hadoop выглядит следующим образом:
Компиляция и запуск приложения
После завершения кода из предыдущего раздела вы можете скомпилировать его в Jar-пакет и отправить его на кластер Hadoop с использованием инструмента сборки, такого как Maven и Gradle.
Поскольку процесс компиляции требует подключения к сети для извлечения соответствующих зависимостей, он занимает много времени (около 1 часа в пике). Поэтому здесь пропустите процесс компиляции и используйте уже скомпилированный Jar-пакет в директории установки Hadoop для последующих экспериментов.
В этом шаге мы используем простой пример Jar для запуска приложения YARN, вместо того чтобы создавать указанный Jar с помощью Maven.
Введите команду yarn jar в терминале для отправки выполнения. Параметры, используемые в следующих командах, - это путь к Jar-пакету для запуска, имя главного класса, путь к Jar-пакету, отправленному в фреймворк YARN, количество выполняемых shell-команд и количество контейнеров:
/home/hadoop/hadoop/bin/yarn jar /home/hadoop/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar pi 3 3
Посмотрите вывод в терминале, и вы сможете увидеть ход выполнения приложения.
Estimated value of Pi is 3.55555555555555555556
Во время выполнения задачи вы можете увидеть подсказки на каждом этапе из вывода в терминале, таких как инициализация Клиента, подключение к RM и получение информации о кластере.
Просмотр результатов выполнения приложения
Дважды щелкните, чтобы открыть браузер Firefox на рабочем столе и введите следующий URL в адресной строке, чтобы просмотреть информацию о ресурсах узлов в YARN-шаблоне кластера Hadoop:
http://localhost:8088
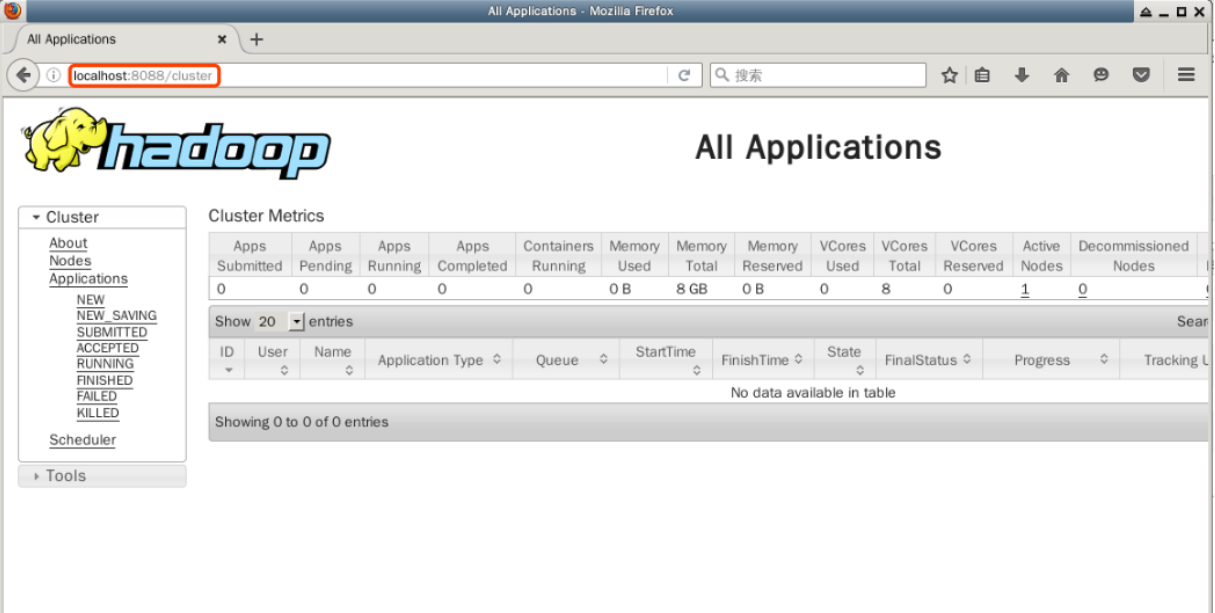
На этой странице отображается вся информация о кластере Hadoop, включая статус узлов, приложений и планировщиков.
Самым важным из этого является управление приложением, и мы сможем увидеть статус выполнения отправленного приложения здесь позже. Пожалуйста, не закрывайте браузер Firefox на данный момент.
Резюме
На основе завершенного псевдо-распределенного кластера Hadoop этот практикум продолжает обучать нас архитектуре, принципам работы, настройке, а также разработке и методам мониторинга фреймворка YARN. В курсе представлено много кода и файлов конфигурации, поэтому внимательно изучите их.


