
はじめに
OpenAI Whisper は、オーディオやビデオなどのさまざまなメディアファイルの音声を文字に変換する能力に優れています。このチュートリアルでは、Whisper コマンドの基本的な使い方から高度な使い方までを案内し、高精度の文字起こしを行う手助けをします。
メディア文字起こしのための Whisper の使い方をマスターする
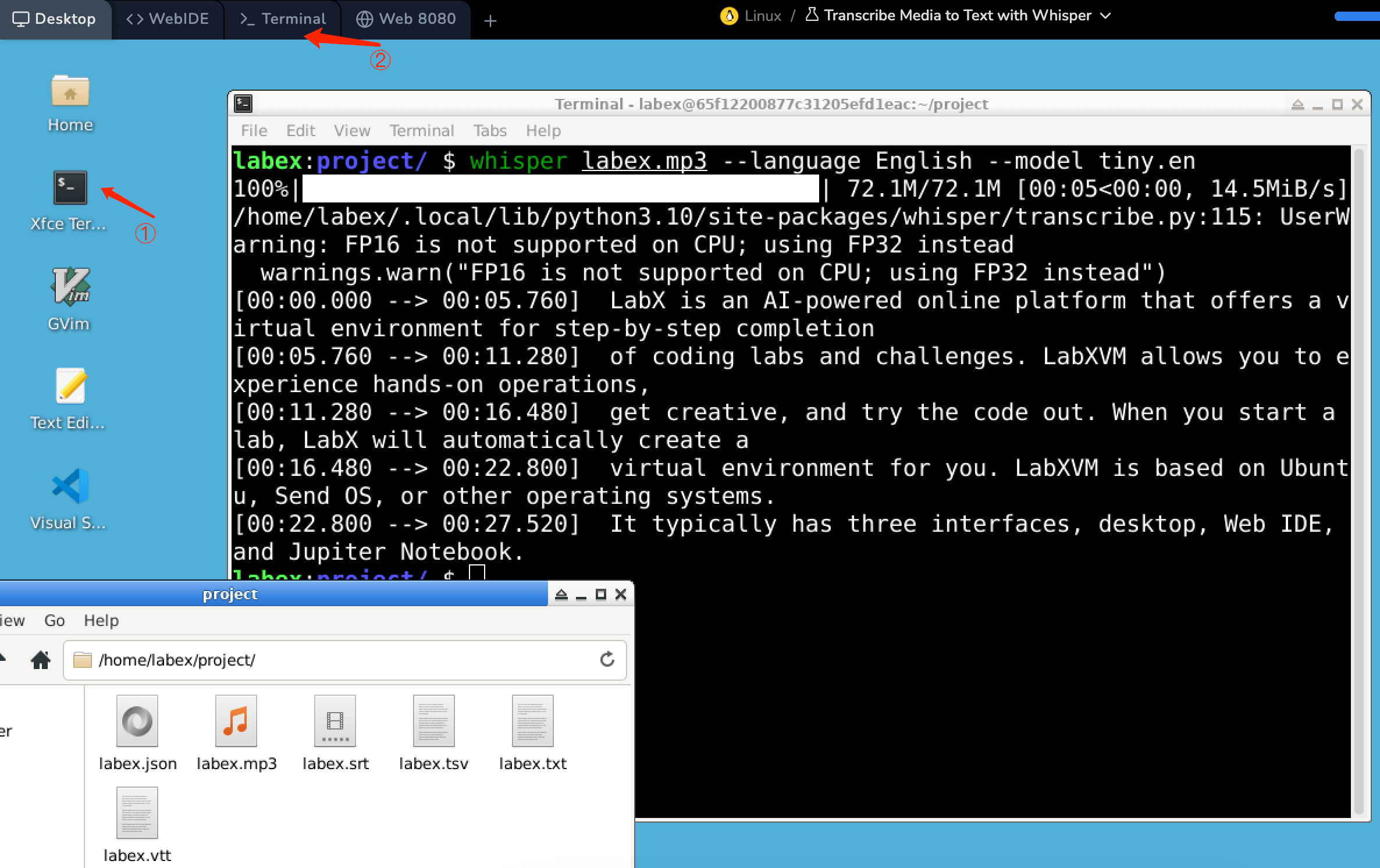
/home/labex/project にはオーディオファイル labex.mp3 があります。環境内のターミナル(図の①または②)を開き、以下のコマンドを入力してください。
whisper labex.mp3 --language English --model tiny.en
このコマンドでは、whisper に labex.mp3 というメディアファイルの文字起こしを指示しています。
--languageパラメータは英語に設定されており、メディアで話されている言語を示しています。--modelオプションは使用する Whisper モデルを選択します。tiny.enは英語用に最適化された、より小さく高速なモデルで、迅速なタスクや性能の低いハードウェアに適しています。
Whisper コマンドを実行してメディアコンテンツの文字起こしを行った後、/home/labex/project にいくつかのファイルが生成されます。それぞれのファイルは、文字起こしされたテキストに対して異なる目的と形式を持っています。以下に各ファイルタイプの概要を示します。
- output.json:このファイルは、JSON 形式で詳細な文字起こし結果を含んでいます。JSON は軽量なデータ交換形式で、人間にとって読み書きが容易で、機械にとって解析や生成が容易です。JSON ファイルには、文字起こしされたテキストだけでなく、タイムスタンプ、信頼度スコア、場合によっては話者識別などの追加のメタデータも含まれています。この形式は、文字起こし結果の詳細な処理や分析が必要なアプリケーション、例えば正確なタイミングで字幕を生成する場合や、発話パターンを分析する場合に特に有用です。
- output.srt:SRT(SubRip Subtitle)ファイル形式は、字幕を表すために使用されます。SRT ファイルの各エントリは、シーケンス番号、テキストを表示する時間範囲、およびテキスト自体で構成されています。SRT ファイルは、ビデオ再生ソフトウェアやプラットフォームで広くサポートされているため、ビデオに字幕を追加するのに最適な形式です。
- output.tsv:TSV は Tab-Separated Values の略です。この形式は CSV(Comma-Separated Values)に似ていますが、データフィールドの区切り文字としてタブを使用します。Whisper からの output.tsv ファイルには、タブで区切られた文字起こしテキスト、タイミング情報、および信頼度スコアが含まれる場合があります。この形式は、データ分析タスクや、文字起こし結果をデータベースやスプレッドシートにインポートする場合に役立ちます。
- output.txt:これは、タイムスタンプやメタデータを含まない、ただのテキストファイルです。この形式のシンプルさから、テキストの内容がタイミングよりも重要なアプリケーションや、人間または基本的なテキスト処理ソフトウェアによってテキストを読み取ったり処理したりする必要がある場合に適しています。
- output.vtt:VTT(Web Video Text Tracks)は、SRT に似た別の字幕ファイル形式ですが、より多くの機能を備えています。これは HTML5 ビデオタグの字幕の標準形式で、字幕のスタイリングや配置をサポートしています。VTT 形式は、ウェブビデオコンテンツに特に有用で、カスタマイズ可能な字幕によるより豊かな視聴体験を提供します。
これらの各ファイルは、単純なテキストドキュメントから詳細な分析やビデオ字幕まで、さまざまなユースケースに対応しており、文字起こし結果の利用方法に柔軟性を提供します。
まとめ
このチュートリアルでは、OpenAI Whisper を使ってメディアファイルの内容を文字に起こす方法を学びました。基本的な使い方から始めて、簡単な英語のメディアファイルの文字起こしを行いました。その後、異なるモデルの選択やバッチ処理など、文字起こしプロセスを最適化するための追加機能を探索しました。Whisper は、さまざまなメディアファイルの文字起こしを簡単に行える汎用的なツールとして際立っています。


