
Введение
В этом практическом занятии мы продолжим говорить о HDFS, одной из основных компонент Hadoop. Изучение этого практического занятия поможет вам понять принципы работы и базовые операции HDFS, а также способы доступа к WebHDFS в архитектуре программного обеспечения Hadoop.
Введение в HDFS
Как показывает его название, HDFS (Hadoop Distributed File System) - это компонент распределенного хранилища в рамках Hadoop, обладающий устойчивостью к ошибкам и масштабируемостью.
HDFS может использоваться в составе кластера Hadoop или в качестве автономного универсального распределенного файловой системы. Например, HBase построен на основе HDFS, а Spark также может использовать HDFS в качестве одного из источников данных. Изучение архитектуры и основных операций HDFS будет очень полезно для настройки, улучшения и диагностики конкретных кластеров.
HDFS - это распределенное хранилище, используемое приложениями Hadoop, источник и назначение данных. Кластеры HDFS в основном состоят из NameNodes, которые управляют метаданными файловой системы, и DataNodes, которые хранят фактические данные. Архитектура изображена на следующем рисунке, который показывает модели взаимодействия между NameNodes, DataNodes и Clients:
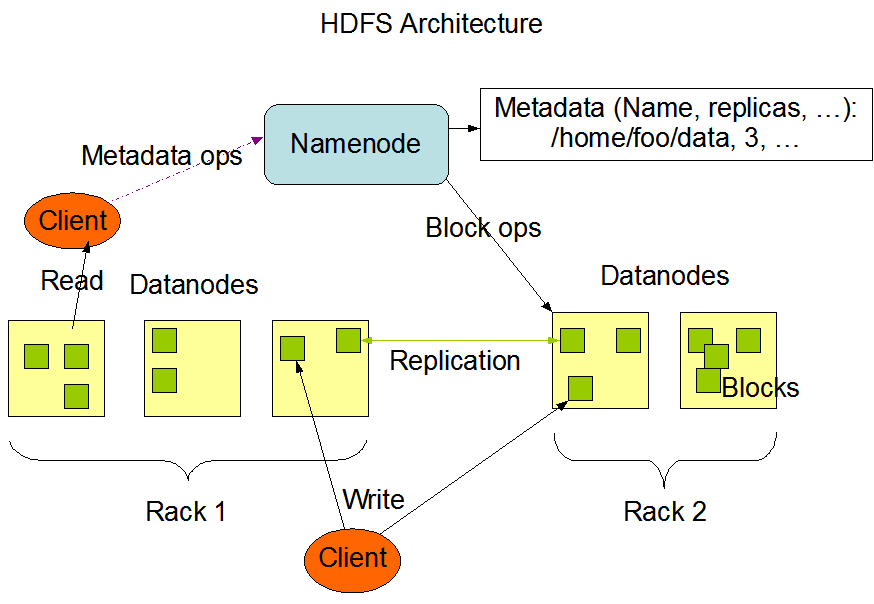 Этот рисунок взят с официального сайта Hadoop.
Этот рисунок взят с официального сайта Hadoop.
Обзор введения в HDFS:
- Обзор HDFS: HDFS (Hadoop Distributed File System) - это распределенный компонент хранилища с устойчивостью к ошибкам и масштабируемостью в рамках Hadoop.
- Архитектура: Кластеры HDFS состоят из NameNodes для управления метаданными и DataNodes для хранения фактических данных. Архитектура имеет модель Master/Slave с одним NameNode и несколькими DataNodes.
- Хранение файлов: Файлы в HDFS разделяются на блоки, хранящиеся на DataNodes, при этом размер по умолчанию блока составляет 64 МБ.
- Операции: NameNode обрабатывает операции пространства имен файловой системы, в то время как DataNodes управляют запросами на чтение и запись от клиентов.
- Взаимодействие: Клиенты общаются с NameNode для получения метаданных и напрямую взаимодействуют с DataNodes для получения данных файлов.
- Развертывание: Обычно на одном отдельном узле запускается NameNode, в то время как на каждом другом узле запускается экземпляр DataNode. HDFS построен на Java, что обеспечивает переносимость между различными средами.
Понимание этих ключевых моментов о HDFS поможет эффективно настраивать, оптимизировать и диагностировать кластеры Hadoop.
Обзор файловой системы
Пространство имен файловой системы
- Иерархическое оформление: И HDFS, и традиционные файловые системы Linux поддерживают иерархическое оформление файлов с древовидной структурой каталогов, позволяя пользователям и приложениям создавать каталоги и хранить файлы.
- Доступ и операции: Пользователи могут взаимодействовать с HDFS с помощью различных интерфейсов доступа, таких как командные строки и API, что позволяет выполнять операции, такие как создание, удаление, перемещение и переименование файлов.
- Поддержка функций: Начиная с версии 3.3.6, HDFS не реализует квоты пользователей, права доступа, жесткие ссылки или мягкие ссылки. Однако будущие выпуски могут поддерживать эти функции, так как архитектура позволяет их реализовать.
- Управление NameNode: NameNode в HDFS обрабатывает все изменения в пространстве имен файловой системы и свойствах, включая управление коэффициентом репликации файлов, который задает количество копий файла, которые должны быть сохранены в HDFS.
Копирование данных
В начале разработки HDFS был проектирован для хранения очень больших файлов в большом кластере в межузловом, очень надежной манере. Как уже упоминалось ранее, HDFS хранит файлы в блоках. Конкретно, он хранит каждый файл в виде последовательности блоков. За исключением последнего блока, все блоки в файле имеют одинаковый размер.
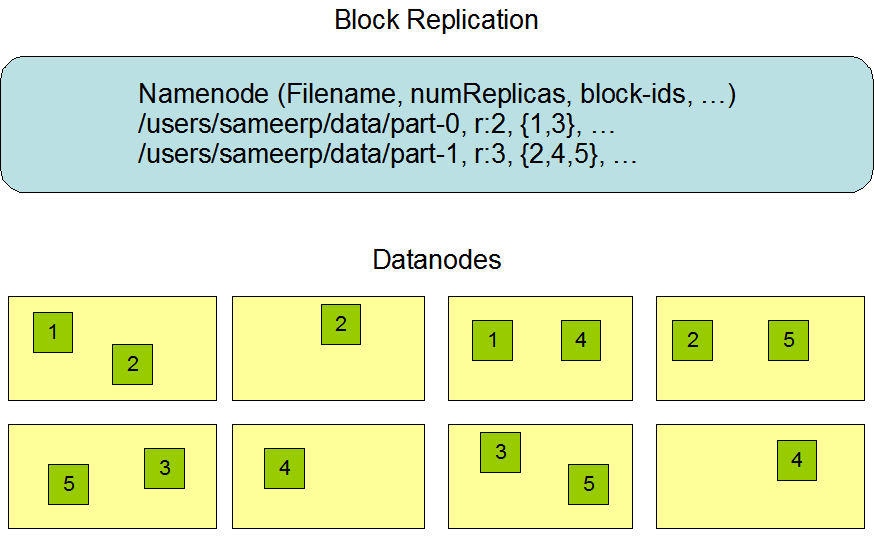 Этот рисунок взят с официального сайта Hadoop.
Этот рисунок взят с официального сайта Hadoop.
Репликация данных и высокая доступность в HDFS:
- Репликация данных: В HDFS файлы делятся на блоки, которые реплицируются на нескольких DataNodes для обеспечения устойчивости к ошибкам. Коэффициент репликации можно указать при создании или изменении файла, при этом каждый файл имеет единственного писателя в любое конкретное время.
- Управление репликацией: NameNode управляет тем, как копируются блоки файлов, получая от DataNodes отчеты о состоянии сердцебиения и статусе блоков. DataNodes сообщают о своем рабочем состоянии с помощью сердцебиений, а отчеты о статусе блоков содержат информацию о всех блоках, хранящихся на DataNode.
- Высокая доступность: HDFS обеспечивает определенную степень высокой доступности путем внутреннего восстановления потерянных копий файлов из других частей кластера в случае поломки диска или других сбоев. Эта механика помогает поддерживать целостность и надежность данных в распределенной системе хранения.
Сохранение метаданных файловой системы
- Управление пространством имен: Пространство имен HDFS, содержащее метаданные файловой системы, хранится в NameNode. Каждая изменение в метаданных файловой системы записывается в EditLog, который сохраняет транзакции, такие как создание файлов. EditLog хранится в локальной файловой системе.
- FsImage: Весь пространство имен файловой системы, включая сопоставление блоков с файлами и атрибуты, хранится в файле с именем FsImage. Этот файл также сохраняется в локальной файловой системе, где расположен NameNode.
- Процесс чекпоинта: Процесс чекпоинта заключается в чтении FsImage и EditLog с диска при запуске NameNode. Все транзакции в EditLog применяются к FsImage в памяти, который затем сохраняется обратно на диск для сохранения. После этого процесса старый EditLog можно сократить. В текущей версии (3.3.6) чекпоинты происходят только при запуске NameNode, но будущие версии могут ввести периодические чекпоинты для повышения надежности и согласованности данных.
Другие функции
- Основание TCP/IP: Все протоколы коммуникации в HDFS построены поверх протокольной совокупности TCP/IP, обеспечивая надежный обмен данными между узлами в распределенной файловой системе.
- Протокол клиента: Общение между клиентом и NameNode облегчается с помощью Протокола клиента. Клиент инициализирует соединение с конфигурируемыми TCP-портами на NameNode для взаимодействия с метаданными файловой системы.
- Протокол DataNode: Общение между DataNodes и NameNode основано на Протоколе DataNode. DataNodes общаются с NameNode для отчета о своем статусе, отправки сигналов сердцебиения и передачи блоков данных в составе распределенной системы хранения.
- Удаленный вызов процедуры (RPC): Как Протокол клиента, так и Протокол DataNode абстрагируются с использованием механизмов удаленного вызова процедуры (RPC). NameNode отвечает на RPC-запросы, инициализируемые DataNodes или клиентами, играя пассивную роль в процессе коммуникации.
Ниже приведены некоторые материалы для дополнительного чтения:
Переключиться на пользователя
Прежде чем писать код задачи, вы должны сначала переключиться на пользователя hadoop. Дважды щелкните, чтобы открыть терминал Xfce на вашем рабочем столе и введите следующую команду. Пароль пользователя hadoop - hadoop; его потребуется при переключении пользователей:
su - hadoop
labex:~/ $ su - hadoop
hadoop:~$
Совет: пароль пользователя hadoop - hadoop
Инициализация HDFS
Надо инициализировать Namenode перед первым использованием HDFS. Эта операция может быть сравнена с форматированием диска, поэтому используйте эту команду с осторожностью, если вы храните данные на HDFS.
В противном случае перезапустите эксперимент в этом разделе. Используйте "Стандартную среду" и инициализируйте HDFS с помощью следующей команды:
/home/hadoop/hadoop/bin/hdfs namenode -format
Совет: Команда выше отформатирует файловую систему HDFS, вам нужно удалить директорию данных HDFS перед запуском команды.
Поэтому вам нужно остановить сервисы, связанные с Hadoop, и удалить данные Hadoop.
stop-all.sh
rm -rf ~/hadoopdata
Когда вы увидите следующее сообщение, инициализация будет завершена:
2024-03-01 11:16:10,439 INFO common.Storage: Storage directory /home/hadoop/hadoopdata/hdfs/namenode has been successfully formatted.
Импорт файлов
Поскольку HDFS - это распределенная файловая система (distributed storage system), построенная поверх локальных дисков, вам нужно импортировать данные в нее перед использованием HDFS.
Первый и наиболее удобный способ подготовить некоторые файлы - использовать в качестве примера конфигурационный файл Hadoop.
Сначала вам нужно запустить демон HDFS:
/home/hadoop/hadoop/sbin/start-dfs.sh
Просмотреть службы:
hadoop:~$ jps
8341 SecondaryNameNode
7962 NameNode
8474 Jps
8107 DataNode
Создать директорию и скопировать данные, введя следующую команду в терминале:
cd /home/hadoop
mkdir sample_data
cp -r /home/hadoop/hadoop/etc/hadoop/* sample_data/
Просмотреть содержимое директории:
hadoop:~$ ls /home/hadoop/sample_data/
capacity-scheduler.xml kms-log4j.properties
configuration.xsl kms-site.xml
...
Любая операция над HDFS начинается с hdfs dfs и дополняется соответствующими параметрами операции. Наиболее часто используемый параметр - put, который используется следующим образом и может быть введен в терминале:
/home/hadoop/hadoop/bin/hdfs dfs -put /home/hadoop/sample_data/hadoop-policy.xml /policy.xml
Просмотреть содержимое директории:
hadoop:~$ hdfs dfs -ls /policy.xml
-rw-r--r-- 1 hadoop supergroup 11765 2024-03-01 11:37 /policy.xml
Последний /policy.xml в команде означает, что имя файла, хранящегося в HDFS, - policy.xml, а путь - / (корневая директория). Если вы хотите продолжить использовать предыдущее имя файла, вы можете напрямую указать путь /.
Если вам нужно загрузить несколько файлов, вы можете последовательно указать путь к файлам локальной директории и завершить указанием целевого пути хранения в HDFS:
/home/hadoop/hadoop/bin/hdfs dfs -mkdir -p /user/hadoop
/home/hadoop/hadoop/bin/hdfs dfs -put /home/hadoop/sample_data/httpfs-env.sh /home/hadoop/sample_data/mapred-env.sh /user/hadoop
Просмотреть содержимое директории:
hadoop:~$ hdfs dfs -ls /user/hadoop
Found 2 items
-rw-r--r-- 1 hadoop supergroup 1484 2024-03-01 11:42 /user/hadoop/httpfs-env.sh
-rw-r--r-- 1 hadoop supergroup 1764 2024-03-01 11:42 /user/hadoop/mapred-env.sh
При указании параметров, связанных с путями, правила такие же, как в Linux-системе. Вы можете использовать подстановочные знаки (например, *.sh), чтобы упростить операцию.
Операции с файлами
Аналогично вы можете использовать параметр -ls, чтобы вывести список файлов в указанной директории:
/home/hadoop/hadoop/bin/hdfs dfs -ls /user/hadoop
Список файлов, отображаемых здесь, может отличаться в зависимости от экспериментальной среды.
Если вам нужно просмотреть содержимое файла, вы можете использовать параметр cat. Самым простым способом является прямой указание пути к файлу на HDFS. Если вам нужно сравнить локальную директорию с файлами на HDFS, вы можете указать их пути отдельно. Однако следует отметить, что локальная директория должна начинаться с индикатора file://, за которым следует путь к файлу (например, /home/hadoop/.bashrc, не забывайте / в начале). В противном случае любой путь, указанный здесь, по умолчанию будет восприниматься как путь на HDFS:
/home/hadoop/hadoop/bin/hdfs dfs -cat file:///home/hadoop/.bashrc /user/hadoop/mapred-env.sh
Вывод будет таким:
hadoop:~$ hdfs dfs -cat file:///home/hadoop/.bashrc /user/hadoop/mapred-env.sh
## ~/.bashrc: executed by bash(1) for non-login shells.
## see /usr/share/doc/bash/examples/startup-files (in the package bash-doc)
## for examples
## If not running interactively, don't do anything
case $- in
...
Если вам нужно скопировать файл в другой путь, вы можете использовать параметр cp:
/home/hadoop/hadoop/bin/hdfs dfs -cp /user/hadoop/mapred-env.sh /user/hadoop/copied_file.txt
Аналогично, если вам нужно переместить файл, используйте параметр mv. Это в основном то же самое, что и формат команды для файловой системы Linux:
/home/hadoop/hadoop/bin/hdfs dfs -mv /user/hadoop/mapred-env.sh /moved_file.txt
Используйте параметр lsr, чтобы вывести содержимое текущей директории, включая содержимое поддиректорий. Вывод будет таким:
hdfs dfs -lsr /
Если вы хотите добавить некоторое новое содержимое в файл на HDFS, вы можете использовать параметр appendToFile. При этом при указании пути к локальному файлу, который нужно добавить, вы можете указать несколько файлов. Последним параметром будет объект, в который нужно добавить содержимое. Файл должен существовать на HDFS, иначе будет выдано сообщение об ошибке:
echo 1 >> a.txt
echo 2 >> b.txt
/home/hadoop/hadoop/bin/hdfs dfs -appendToFile a.txt b.txt /user/hadoop/mapred-env.sh
Вы можете использовать параметр tail, чтобы просмотреть содержимое конца файла (последнюю часть файла) и подтвердить, был ли добавлен новый текст успешно:
/home/hadoop/hadoop/bin/hdfs dfs -tail /user/hadoop/mapred-env.sh
Посмотрите на вывод команды tail:
hadoop:~$ echo 1 >> a.txt
echo 2 >> b.txt
hdfs dfs -appendToFile a.txt b.txt /user/hadoop/mapred-env.sh
hadoop:~$ hdfs dfs -tail /user/hadoop/mapred-env.sh
1
2
Если вам нужно удалить файл или директорию, используйте параметр rm. Этот параметр также может быть дополнен -r и -f, которые имеют те же значения, что и для команды rm файловой системы Linux:
/home/hadoop/hadoop/bin/hdfs dfs -rm /moved_file.txt
Содержимое файла moved_file.txt будет удалено, и команда вернет следующий вывод 'Deleted /moved_file.txt'
Операции с директориями
В предыдущем материале мы узнали, как создавать директорию в HDFS. Фактически, если вам нужно создать сразу несколько директорий, вы можете напрямую указать пути к нескольким директориям в качестве параметров. Параметр -p означает, что родительская директория будет создана автоматически, если она не существует:
/home/hadoop/hadoop/bin/hdfs dfs -mkdir -p /user/hadoop/dir1 /user/hadoop/dir2/sub_dir1
Если вы хотите узнать, сколько места занимает определенный файл или директория, вы можете использовать параметр du:
/home/hadoop/hadoop/bin/hdfs dfs -du /user/hadoop/
Вывод будет таким:
hadoop:~$ hdfs dfs -du /user/hadoop/
1764 1764 /user/hadoop/copied_file.txt
0 0 /user/hadoop/dir1
0 0 /user/hadoop/dir2
1484 1484 /user/hadoop/httpfs-env.sh
4 4 /user/hadoop/mapred-env.sh
Экспорт файлов
В предыдущем разделе мы в основном рассмотрели операции с файлами и директориями в HDFS. Если приложение, такое как MapReduce, выполняет вычисления и генерирует файл с результатами, вы можете использовать параметр get, чтобы экспортировать его в локальную директорию системы Linux.
Первый параметр пути здесь относится к пути в HDFS, а последний путь - к пути, сохраненному в локальной директории:
/home/hadoop/hadoop/bin/hdfs dfs -get /user/hadoop/mapred-env.sh /home/hadoop/exported_file.txt
Если экспорт завершен успешно, вы можете найти файл в своей локальной директории:
cd ~
ls
Вывод будет таким:
a.txt b.txt exported_file.txt hadoop hadoopdata sample_data
Операции с веб-интерфейсом Hadoop
Веб-интерфейс управления
Каждый NameNode или DataNode запускает веб-сервер внутри себя, который отображает базовую информацию, такую как текущее состояние кластера. В стандартной конфигурации домашняя страница NameNode - это http://localhost:9870/. Она показывает основные статистические данные для DataNodes и кластера.
Откройте веб-браузер и введите в адресной строке следующее:
http://localhost:9870/
В разделе Summary вы можете увидеть количество активных узлов DataNode в текущем "кластере":
Веб-интерфейс также можно использовать для просмотра директорий и файлов внутри HDFS. В меню на верхней панели нажмите на ссылку "Browse the file system" в разделе "Utilities":
Закрыть кластер Hadoop
Теперь мы закончили с описанием некоторых основных операций WebHDFS. Более подробные инструкции можно найти в документации по WebHDFS. Этот практикум завершен. По привычке мы все еще должны остановить Hadoop-кластер:
/home/hadoop/hadoop/sbin/stop-yarn.sh
/home/hadoop/hadoop/sbin/stop-dfs.sh
hadoop:~$ jps
11633 Jps
Резюме
В этом практикуме мы рассмотрели архитектуру HDFS. Также мы узнали основные команды для работы с HDFS из командной строки, а затем перешли к веб-интерфейсу доступа к HDFS, который поможет HDFS функционировать как реальное хранилище для внешних приложений.
В этом практикуме не рассматриваются сценарии удаления файлов в WebHDFS. Вы можете самостоятельно изучить документацию. В официальной документации скрыты многие дополнительные функции, поэтому обязательно оставайтесь открыты для чтения документации.
Ниже приведены материалы для дополнительного чтения:


