
はじめに
Hadoop 2.0 以降のバージョンでは、YARN の新しいリソース管理パターンが導入され、クラスタの利用率、統一的なリソース管理、データ共有の面で便利になっています。Hadoop 疑似分散クラスタを構築する基盤に基づいて、このセクションでは、YARN フレームワークのアーキテクチャ、動作原理、構成、および開発とモニタリング技術を学ぶことができます。
この実験には、ある程度の Java プログラミングの基礎が必要です。
文書内のサンプルコードはすべて自分で入力してください。できるだけコピー&ペーストしないでください。このようにすることで、コードに慣れることができます。問題がある場合は、文書を注意深く確認するか、フォーラムで助けを求めて交流してください。
YARN のアーキテクチャとコンポーネント
Hadoop 0.23 で MapReduce 2.0 (MRv2) の一部として導入された YARN は、Hadoop クラスタにおけるリソース管理とジョブスケジューリングを革新的に変えました。
- JobTracker の分解:
MRv2は、JobTrackerの機能を個別のデーモンに分解します。リソース管理用のResourceManagerと、ジョブスケジューリングとモニタリング用のApplicationMasterです。 - グローバルな ResourceManager:各アプリケーションには対応する
ApplicationMasterがあり、これは MapReduce ジョブまたはジョブを表す DAG であることができます。 - データ計算フレームワーク:
ResourceManager、Slave、およびNodeManagerがフレームワークを形成し、ResourceManager がすべてのアプリケーション リソースを管理します。 - ResourceManager のコンポーネント:
Schedulerは、容量やキューなどの制約条件に基づいてリソースを割り当てます。一方、ApplicationsManagerはジョブの提出と ApplicationMaster の実行を処理します。 - リソース割り当て:リソース要件は、メモリ、CPU、ディスク、ネットワークなどの要素を持つリソースコンテナを使用して定義されます。
- NodeManager の役割:NodeManager はコンテナのリソース使用状況を監視し、ResourceManager と Scheduler に報告します。
- ApplicationMaster のタスク:ApplicationMaster は Scheduler とリソースコンテナを交渉し、状態を追跡し、進捗状況を監視します。
次の図はその関係を示しています。

YARN は、以前のバージョンとの API 互換性を保証し、MapReduce タスクを実行するための円滑な移行を可能にします。YARN のアーキテクチャとコンポーネントを理解することは、Hadoop クラスタにおける効率的なリソース管理とジョブスケジューリングに不可欠です。
Hadoop デーモンの起動
関連する構成パラメータや YARN アプリケーションの開発技術を学ぶ前に、Hadoop デーモンを起動しておく必要があります。これにより、いつでも使用できるようになります。
まず、デスクトップ上の Xfce ターミナルをダブルクリックして開き、次のコマンドを入力して hadoop ユーザーに切り替えます。
su - hadoop
ヒント:パスワードは hadoop ユーザーの 'hadoop' です。
切り替えが完了したら、HDFS や YARN フレームワークを含む Hadoop 関連のデーモンを起動できます。
ターミナルに次のコマンドを入力してデーモンを起動してください。
/home/hadoop/hadoop/sbin/start-dfs.sh
/home/hadoop/hadoop/sbin/start-yarn.sh
起動が完了した後は、関連するデーモンが実行されているかどうかを確認するために jps コマンドを使用できます。
hadoop:~$ jps
3378 NodeManager
3028 SecondaryNameNode
3717 Jps
2791 DataNode
2648 NameNode
3240 ResourceManager
設定ファイルの準備
このセクションでは、Hadoop の主な構成ファイルの 1 つである yarn-site.xml について学び、このファイルで YARN クラスタに対してどのような設定ができるかを見ていきます。
構成ファイルの変更を誤って使うことを防ぐために、Hadoop の構成ファイルを別のディレクトリにコピーしてから開くのが最善です。
これを行うには、ターミナルに次のコマンドを入力して構成ファイル用の新しいディレクトリを作成します。
mkdir /home/hadoop/hadoop_conf
次に、インストールディレクトリから YARN の主な構成ファイル yarn-site.xml を新しく作成したディレクトリにコピーします。
ターミナルに次のコマンドを入力して操作を行います。
cp /home/hadoop/hadoop/etc/hadoop/yarn-site.xml /home/hadoop/hadoop_conf/yarn-site.xml
その後、vim エディタを使ってファイルを開いて内容を表示します。
vim /home/hadoop/hadoop_conf/yarn-site.xml
設定ファイルはどのように機能するか
YARN フレームワークには 2 つの重要な役割があることを知っています。ResourceManager と NodeManager です。したがって、このファイル内の各構成項目は、上記の 2 つのコンポーネントの設定になっています。
このファイルで設定できる構成項目はたくさんありますが、デフォルトでは、このファイルにはカスタム構成項目は含まれていません。たとえば、今開いているファイルには、以前に疑似分散 Hadoop クラスタを構成した際に指定された aux-services という属性だけがあり、以下の図のようになっています。
hadoop:~$ cat /home/hadoop/hadoop/etc/hadoop/mapred-site.xml
...
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
この構成項目は、NodeManager で実行する必要のある依存サービスを設定するために使用されます。指定した構成値は mapreduce_shuffle で、MapReduce プログラムのデフォルト値を YARN 上で実行する必要があることを示しています。
そのファイルに記載されていない構成項目は機能しないのでしょうか。そうではありません。構成パラメータがファイルに明示的に指定されていない場合、Hadoop の YARN フレームワークは内部ファイルに格納されているデフォルト値を読み取ります。yarn-site.xml ファイルに明示的に指定されたすべての構成項目は、デフォルト値を上書きします。これは、Hadoop システムがさまざまな使用シナリオに対応するための有効な方法です。
ResourceManager の構成項目
yarn-site.xml ファイル内の ResourceManager の設定を理解し、正しく構成することは、Hadoop クラスタにおける効率的なリソース管理とジョブ実行に不可欠です。以下は、ResourceManager に関連する主要な構成項目の概要です。
- **
yarn.resourcemanager.address**:クライアントに対してアプリケーションの提出とアプリケーションの終了を行うためのアドレスを公開します。デフォルト ポートは 8032 です。 - **
yarn.resourcemanager.scheduler.address**:ApplicationMaster に対してリソースの要求と解放を行うためのアドレスを公開します。デフォルト ポートは 8030 です。 - **
yarn.resourcemanager.resource-tracker.address**:NodeManager に対してハートビートを送信し、タスクを取得するためのアドレスを公開します。デフォルト ポートは 8031 です。 - **
yarn.resourcemanager.admin.address**:管理者に対して管理コマンドを実行するためのアドレスを公開します。デフォルト ポートは 8033 です。 - **
yarn.resourcemanager.webapp.address**:クラスタ情報を表示するための WebUI アドレスです。デフォルト ポートは 8088 です。 - **
yarn.resourcemanager.scheduler.class**:スケジューラの主クラス名を指定します (たとえば、FIFO、CapacityScheduler、FairScheduler)。 - スレッド構成:
yarn.resourcemanager.resource-tracker.client.thread-countyarn.resourcemanager.scheduler.client.thread-count
- リソース割り当て:
yarn.scheduler.minimum-allocation-mbyarn.scheduler.maximum-allocation-mbyarn.scheduler.minimum-allocation-vcoresyarn.scheduler.maximum-allocation-vcores
- NodeManager 管理:
yarn.resourcemanager.nodes.exclude-pathyarn.resourcemanager.nodes.include-path
- ハートビート構成:
yarn.resourcemanager.nodemanagers.heartbeat-interval-ms
これらのパラメータを構成することで、Hadoop クラスタにおける ResourceManager の動作、リソース割り当て、スレッド処理、NodeManager 管理、およびハートビート間隔を微調整することができます。これらの構成項目を理解することで、問題の防止やクラスタの円滑な動作を保証することができます。
NodeManager の構成項目
yarn-site.xml ファイル内の NodeManager の設定を構成することは、Hadoop クラスタ内で効率的にリソースとタスクを管理するために重要です。以下は、NodeManager に関連する主要な構成項目の概要です。
- **
yarn.nodemanager.resource.memory-mb**:NodeManager に利用可能な物理メモリの合計量を指定します。この値は、YARN の実行中は一定のままです。 - **
yarn.nodemanager.vmem-pmem-ratio**:仮想メモリと物理メモリの割り当て比率を設定します。デフォルトの比率は2.1です。 - **
yarn.nodemanager.resource.cpu-vcores**:NodeManager に利用可能な仮想 CPU の総数を定義します。デフォルト値は8です。 - **
yarn.nodemanager.local-dirs**:NodeManager 上で中間結果を保存するためのパスで、複数のディレクトリの設定が可能です。 - **
yarn.nodemanager.log-dirs**:NodeManager のログディレクトリのパスで、複数のディレクトリの設定が可能です。 - **
yarn.nodemanager.log.retain-seconds**:NodeManager のログの最大保持時間で、デフォルトは 10800 秒 (3 時間) です。
これらのパラメータを構成することで、Hadoop クラスタにおける NodeManager によるリソース割り当て、メモリ管理、ディレクトリ パス、およびログ保持設定を微調整することができます。これらの構成項目を理解することで、クラスタ内の円滑な動作と効率的なタスク実行を保証することができます。
構成項目の照会とデフォルトの参照
YARN やその他の一般的な Hadoop コンポーネントに利用可能なすべての構成項目を調べるには、Apache Hadoop が提供するデフォルトの構成ファイルを参照することができます。以下は、デフォルトの構成にアクセスするためのリンクです。
YARN の構成項目:
一般的な構成ファイル:
- core-default.xml (core-site.xml)
- hdfs-default.xml (hdfs-site.xml)
- mapred-default.xml (mapred-site.xml)
これらのデフォルトの構成を調べることで、各構成項目とその目的の詳細な説明が得られ、Hadoop アーキテクチャの設計における各パラメータの役割を理解することができます。
構成を確認した後は、vim エディタを閉じて、Hadoop の構成設定の探索を終了します。
プロジェクト ディレクトリとファイルの作成
公式の YARN インスタンス アプリケーションを模倣することで、YARN アプリケーションの開発プロセスを学びましょう。
まず、プロジェクト ディレクトリを作成します。ターミナルに次のコマンドを入力してディレクトリを作成します。
mkdir /home/hadoop/yarn_app
次に、プロジェクト内に 2 つのソースコード ファイルを作成します。
最初のファイルは Client.java です。ターミナルで touch コマンドを使ってファイルを作成します。
touch /home/hadoop/yarn_app/Client.java
次に ApplicationMaster.java ファイルを作成します。
touch /home/hadoop/yarn_app/ApplicationMaster.java
hadoop:~$ tree /home/hadoop/yarn_app/
/home/hadoop/yarn_app/
├── ApplicationMaster.java
└── Client.java
0 directories, 2 files
クライアント コードの記述
クライアント のコードを記述することで、YARN フレームワークの下で クライアント を開発する際に必要な API とその役割を理解することができます。
コードの内容は少々長いです。1 行ずつ読むよりも効率的な方法は、先ほど作成したソースコード ファイルに 1 行ずつ入力することです。
まず、vim エディタ (または他のテキスト エディタ) を使って先ほど作成した Client.java ファイルを開きます。
vim /home/hadoop/yarn_app/Client.java
次に、プログラムの本体を追加して、クラス名とクラスのパッケージ名を示します。
package com.labex.yarn.app;
public class Client {
public static void main(String[] args){
//TODO: Edit code here.
}
}
以下のコードはセグメント形式です。記述する際は、以下のコードを Client クラス内 (つまり、コメント //TODO: Edit your code here があるコード ブロック内) に記述してください。
クライアントが最初に行う必要があることは、YarnClient オブジェクトを作成して初期化し、その後に起動することです。
YarnClient yarnClient = YarnClient.createYarnClient();
yarnClient.init(conf);
yarnClient.start();
Client を作成した後、YARN アプリケーションのオブジェクトとそのアプリケーション ID を作成する必要があります。
YarnClientApplication app = yarnClient.createApplication();
GetNewApplicationResponse appResponse = app.getNewApplicationResponse();
appResponse オブジェクトには、クラスタの情報が含まれています。たとえば、クラスタの最小と最大のリソース能力です。この情報は、ApplicationMaster が関連するコンテナを起動する際にパラメータを適切に設定できるようにするために必要です。
Client の主なタスクの 1 つは、ApplicationSubmissionContext を設定することです。これは、RM が AM を起動するために必要なすべての情報を定義します。
一般的に、Client はコンテキスト内で以下のことを設定する必要があります。
- アプリケーション情報:アプリケーションの ID と名前を含みます。
- キューと優先度情報:アプリケーションの提出に対するキューと割り当てられた優先度を含みます。
- ユーザー:アプリケーションを提出したユーザーが誰であるかを示します。
- ContainerLaunchContext:AM を起動して実行するコンテナの情報を定義します。アプリケーションを実行するために必要なすべての必要情報が
ContainerLaunchContextに定義されており、ローカル リソース (バイナリ ファイル、jar ファイルなど)、環境変数 (CLASSPATHなど)、実行するコマンド、およびセキュア トークン (RECT) が含まれます。
// Set the application to submit the context
ApplicationSubmissionContext appContext = app.getApplicationSubmissionContext();
ApplicationId appId = appContext.getApplicationId();
appContext.setKeepContainersAcrossApplicationAttempts(keepContainers);
appContext.setApplicationName(appName);
// The following code is used to set the local resources of ApplicationMaster
/ / Local resources need to be local files or compressed packages etc.
// In this scenario, the jar package is in the form of a file as one of AM's local resources.
Map<String, LocalResource> localResources = new HashMap<String, LocalResource>();
LOG.info("Copy AppMaster jar from local filesystem and add to local environment.");
// Copy the jar package of ApplicationMaster into the file system
FileSystem fs = FileSystem.get(conf);
// Create a local resource that points to the jar package path
addToLocalResources(fs, appMasterJar, appMasterJarPath, appId.toString(), localResources, null);
// Set the parameters of logs, you can skip it
if (!log4jPropFile.isEmpty()) {
addToLocalResources(fs, log4jPropFile, log4jPath, appId.toString(), localResources, null);
}
// The shell script will be available in the container that will eventually execute it
// So first copy it to the file system so that the YARN framework can find it
// You don't need to set it to the local resource of AM here because the latter doesn't need it
String hdfsShellScriptLocation = "";
long hdfsShellScriptLen = 0;
long hdfsShellScriptTimestamp = 0;
if (!shellScriptPath.isEmpty()) {
Path shellSrc = new Path(shellScriptPath);
String shellPathSuffix = appName + "/" + appId.toString() + "/" + SCRIPT_PATH;
Path shellDst = new Path(fs.getHomeDirectory(), shellPathSuffix);
fs.copyFromLocalFile(false, true, shellSrc, shellDst);
hdfsShellScriptLocation = shellDst.toUri().toString();
FileStatus shellFileStatus = fs.getFileStatus(shellDst);
hdfsShellScriptLen = shellFileStatus.getLen();
hdfsShellScriptTimestamp = shellFileStatus.getModificationTime();
}
if (!shellCommand.isEmpty()) {
addToLocalResources(fs, null, shellCommandPath, appId.toString(),
localResources, shellCommand);
}
if (shellArgs.length > 0) {
addToLocalResources(fs, null, shellArgsPath, appId.toString(),
localResources, StringUtils.join(shellArgs, " "));
}
// Set the environment parameters that AM requires
LOG.info("Set the environment for the application master");
Map<String, String> env = new HashMap<String, String>();
// Add the path to the shell script to the environment variable
// AM will create the correct local resource for the final container accordingly
// and the above container will execute the shell script at startup
env.put(DSConstants.DISTRIBUTEDSHELLSCRIPTLOCATION, hdfsShellScriptLocation);
env.put(DSConstants.DISTRIBUTEDSHELLSCRIPTTIMESTAMP, Long.toString(hdfsShellScriptTimestamp));
env.put(DSConstants.DISTRIBUTEDSHELLSCRIPTLEN, Long.toString(hdfsShellScriptLen));
// Add the path to AppMaster.jar to the classpath
// Note that there is no need to provide a Hadoop-related classpath here, as we have an annotation in the external configuration file.
// The following code adds all the classpath-related path settings required by AM to the current directory
StringBuilder classPathEnv = new StringBuilder(Environment.CLASSPATH.$$())
.append(ApplicationConstants.CLASS_PATH_SEPARATOR).append("./*");
for (String c : conf.getStrings(
YarnConfiguration.YARN_APPLICATION_CLASSPATH,
YarnConfiguration.DEFAULT_YARN_CROSS_PLATFORM_APPLICATION_CLASSPATH)) {
classPathEnv.append(ApplicationConstants.CLASS_PATH_SEPARATOR);
classPathEnv.append(c.trim());
}
classPathEnv.append(ApplicationConstants.CLASS_PATH_SEPARATOR).append(
"./log4j.properties");
// Set the command to execute AM
Vector<CharSequence> vargs = new Vector<CharSequence>(30);
// Set the executable command for Java
LOG.info("Setting up app master command");
vargs.add(Environment.JAVA_HOME.$$() + "/bin/java");
// Set the memory numbers assigned by Xmx parameters under JVM
vargs.add("-Xmx" + amMemory + "m");
// Set class names
vargs.add(appMasterMainClass);
// Set the parameter of ApplicationMaster
vargs.add("--container_memory " + String.valueOf(containerMemory));
vargs.add("--container_vcores " + String.valueOf(containerVirtualCores));
vargs.add("--num_containers " + String.valueOf(numContainers));
vargs.add("--priority " + String.valueOf(shellCmdPriority));
for (Map.Entry<String, String> entry : shellEnv.entrySet()) {
vargs.add("--shell_env " + entry.getKey() + "=" + entry.getValue());
}
if (debugFlag) {
vargs.add("--debug");
}
vargs.add("1>" + ApplicationConstants.LOG_DIR_EXPANSION_VAR + "/AppMaster.stdout");
vargs.add("2>" + ApplicationConstants.LOG_DIR_EXPANSION_VAR + "/AppMaster.stderr");
// Generate the final parameter and configure
StringBuilder command = new StringBuilder();
for (CharSequence str : vargs) {
command.append(str).append(" ");
}
LOG.info("Completed setting up app master command " + command.toString());
List<String> commands = new ArrayList<String>();
commands.add(command.toString());
// Set container for AM to start context
ContainerLaunchContext amContainer = ContainerLaunchContext.newInstance(
localResources, env, commands, null, null, null);
// The requirement of setting resource types, including memory and virtual CPU cores.
Resource capability = Resource.newInstance(amMemory, amVCores);
appContext.setResource(capability);
// If needed, the data of YARN service is passed to the applications in binary format. But it's not needed in this example.
// amContainer.setServiceData(serviceData);
// Set the Token
if (UserGroupInformation.isSecurityEnabled()) {
Credentials credentials = new Credentials();
String tokenRenewer = conf.get(YarnConfiguration.RM_PRINCIPAL);
if (tokenRenewer == null || tokenRenewer.length() == 0) {
throw new IOException(
"Can't get Master Kerberos principal for the RM to use as renewer");
}
// Get the token of the default file system
final Token<?> tokens[] =
fs.addDelegationTokens(tokenRenewer, credentials);
if (tokens!= null) {
for (Token<?> token : tokens) {
LOG.info("Got dt for " + fs.getUri() + "; " + token);
}
}
DataOutputBuffer dob = new DataOutputBuffer();
credentials.writeTokenStorageToStream(dob);
ByteBuffer fsTokens = ByteBuffer.wrap(dob.getData(), 0, dob.getLength());
amContainer.setTokens(fsTokens);
}
appContext.setAMContainerSpec(amContainer);
セットアップ プロセスが完了すると、クライアントは指定された優先度とキューでアプリケーションを送信することができます。
/ / Set the priority of AM
Priority pri = Priority.newInstance(amPriority);
appContext.setPriority(pri);
// Set the queue where the application submits to RM
appContext.setQueue(amQueue);
// Submit the app to AM
yarnClient.submitApplication(appContext);
この時点で、RM はアプリケーションを受け付け、割り当てられたコンテナ上で AM をバックグラウンドでセットアップして起動します。
クライアントは、さまざまな方法で実際のタスクの進捗状況を追跡することができます。
(1) その 1 つは、YarnClient オブジェクトの getApplicationReport() メソッドを使って RM と通信し、アプリケーション レポートを要求することです。
// Use the app ID to get its report
ApplicationReport report = yarnClient.getApplicationReport(appId);
RM から受け取ったレポートには、以下のものが含まれます。
- 一般情報:アプリケーションの番号 (位置)、アプリケーションの提出先のキュー、アプリケーションを提出したユーザー、およびアプリケーションの開始時間を含みます。
- ApplicationMaster の詳細:AM を実行しているホスト、クライアント からの要求を受け付ける RPC ポート、および クライアント と AM が通信するために必要なトークンを含みます。
- アプリケーションの追跡情報:アプリケーションがある形式の進捗追跡をサポートしている場合、
getTrackingUrl()メソッドを通じて追跡される URL を設定でき、クライアントはこのメソッドを使って進捗状況を監視できます。 - アプリケーションの状態:
getYarnApplicationStateでResourceManagerのアプリケーション状態を確認できます。YarnApplicationStateがcompleteに設定されている場合、クライアントはgetFinalApplicationStatusを参照して、アプリケーションのタスクが実際に正常に実行されたかどうかを確認する必要があります。失敗した場合、getDiagnosticsを使って、より詳細な失敗情報を取得できます。
(2) ApplicationMaster がサポートしている場合、クライアント はアプリケーション レポートから取得した hostname:rpcport 情報を使って、直接 AM 自体の進捗状況を照会することができます。
いくつかのケースでは、アプリケーションが長時間実行されている場合、クライアントはアプリケーションを終了したい場合があります。YarnClient は killApplication の呼び出しをサポートしています。これにより、クライアントは ResourceManager を介して AM に終了信号を送信することができます。このように設計されている場合、アプリケーション マネージャーも RPC 層のサポートを通じて呼び出しを終了でき、クライアントはそれを利用できます。
具体的なコードは以下の通りですが、コードは参考のみで、Client.java に記述する必要はありません。
yarnClient.killApplication(appId);
上記の内容を編集した後、内容を保存して vim エディタを終了します。
ApplicationMaster コードの記述
同様に、vim エディタを使って ApplicationMaster.java ファイルを開いてコードを記述します。
vim /home/hadoop/yarn_app/ApplicationMaster.java
package com.labex.yarn.app;
public class ApplicationMaster {
public static void main(String[] args){
//TODO:Edit code here.
}
}
コードの解説は依然としてセグメント形式です。以下に挙げるすべてのコードは、ApplicationMaster クラス内 (つまり、コメント //TODO:Edit code here. があるコード ブロック内) に記述する必要があります。
AM は ジョブ の実際の所有者で、RM によって起動され、クライアントを介してすべての必要な情報とリソースを提供して、タスクを監視して完了させます。
AM は単一のコンテナ内で起動されるため、そのコンテナは他のコンテナと同じ物理ホストを共有する可能性があります。クラウド コンピューティング プラットフォームのマルチテナンシー機能やその他の問題のため、最初から事前に設定されたリッスンするポートを知ることができない場合があります。
したがって、AM が起動する際には、環境を通じていくつかのパラメータを与えることができます。これらのパラメータには、AM コンテナの ContainerId、アプリケーションの提出時刻、および AM を実行している NodeManager ホストの詳細が含まれます。
RM とのすべての相互作用には、アプリケーションをスケジュールする必要があります。このプロセスが失敗した場合、各アプリケーションは再試行することができます。AM のコンテナ ID から ApplicationAttemptId を取得することができます。環境から取得した値をオブジェクトに変換する関連 API があります。
以下のコードを記述します。
Map<String, String> envs = System.getenv();
String containerIdString = envs.get(ApplicationConstants.AM_CONTAINER_ID_ENV);
If (containerIdString == null) {
// The container ID should be set in the environment variable of the framework
Throw new IllegalArgumentException(
"Container ID not set in the environment");
}
ContainerId containerId = ConverterUtils.toContainerId(containerIdString);
ApplicationAttemptId appAttemptID = containerId.getApplicationAttemptId();
AM が完全に初期化された後、2 つのクライアントを起動することができます。1 つは ResourceManager へのクライアントで、もう 1 つは NodeManager へのクライアントです。カスタム イベント ハンドラを使って設定します。詳細については後で説明します。
AMRMClientAsync.CallbackHandler allocListener = new RMCallbackHandler();
amRMClient = AMRMClientAsync.createAMRMClientAsync(1000, allocListener);
amRMClient.init(conf);
amRMClient.start();
containerListener = createNMCallbackHandler();
nmClientAsync = new NMClientAsyncImpl(containerListener);
nmClientAsync.init(conf);
nmClientAsync.start();
AM は定期的に RM にハートビートを送信しなければなりません。そうすることで、RM は AM がまだ実行中であることを知ることができます。RM 上の有効期限間隔は YarnConfiguration によって定義され、そのデフォルト値は構成ファイルの YarnConfiguration.RM_AM_EXPIRY_INTERVAL_MS 構成項目によって定義されます。AM はハートビートを送信するために ResourceManager に自身を登録する必要があります。
// Register yourself with RM and start sending heartbeats to RM
appMasterHostname = NetUtils.getHostname();
RegisterApplicationMasterResponse response = amRMClient.registerApplicationMaster(appMasterHostname, appMasterRpcPort, appMasterTrackingUrl);
登録プロセスの応答情報には、クラスタの最大リソース容量が含まれる場合があります。この情報を使って、アプリケーションの要求をチェックすることができます。
// Temporarily save information about cluster resource capabilities in RM
int maxMem = response.getMaximumResourceCapability().getMemory();
LOG.info("Max mem capability of resources in this cluster " + maxMem);
int maxVCores = response.getMaximumResourceCapability().getVirtualCores();
LOG.info("Max vcores capability of resources in this cluster " + maxVCores);
// Use the maximum memory limit to constrain the container's memory capacity request value
if (containerMemory > maxMem) {
LOG.info("Container memory specified above max threshold of cluster."
+ " Using max value." + ", specified=" + containerMemory + ", max="
+ maxMem);
containerMemory = maxMem;
}
if (containerVirtualCores > maxVCores) {
LOG.info("Container virtual cores specified above max threshold of cluster."
+ " Using max value." + ", specified=" + containerVirtualCores + ", max="
+ maxVCores);
containerVirtualCores = maxVCores;
}
List<Container> previousAMRunningContainers =
response.getContainersFromPreviousAttempts();
LOG.info("Received " + previousAMRunningContainers.size()
+ " previous AM's running containers on AM registration.");
タスクの要件に応じて、AM はタスクを実行するためのコンテナのセットをスケジュールすることができます。これらの要件を使って、必要なコンテナの数を計算し、対応する数のコンテナを要求します。
int numTotalContainersToRequest = numTotalContainers - previousAMRunningContainers.size();
for (int i = 0; i < numTotalContainersToRequest; ++i) {
//Set the request object to the RM request container
ContainerRequest containerAsk = setupContainerAskForRM();
//Send container request to RM
amRMClient.addContainerRequest(containerAsk);
// This loop means polling RM for containers after getting fully allocated quotas
}
上記のループは、すべてのコンテナが起動され、シェル スクリプトが実行されるまで (成功しても失敗しても) 継続して実行されます。
setupContainerAskForRM() では、以下のことを設定する必要があります。
- リソース能力:現在、YARN はメモリベースのリソース要件をサポートしています。したがって、要求は必要なメモリ量を定義する必要があります。この値はメガバイトで定義され、クラスタの最大と最小の能力の正確な倍数よりも小さくする必要があります。このメモリ リソースは、タスク コンテナに課される物理メモリの制限に対応します。リソース能力には、コンピューテーションベースのリソース (vCore) も含まれます。
- 優先度:コンテナ セットを要求する際、AM はコレクションに対して異なる優先度を定義することができます。たとえば、MapReduce AM は Map タスク に必要なコンテナに対してより高い優先度を割り当てることができます。一方、Reduce タスク のコンテナは、より低い優先度を持ちます。
Private ContainerRequest setupContainerAskForRM() {
/ / Set the priority of the request
Priority pri = Priority.newInstance(requestPriority);
/ / Set the request for the resource type, including memory and CPU
Resource capability = Resource.newInstance(containerMemory,
containerVirtualCores);
ContainerRequest request = new ContainerRequest(capability, null, null, pri);
LOG.info("Requested container allocation: " + request.toString());
Return request;
}
AM がコンテナ割り当て要求を送信した後、コンテナは AMRMClientAsync クライアントのイベント ハンドラによって非同期で起動されます。このロジックを処理するプログラムは、AMRMClientAsync.CallbackHandler インターフェイスを実装する必要があります。
(1) コンテナに割り当てられた場合、ハンドラはスレッドを起動する必要があります。そのスレッドは、コンテナを起動するための関連コードを実行します。ここでは、例として LaunchContainerRunnable を使用します。このクラスについては後で説明します。
@Override
public void onContainersAllocated(List<Container> allocatedContainers) {
LOG.info("Got response from RM for container allocation, allocatedCnt=" + allocatedContainers.size());
numAllocatedContainers.addAndGet(allocatedContainers.size());
for (Container allocatedContainer : allocatedContainers) {
LaunchContainerRunnable runnableLaunchContainer =
new LaunchContainerRunnable(allocatedContainer, containerListener);
Thread launchThread = new Thread(runnableLaunchContainer);
// Start and run the container with different threads, which prevents the main thread from blocking when all the containers cannot be allocated resources
launchThreads.add(launchThread);
launchThread.start();
}
}
(2) ハートビートを送信する際、イベント ハンドラはアプリケーションの進捗状況を報告する必要があります。
@Override
public float getProgress() {
// Set the progress information and report it to RM the next time you send a heartbeat
float progress = (float) numCompletedContainers.get() / numTotalContainers;
Return progress;
}
コンテナの起動スレッドは、実際に NM 上でコンテナを起動します。コンテナを AM に割り当てた後、割り当てられたコンテナ上で最終タスクを実行するために ContainerLaunchContext を設定する際に、Client が辿るのと同じようなプロセスに従う必要があります。ContainerLaunchContext を定義した後、AM は NMClientAsync を介してそれを起動することができます。
// Set the necessary commands to execute on the allocated container
Vector<CharSequence> vargs = new Vector<CharSequence>(5);
// Set the executable command
vargs.add(shellCommand);
// Set the path of the shell script
if (!scriptPath.isEmpty()) {
vargs.add(Shell.WINDOWS? ExecBatScripStringtPath
: ExecShellStringPath);
}
// Set parameters for shell commands
vargs.add(shellArgs);
// Add log redirection parameters
vargs.add("1>" + ApplicationConstants.LOG_DIR_EXPANSION_VAR + "/stdout");
vargs.add("2>" + ApplicationConstants.LOG_DIR_EXPANSION_VAR + "/stderr");
// Get the final command
StringBuilder command = new StringBuilder();
for (CharSequence str : vargs) {
command.append(str).append(" ");
}
List<String> commands = new ArrayList<String>();
commands.add(command.toString());
// Set ContainerLaunchContext to set local resources, environment variables, commands and tokens for the constructor.
ContainerLaunchContext ctx = ContainerLaunchContext.newInstance(
localResources, shellEnv, commands, null, allTokens.duplicate(), null);
containerListener.addContainer(container.getId(), container);
nmClientAsync.startContainerAsync(container, ctx);
NMClientAsync オブジェクトとそのイベント ハンドラは、コンテナ イベントを処理する責任があります。それには、コンテナの起動、停止、状態更新、およびエラーが含まれます。
ApplicationMaster が完了したと判断した後、AM-RM の Client から登録解除し、その後 Client を停止する必要があります。
try {
amRMClient.unregisterApplicationMaster(appStatus, appMessage, null);
} catch (YarnException ex) {
LOG.error("Failed to unregister application", ex);
} catch (IOException e) {
LOG.error("Failed to unregister application", e);
}
amRMClient.stop();
上記の内容は ApplicationMaster の主なコードです。編集した後、内容を保存して vim エディタを終了します。
アプリケーション起動のプロセス
Hadoop クラスタ上でアプリケーションを起動するプロセスは以下の通りです。
アプリケーションのコンパイルと起動
前節のコードが完了した後、Maven や Gradle などのビルド ツールを使って Jar パッケージにコンパイルし、Hadoop クラスタに送信することができます。
コンパイル プロセスでは、ネットワークを介して関連する依存関係を取得する必要があるため、時間がかかります (ピーク時で約 1 時間)。したがって、ここではコンパイル プロセスを省略し、Hadoop インストール ディレクトリにある既にコンパイルされた Jar パッケージを使用して、後続の実験を行います。
このステップでは、指定された jar を maven でビルドする代わりに、簡単なサンプル jar を使って yarn アプリケーションを実行します。
ターミナルで yarn jar コマンドを使って実行を送信します。以下のコマンドに関与するパラメータは、実行する Jar パッケージのパス、メイン クラスの名前、YARN フレームワークに送信する Jar パッケージのパス、実行する shell コマンドの数、およびコンテナの数です。
/home/hadoop/hadoop/bin/yarn jar /home/hadoop/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar pi 3 3
ターミナルの出力を見ると、アプリケーションの実行の進捗状況がわかります。
Estimated value of Pi is 3.55555555555555555556
タスクの実行中に、ターミナルの出力から各段階のプロンプトを見ることができます。たとえば、Client の初期化、RM に接続中、クラスタ情報の取得 などです。
アプリケーション実行結果の表示
デスクトップで Firefox ウェブ ブラウザをダブルクリックして開き、アドレスバーに以下の URL を入力して、Hadoop クラスタの YARN パターンのノードのリソース情報を表示します。
http://localhost:8088
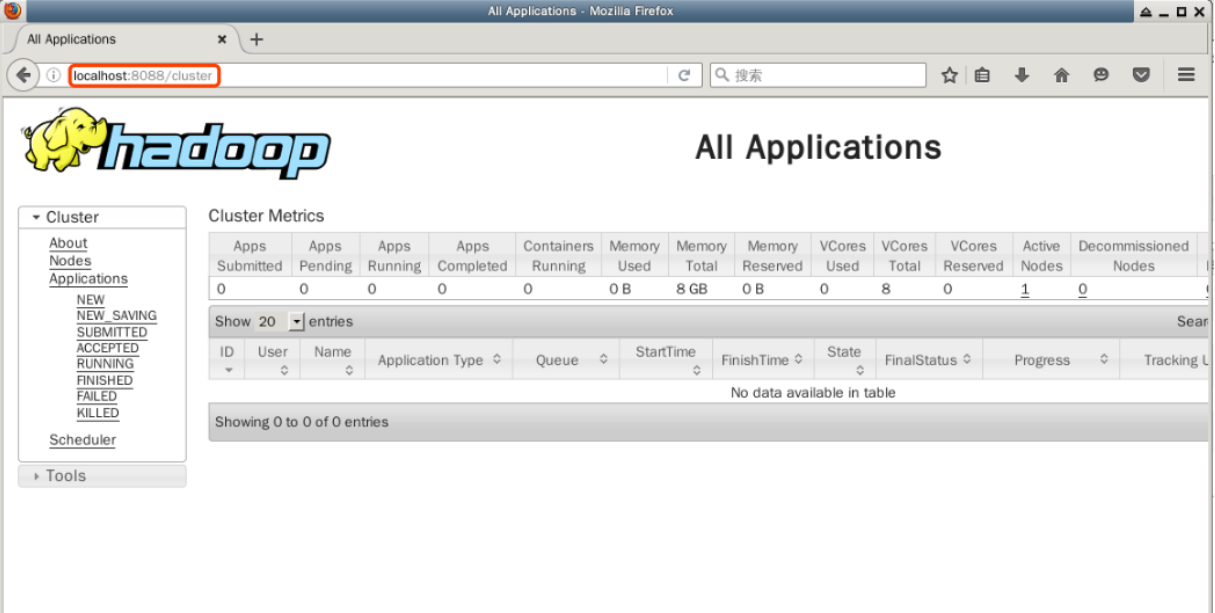
このページには、Hadoop クラスタのすべての情報が表示されます。ノード、アプリケーション、およびスケジューラの状態が含まれます。
これらの中で最も重要なのはアプリケーションの管理で、ここで後で送信したアプリケーションの実行状態を確認することができます。現時点では Firefox ブラウザを閉じないでください。
まとめ
Hadoop の疑似分散クラスタの構築を踏まえて、この実験では YARN フレームワークのアーキテクチャ、動作原理、設定、および開発とモニタリング技術を学びます。コースでは多くのコードと設定ファイルが与えられているので、注意深く読んでください。


