
Введение
Этот практикум посвящен основам Hadoop и предназначен для студентов с определенным опытом работы с Linux, чтобы они могли понять архитектуру программной системы Hadoop и основные методы развертывания.
Пожалуйста, вводите все примеры кода из документа самостоятельно и尽量 не просто копируйте и вставляйте. Только таким образом вы будете более знакомы с кодом. Если у вас возникнут проблемы, внимательно пересмотрите документацию, иначе вы можете обратиться за помощью и общением на форум.
Введение в Hadoop
Размещен под лицензией Apache 2.0, Apache Hadoop - это open source программный фреймворк, который поддерживает распределенные приложения, интенсивные по обработке данных.
Библиотека программного обеспечения Apache Hadoop - это фреймворк, который позволяет выполнять распределенную обработку больших наборов данных по вычислительным кластерам с использованием простой модели программирования. Он предназначен для масштабирования от одного сервера до数千 машин, каждая из которых обеспечивает локальное вычисление и хранение, а не полагается на аппаратное обеспечение для обеспечения высокой доступности.
Основные концепции
Проект Hadoop в основном включает следующие четыре модуля:
- Hadoop Common: Общее приложение, которое обеспечивает поддержку для других модулей Hadoop.
- Hadoop Distributed File System (HDFS): Распределенная файловая система, которая обеспечивает высокопроизводительное доступ к данным приложения.
- Hadoop YARN: Фреймворк планирования задач и управления ресурсами кластера.
- Hadoop MapReduce: Фреймворк параллельного вычисления для больших наборов данных на основе YARN.
Для пользователей, которые впервые сталкиваются с Hadoop, следует сосредоточиться на HDFS и MapReduce. Как распределенный вычислительный фреймворк, HDFS удовлетворяет требованиям фреймворка по хранению данных, а MapReduce - требованиям по вычислению данных.
Следующая картинка показывает базовую архитектуру кластера Hadoop:
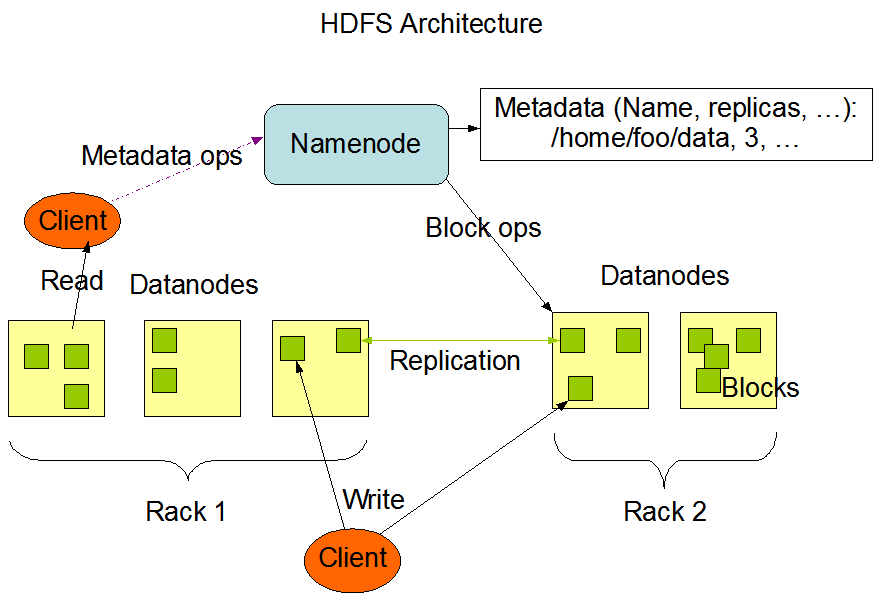
Эта картинка взята с официального сайта Hadoop.
Экосистема Hadoop
Похож на то, как Facebook разработал хранилище данных Hive на основе Hadoop, в сообществе есть много открытых исходных проектов, связанных с ним. Вот некоторые недавно активные проекты:
- HBase: Масштабируемая распределенная база данных, которая поддерживает хранение структурированных данных для больших таблиц.
- Hive: Инфраструктура хранилища данных, которая обеспечивает суммирование данных и временные запросы.
- Pig: Расширенный язык потока данных и фреймворк выполнения для параллельных вычислений.
- ZooKeeper: Высокопроизводительная служба координации для распределенных приложений.
- Spark: Быстрый и универсальный Hadoop-эн진 вычислений с простой и выразительной моделью программирования, который поддерживает ETL (извлечение, преобразование и загрузка) данных, машинное обучение, обработку потоков и графические вычисления.
В этом практикуме мы начнем с Hadoop и познакомимся с основными использованием связанных компонентов.
Следует отметить, что Spark, распределенный фреймворк вычислений в памяти, произошел из системы Hadoop. Он хорошо наследует компоненты, такие как HDFS и YARN, и также устраняет некоторые существующие недостатки Hadoop.
Некоторые из вас, возможно, зададут вопросы о перекрытии сценариев использования Hadoop и Spark, но изучение модели работы и модели программирования Hadoop поможет углубить понимание Spark-фреймворка, и именно поэтому стоит изучить Hadoop сначала.
Развертывание Hadoop
Для начинающих между версиями Hadoop после 2.0 практически нет различий. В этом разделе мы рассмотрим пример развертывания версии 3.3.6.
Hadoop имеет три основных модели развертывания:
- Одноузловая модель: Запускается в одном процессе на одном компьютере.
- Псевдо-распределенная модель: Запускается в нескольких процессах на одном компьютере. Эта модель имитирует сценарий "многокорневого" кластера на одном узле.
- Полностью распределенная модель: Запускается в одном процессе на каждом из нескольких компьютеров.
Далее мы установим версию Hadoop 3.3.6 на одном компьютере.
Настройка пользователей и групп пользователей
Двойным щелчком откройте терминал Xfce на вашем рабочем столе и введите следующую команду, чтобы создать пользователя с именем hadoop:
cd ~
sudo adduser hadoop
Затем следуйте подсказкам и введите пароль для пользователя hadoop; например, установите пароль hadoop.
Примечание: Когда вы вводите пароль, в команде не появляется подсказка. Вы можете просто нажать клавишу Enter, когда закончите ввод.
Затем добавьте созданного пользователя hadoop в группу пользователей sudo, чтобы дать пользователю более высокие права:
sudo usermod -G sudo hadoop
Проверьте, что пользователь hadoop добавлен в группу sudo, введя следующую команду:
sudo cat /etc/group | grep hadoop
Вы должны увидеть следующий вывод:
sudo:x:27:shiyanlou,labex,hadoop
Установка JDK
Как упоминалось в предыдущем контенте, Hadoop в основном разработан на Java. Поэтому для его запуска требуется Java-окружение.
У разных версий Hadoop есть незначительные различия в требованиях к версии Java. Чтобы определить, какую версию JDK следует выбрать для вашего Hadoop, вы можете прочитать Hadoop Java Versions на веб-сайте Hadoop Wiki.
Переключитесь на пользователя:
su - hadoop
Установите версию JDK 11, введя следующую команду в терминале:
sudo apt update
sudo apt install openjdk-11-jdk -y
После успешной установки проверьте текущую версию Java:
java -version
Посмотрите на вывод:
openjdk version "11.0.22" 2024-01-16
OpenJDK Runtime Environment (build 11.0.22+7-post-Ubuntu-0ubuntu222.04.1)
OpenJDK 64-Bit Server VM (build 11.0.22+7-post-Ubuntu-0ubuntu222.04.1, mixed mode, sharing)
Настройка паролевого-free SSH-логина
Цель установки и настройки SSH - сделать проще для Hadoop запускать скрипты, связанные с демоном удаленного управления. Эти скрипты требуют службы sshd.
При настройке сначала переключитесь на пользователя hadoop. Введите в терминале следующую команду для этого:
su hadoop
Если появляется запрос на ввод пароля, введите пароль, указанный при создании пользователя (hadoop).
После успешного переключения пользователя приглашение командной строки должно выглядеть, как показано выше. В последующих шагах будут выполняться операции от имени пользователя hadoop.
Далее сгенерируйте ключ для паролевого-free SSH-логина.
Под "паролевым-free" понимается изменение схемы аутентификации SSH от парольного логина к ключевому, чтобы каждый компонент Hadoop не приходилось вводить пароль при взаимодействии с другими компонентами, что позволяет избежать многих лишних операций.
Сначала перейдите в домашнюю директорию пользователя, а затем сгенерируйте RSA-ключ с помощью команды ssh-keygen.
Введите в терминале следующую команду:
cd /home/hadoop
ssh-keygen -t rsa
При появлении запросов о месте хранения ключа нажмите Enter, чтобы использовать значения по умолчанию.
The key's randomart image is:
+---[RSA 3072]----+
| ..+. |
| . =. o |
| .o o *. |
| o... + o |
| = +.S.. + |
| + + +++.. |
| . B.O+. |
| o +oXo*E |
| =.+==o. |
+----[SHA256]-----+
После генерации ключа в директории .ssh в домашней директории пользователя будет сгенерирован публичный ключ.
Сведения о конкретной операции показаны на рисунке ниже.
Затем введите следующую команду, чтобы добавить сгенерированный публичный ключ в запись аутентификации хоста. Предоставьте права записи файлу authorized_keys, иначе проверка не пройдет:
cat.ssh/id_rsa.pub >> .ssh/authorized_keys
chmod 600.ssh/authorized_keys
После успешного добавления попробуйте войти на localhost. Введите в терминале следующую команду:
ssh localhost
При первом входе будет предложено подтвердить отпечаток публичного ключа. Введите yes и подтвердите. Затем при повторном входе будет осуществляться пароль-free вход:
...
Welcome to Alibaba Cloud Elastic Compute Service!
To run a command as administrator (user "root"), use "sudo <command>".
See "man sudo_root" for details.
hadoop:~$
Необходимо ввести history -w или выйти из терминала, чтобы сохранить изменения и пройти проверочный скрипт.
Установка Hadoop
Теперь вы можете скачать пакет установки Hadoop. Официальный сайт предоставляет ссылку для скачивания последней версии Hadoop. Также вы можете использовать команду wget для прямого скачивания пакета в терминале.
Введите в терминале следующую команду для скачивания пакета:
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz
После завершения скачивания вы можете использовать команду tar для извлечения пакета:
tar zxvf hadoop-3.3.6.tar.gz
sudo mv hadoop-3.3.6 hadoop
sudo chown -R hadoop:hadoop /home/hadoop
Вы можете найти расположение JAVA_HOME, выполнив команду dirname $(dirname $(readlink -f $(which java))) в терминале.
dirname $(readlink -f $(which java))
Затем откройте файл .zshrc с помощью текстового редактора в терминале:
vim /home/hadoop/.bashrc
Добавьте в конец файла /home/hadoop/.bashrc следующее:
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
export HADOOP_HOME=/home/hadoop/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
Сохраните и выйдите из редактора vim. Затем введите команду source в терминале, чтобы активировать вновь добавленные переменные окружения:
source /home/hadoop/.bashrc
Проверьте установку, выполнив команду hadoop version в терминале.
hadoop@iZj6cgdabeniugz9ypibzxZ:~$ hadoop version
Hadoop 3.3.6
Source code repository https://github.com/apache/hadoop.git -r 1be78238728da9266a4f88195058f08fd012bf9c
Compiled by ubuntu on 2023-06-18T08:22Z
Compiled on platform linux-x86_64
Compiled with protoc 3.7.1
From source with checksum 5652179ad55f76cb287d9c633bb53bbd
This command was run using /home/hadoop/hadoop/share/hadoop/common/hadoop-common-3.3.6.jar
Конфигурация псевдо-распределенной схемы
В большинстве случаев Hadoop используется в кластерном окружении, то есть нужно развернуть Hadoop на нескольких узлах. В то же время Hadoop может также работать на одном узле в псевдо-распределенной схеме, имитируя многоузловые сценарии с помощью нескольких независимых Java-процессов. В начальном этапе обучения не нужно тратить много ресурсов на создание разных узлов. Поэтому в этом разделе и последующих главах будет в основном использоваться псевдо-распределенная схема для развертывания Hadoop "кластера".
Создание директорий
Для начала создайте директории namenode и datanode в домашней директории пользователя Hadoop. Выполните команду ниже для создания этих директорий:
rm -rf ~/hadoopdata
mkdir -p ~/hadoopdata/hdfs/{namenode,datanode}
Затем вам нужно изменить конфигурационные файлы Hadoop, чтобы он работал в псевдо-распределенной схеме.
Редактирование core-site.xml
Откройте файл core-site.xml с помощью текстового редактора в терминале:
vim /home/hadoop/hadoop/etc/hadoop/core-site.xml
В конфигурационном файле измените значение тега configuration на следующее содержимое:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
Конфигурационный параметр fs.defaultFS используется для указания расположения файловой системы, которую по умолчанию использует кластер:
Сохраните файл и выйдите из vim после редактирования.
Редактирование hdfs-site.xml
Откройте другой конфигурационный файл hdfs-site.xml:
vim /home/hadoop/hadoop/etc/hadoop/hdfs-site.xml
В конфигурационном файле измените значение тега configuration на следующее:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopdata/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopdata/hdfs/datanode</value>
</property>
</configuration>
Этот конфигурационный параметр используется для указания количества копий файлов в HDFS, по умолчанию это 3. Поскольку мы развернули его в псевдо-распределенном режиме на одном узле, его изменяем на 1:
Сохраните файл и выйдите из vim после редактирования.
Редактирование hadoop-env.sh
Далее отредактируйте файл hadoop-env.sh:
vim /home/hadoop/hadoop/etc/hadoop/hadoop-env.sh
Измените значение JAVA_HOME на фактическое расположение установленного JDK, то есть /usr/lib/jvm/java-11-openjdk-amd64.
Примечание: Вы можете использовать команду
echo $JAVA_HOMEдля проверки фактического расположения установленного JDK.
Сохраните файл и выйдите из редактора vim после редактирования.
Редактирование yarn-site.xml
Далее отредактируйте файл yarn-site.xml:
vim /home/hadoop/hadoop/etc/hadoop/yarn-site.xml
Добавьте следующее в тег configuration:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
Сохраните файл и выйдите из редактора vim после редактирования.
Редактирование mapred-site.xml
Наконец, вам нужно отредактировать файл mapred-site.xml.
Откройте файл с помощью редактора vim:
vim /home/hadoop/hadoop/etc/hadoop/mapred-site.xml
Аналогично добавьте следующее в тег configuration:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/home/hadoop/hadoop</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/home/hadoop/hadoop</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/home/hadoop/hadoop</value>
</property>
</configuration>
Сохраните файл и выйдите из редактора vim после редактирования.
Тест запуска Hadoop
Сначала откройте терминал Xfce на рабочем столе и переключитесь на пользователя Hadoop:
su -l hadoop
Инициализация HDFS заключается principalmente в форматировании:
/home/hadoop/hadoop/bin/hdfs namenode -format
Совет: перед форматированием нужно удалить директорию данных HDFS.
Если вы видите это сообщение, значит, форматирование прошло успешно:
2024-02-29 18:24:53,887 INFO common.Storage: Storage directory /home/hadoop/hadoopdata/hdfs/namenode has been successfully formatted.
Необходимо ввести history -w или выйти из терминала, чтобы сохранить историю и пройти проверочный скрипт.
Запустить HDFS
После завершения инициализации HDFS вы можете запустить демоны для NameNode и DataNode. После запуска Hadoop-приложения (например, задачи MapReduce) могут читать и записывать файлы в/из HDFS.
Запустите демон, введя в терминале следующую команду:
/home/hadoop/hadoop/sbin/start-dfs.sh
Посмотрите на вывод:
Starting namenodes on [localhost]
Starting datanodes
Starting secondary namenodes [iZj6cjditp4l7k0fylhhfbZ]
iZj6cjditp4l7k0fylhhfbZ: Warning: Permanently added 'izj6cjditp4l7k0fylhhfbz' (ED25519) to the list of known hosts.
Для подтверждения того, что Hadoop успешно запущен в псевдо-распределенной схеме, вы можете использовать инструмент просмотра процессов Java jps, чтобы увидеть, есть ли соответствующий процесс.
Введите в терминале следующую команду:
jps
Как показано на рисунке, если вы видите процессы NameNode, DataNode и SecondaryNameNode, это означает, что служба Hadoop работает исправно:
Просмотр файлов журнала и WebUI
Когда Hadoop не запускается или возникают ошибки при выполнении задачи (или иным образом), помимо информации, предоставляемой в терминале, просмотр журналов является наилучшим способом выявления проблемы. Большинство проблем можно обнаружить с помощью журналов связанных программ и найти причину и решение. Для начинающего специалиста в области больших данных умение анализировать логи настолько важно, как умение изучать вычислительный фреймворк, и его стоит относить с должным вниманием.
По умолчанию вывод журнала демона Hadoop находится в директории журнала (logs), расположенном в директории установки. Введите в терминале следующую команду, чтобы перейти в директорию журнала:
ls /home/hadoop/hadoop/logs
hadoop-hadoop-datanode-iZj6cjditp4l7k0fylhhfbZ.log
hadoop-hadoop-datanode-iZj6cjditp4l7k0fylhhfbZ.out
hadoop-hadoop-namenode-iZj6cjditp4l7k0fylhhfbZ.log
hadoop-hadoop-namenode-iZj6cjditp4l7k0fylhhfbZ.out
hadoop-hadoop-secondarynamenode-iZj6cjditp4l7k0fylhhfbZ.log
hadoop-hadoop-secondarynamenode-iZj6cjditp4l7k0fylhhfbZ.out
SecurityAuth-hadoop.audit
Вы можете использовать редактор vim для просмотра любого файла журнала.
После запуска HDFS внутренний веб-сервис также предоставляет веб-страницу, на которой отображается состояние кластера. Перейдите вверх виртуальной машины LabEx и нажмите на "Web 8088", чтобы открыть веб-страницу:
После открытия веб-страницы вы можете увидеть обзор кластера, состояние DataNode и т.д.:
Свободно нажимайте на меню в верхней части страницы, чтобы изучить подсказки и функции.
Необходимо ввести history -w или выйти из терминала, чтобы сохранить историю и пройти проверочный скрипт.
Тест загрузки файлов в HDFS
После запуска HDFS его можно рассматривать как файловую систему. Здесь для тестирования функции загрузки файлов вам нужно создать директорию (на каждом этапе на один уровень вглубь, до нужного уровня директории) и попробовать загрузить в HDFS некоторые файлы из системы Linux:
cd ~
/home/hadoop/hadoop/bin/hdfs dfs -mkdir /user
/home/hadoop/hadoop/bin/hdfs dfs -mkdir /user/hadoop
После успешного создания директории используйте команду hdfs dfs -put, чтобы загрузить файлы с локального диска (здесь случайно выбранные конфигурационные файлы Hadoop) в HDFS:
/home/hadoop/hadoop/bin/hdfs dfs -put /home/hadoop/hadoop/etc/hadoop /user/hadoop/input
Тестовые сценарии PI
Большинство приложений Hadoop, развернутых в реальных производственных средах и решающих реальные проблемы, основаны на модели программирования MapReduce, представленной WordCount. Поэтому WordCount можно использовать в качестве "HelloWorld" для знакомства с Hadoop, или вы можете добавить свои идеи для решения конкретных задач.
Запуск задачи
В конце предыдущего раздела мы загрузили некоторые конфигурационные файлы в HDFS в качестве примера. Теперь мы можем попробовать запустить тестовый сценарий для вычисления числа Пи и получить статистику частоты слов в этих файлах и вывести ее в соответствии с нашими правилами фильтрации.
Сначала запустите вычислительную службу YARN в терминале:
/home/hadoop/hadoop/sbin/start-yarn.sh
Затем введите следующую команду для запуска задачи:
/home/hadoop/hadoop/bin/hadoop jar /home/hadoop/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar pi 3 3
Посмотрите на результаты вывода:
Estimated value of Pi is 3.55555555555555555556
В параметрах выше есть три параметра, связанные с путями. Они следующие: расположение jar-пакета, расположение входного файла и место хранения результата вывода. При указании пути вы должны привыкать указывать абсолютный путь. Это поможет быстро локализовать проблемы и срочно выполнить работу.
После завершения задачи вы можете просмотреть результаты.
Закрытие службы HDFS
После вычислений, если нет других программ, которые используют файлы на HDFS, вы должны своевременно закрыть демон HDFS.
В качестве пользователя распределенных кластеров и связанных с ними вычислительных фреймворков вы должны привыкать активно проверять состояние связанной аппаратуры и программного обеспечения каждый раз, когда это касается открытия и закрытия кластера, установки аппаратуры и программного обеспечения или любого вида обновления.
В терминале используйте следующую команду для закрытия демонов HDFS и YARN:
/home/hadoop/hadoop/sbin/stop-yarn.sh
/home/hadoop/hadoop/sbin/stop-dfs.sh
Необходимо ввести history -w или выйти из терминала, чтобы сохранить историю и пройти проверочный скрипт.
Резюме
В этом практическом занятии были представлены архитектура Hadoop, методы установки и развертывания в одиночном и псевдо-распределенном режимах, а также запуск WordCount для базового тестирования.
Вот основные аспекты этого практического занятия:
- Архитектура Hadoop
- Основные модули Hadoop
- Как использовать Hadoop в одиночном режиме
- Развертывание Hadoop в псевдо-распределенном режиме
- Основные применения HDFS
- Тестовый сценарий WordCount
В целом, Hadoop - это вычислительный и хранилищеовый фреймворк, широко используемый в области больших данных. Его возможности требуют дальнейшего исследования. Будьте вежливы при обращении к техническим материалам и продолжайте изучать последующие fs.


