
はじめに
この実験では、Hadoop の主なコンポーネントの 1 つである HDFS について続けて説明します。この実験を学ぶことで、HDFS の動作原理と基本操作、および Hadoop ソフトウェアアーキテクチャにおける WebHDFS のアクセス方法を理解することができます。
HDFS の紹介
その名の通り、HDFS(Hadoop Distributed File System)は Hadoop フレームワーク内の分散ストレージのコンポーネントであり、フォールトトレラントで拡張可能です。
HDFS は、Hadoop クラスタの一部として、または単独のユニバーサルな分散ファイルシステムとして使用できます。たとえば、HBaseは HDFS をベースに構築されており、Sparkもデータソースの 1 つとして HDFS を使用できます。HDFS のアーキテクチャと基本操作を学ぶことは、特定のクラスタの構成、改善、診断に大きな役立ちます。
HDFS は、Hadoop アプリケーションによって使用される分散ストレージであり、データのソースと宛先です。HDFS クラスタは主に、ファイルシステムのメタデータを管理するNameNodesと、実際のデータを格納するDataNodesで構成されています。アーキテクチャは、以下の図に示すように、NameNodes、DataNodes、およびClients間の相互作用パターンを示しています。
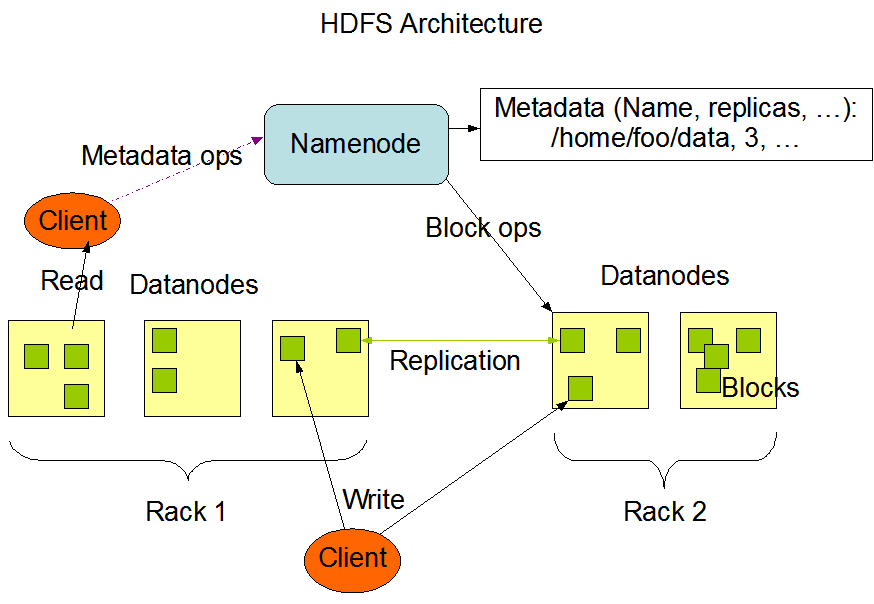 この図は Hadoop の公式サイトから引用しています。
この図は Hadoop の公式サイトから引用しています。
HDFS の概要のまとめ:
- HDFS の概要:HDFS(Hadoop Distributed File System)は、Hadoop フレームワーク内のフォールトトレラントで拡張可能な分散ストレージコンポーネントです。
- アーキテクチャ:HDFS クラスタは、メタデータを管理する NameNodes と、実際のデータを格納する DataNodes で構成されています。アーキテクチャは、1 つの NameNode と複数の DataNode からなるマスター/スレーブモデルに従っています。
- ファイルストレージ:HDFS のファイルは、DataNodes にまたがって格納されるブロックに分割され、デフォルトのブロックサイズは 64MB です。
- 操作:NameNode はファイルシステムの名前空間操作を処理し、DataNodes はクライアントからの読み書き要求を管理します。
- 相互作用:クライアントは、メタデータのために NameNode と通信し、ファイルデータのために直接 DataNodes と相互作用します。
- 展開:通常、単一の専用ノードが NameNode を実行し、他の各ノードが DataNode インスタンスを実行します。HDFS は Java を使用して構築されており、さまざまな環境間での移植性を提供します。
HDFS に関するこれらのポイントを理解することは、効果的に Hadoop クラスタを構成、最適化、診断するのに役立ちます。
ファイルシステムの概要
ファイルシステムの名前空間
- 階層的な組織:HDFS と従来の Linux ファイルシステムの両方が、ディレクトリツリー構造を持つ階層的なファイル組織をサポートしており、ユーザーやアプリケーションがディレクトリを作成し、ファイルを保存できるようにしています。
- アクセスと操作:ユーザーは、コマンドラインや API などのさまざまなアクセスインターフェイスを通じて HDFS と相互作用でき、ファイルの作成、削除、移動、名前変更などの操作が可能です。
- 機能サポート:バージョン 3.3.6 では、HDFS はユーザークォータ、アクセス権限、ハードリンク、ソフトリンクを実装していません。ただし、将来のリリースでは、アーキテクチャがそれらの実装を可能にするため、これらの機能をサポートする可能性があります。
- NameNode 管理:HDFS の NameNode は、ファイルシステムの名前空間とプロパティのすべての変更を処理し、ファイルのレプリケーションファクターを管理します。これは、HDFS 上で維持するファイルのコピー数を指定します。
データコピー
開発当初、HDFS は、大規模なクラスタにおいて、ノード間で交差し、高度に信頼性の高い方法で非常に大きなファイルを保存するように設計されました。前述のとおり、HDFS はブロック単位でファイルを保存します。具体的には、各ファイルをブロックのシーケンスとして保存します。最後のブロックを除き、ファイル内のすべてのブロックは同じサイズです。
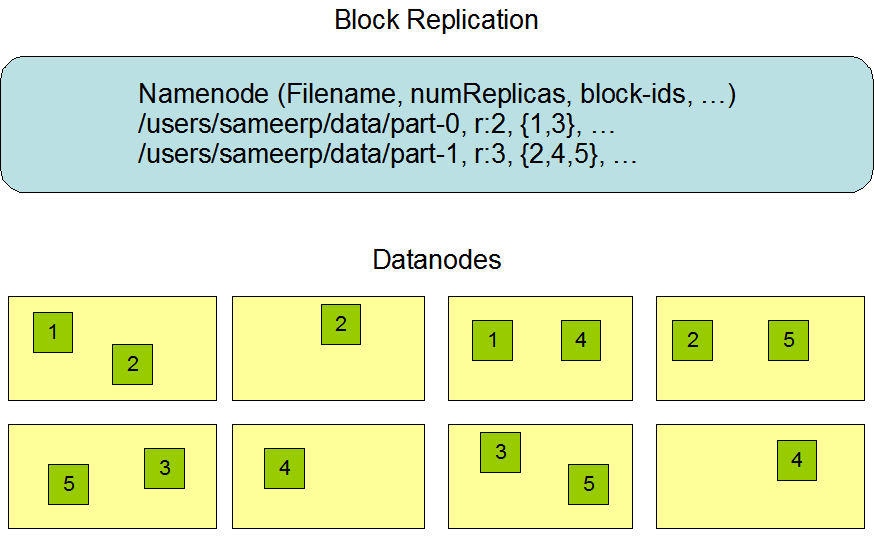 この図は Hadoop の公式サイトから引用しています。
この図は Hadoop の公式サイトから引用しています。
HDFS のデータレプリケーションと高可用性:
- データレプリケーション:HDFS では、ファイルは複数の DataNode にまたがってレプリケーションされるブロックに分割され、フォールトトレラントを確保します。レプリケーションファクターは、ファイルを作成または変更する際に指定でき、任意の時点で各ファイルには 1 つのライターがいます。
- レプリケーション管理:NameNode は、DataNode からのハートビートとブロックステータスレポートを受け取ることで、ファイルブロックのコピー方法を管理します。DataNode は、ハートビートを通じてその動作状態を報告し、ブロックステータスレポートには、DataNode に保存されているすべてのブロックに関する情報が含まれています。
- 高可用性:HDFS は、ディスク破損やその他の故障の場合に、クラスタの他の部分から失われたファイルコピーを内部的に復元することで、ある程度の高可用性を提供します。このメカニズムは、分散ストレージシステム内のデータの整合性と信頼性を維持するのに役立ちます。
ファイルシステムメタデータの永続化
- 名前空間管理:ファイルシステムのメタデータを含む HDFS 名前空間は、NameNode に保存されます。ファイルシステムのメタデータのすべての変更は、EditLog に記録され、これはファイル作成などのトランザクションを永続化します。EditLog は、ローカルファイルシステムに保存されます。
- FsImage:ブロックからファイルへのマッピングや属性など、ファイルシステムの名前空間全体が、FsImage と呼ばれるファイルに保存されます。このファイルも、NameNode が存在するローカルファイルシステムに保存されます。
- チェックポイントプロセス:チェックポイントプロセスでは、NameNode 起動時にディスクから FsImage と EditLog を読み取ります。EditLog 内のすべてのトランザクションが、メモリ内の FsImage に適用され、その後、永続化のためにディスクに保存されます。このプロセスの後、古い EditLog をトリムできます。現在のバージョン(3.3.6)では、チェックポイントは NameNode 起動時にのみ発生しますが、将来のバージョンでは、信頼性とデータの整合性を向上させるため、定期的なチェックポイントが導入される可能性があります。
その他の機能
- TCP/IPベース:HDFS のすべての通信プロトコルは、TCP/IP プロトコルスイートの上に構築されており、分散ファイルシステム内のノード間での信頼性の高いデータ交換を確保します。
- クライアントプロトコル:クライアントと NameNode の間の通信は、クライアントプロトコルを通じて円滑になされます。クライアントは、NameNode 上の構成可能な TCP ポートに接続を開始して、ファイルシステムのメタデータと相互作用します。
- DataNode プロトコル:DataNode と NameNode の間の通信は、DataNode プロトコルに依存しています。DataNode は、分散ストレージシステムの一部として、その状態を報告し、ハートビート信号を送信し、データブロックを転送するために NameNode と通信します。
- リモートプロシージャコール(RPC):クライアントプロトコルと DataNode プロトコルの両方は、リモートプロシージャコール(RPC)メカニズムを使用して抽象化されています。NameNode は、DataNode またはクライアントによって開始された RPC 要求に応答し、通信プロセスにおいて受動的な役割を維持します。
以下は、拡張読み取り用の資料です:
ユーザーを切り替える
タスクコードを記述する前に、まずhadoopユーザーに切り替える必要があります。デスクトップ上のXfce端末をダブルクリックして開き、次のコマンドを入力します。hadoopユーザーのパスワードはhadoopです。ユーザーを切り替える際に必要になります。
su - hadoop
labex:~/ $ su - hadoop
hadoop:~$
ヒント:hadoopユーザーのパスワードはhadoopです。
HDFS の初期化
HDFS を初めて使用する前に、NameNode を初期化する必要があります。この操作は、ディスクをフォーマットする操作と比較できますので、HDFS にデータを保存する際には、このコマンドを慎重に使用してください。
それ以外の場合は、このセクションの実験を再起動してください。「デフォルト環境」を使用して、次のコマンドで HDFS を初期化します。
/home/hadoop/hadoop/bin/hdfs namenode -format
ヒント:上記のコマンドは HDFS ファイルシステムをフォーマットしますので、コマンドを実行する前に HDFS データディレクトリを削除する必要があります。
そのため、Hadoop に関するサービスを停止して、Hadoop データを削除する必要があります。
stop-all.sh
rm -rf ~/hadoopdata
次のメッセージが表示されたら、初期化が完了しています。
2024-03-01 11:16:10,439 INFO common.Storage: Storage directory /home/hadoop/hadoopdata/hdfs/namenode has been successfully formatted.
ファイルのインポート
HDFS は、ローカルディスクの上に構築された階層型の分散ストレージシステムであるため、HDFS を使用する前にデータをインポートする必要があります。
最初に、いくつかのファイルを用意する最も便利な方法は、Hadoop の設定ファイルを例にすることです。
まず、HDFS デーモンを起動する必要があります。
/home/hadoop/hadoop/sbin/start-dfs.sh
サービスを確認する。
hadoop:~$ jps
8341 SecondaryNameNode
7962 NameNode
8474 Jps
8107 DataNode
ディレクトリを作成し、端末に次のコマンドを入力してデータをコピーします。
cd /home/hadoop
mkdir sample_data
cp -r /home/hadoop/hadoop/etc/hadoop/* sample_data/
ディレクトリの内容を一覧表示する。
hadoop:~$ ls /home/hadoop/sample_data/
capacity-scheduler.xml kms-log4j.properties
configuration.xsl kms-site.xml
...
HDFS上の任意の操作は、hdfs dfsで始まり、対応する操作パラメータで補完されます。最も一般的に使用されるパラメータはputであり、次のように使用され、端末に入力できます。
/home/hadoop/hadoop/bin/hdfs dfs -put /home/hadoop/sample_data/hadoop-policy.xml /policy.xml
ディレクトリの内容を一覧表示する。
hadoop:~$ hdfs dfs -ls /policy.xml
-rw-r--r-- 1 hadoop supergroup 11765 2024-03-01 11:37 /policy.xml
コマンドの最後の/policy.xmlは、HDFS に保存されるファイル名がpolicy.xmlで、パスが/(ルートディレクトリ)であることを意味します。以前のファイル名を引き続き使用したい場合は、パス/を直接指定できます。
複数のファイルをアップロードする必要がある場合は、ローカルディレクトリのファイルパスを連続して指定し、HDFS のターゲット格納パスで終了させることができます。
/home/hadoop/hadoop/bin/hdfs dfs -mkdir -p /user/hadoop
/home/hadoop/hadoop/bin/hdfs dfs -put /home/hadoop/sample_data/httpfs-env.sh /home/hadoop/sample_data/mapred-env.sh /user/hadoop
ディレクトリの内容を一覧表示する。
hadoop:~$ hdfs dfs -ls /user/hadoop
Found 2 items
-rw-r--r-- 1 hadoop supergroup 1484 2024-03-01 11:42 /user/hadoop/httpfs-env.sh
-rw-r--r-- 1 hadoop supergroup 1764 2024-03-01 11:42 /user/hadoop/mapred-env.sh
パス関連のパラメータを指定する場合、ルールは Linux システムと同じです。ワイルドカード(たとえば*.sh)を使用して操作を簡略化することができます。
ファイル操作
同様に、指定したディレクトリ内のファイルを一覧表示するには、-lsパラメータを使用します。
/home/hadoop/hadoop/bin/hdfs dfs -ls /user/hadoop
ここに表示されるファイルは、実験環境によって異なる場合があります。
ファイルの内容を表示する必要がある場合は、catパラメータを使用できます。最も簡単な考え方は、HDFS 上のファイルパスを直接指定することです。HDFS 上のファイルとローカルディレクトリを比較する必要がある場合は、それぞれのパスを別々に指定できます。ただし、ローカルディレクトリはfile://指示子で始める必要があり、その後にファイルパスを付け加える必要があります(たとえば/home/hadoop/.bashrc、先頭の/を忘れないでください)。そうでなければ、ここで指定された任意のパスは、デフォルトで HDFS 上のパスとして認識されます。
/home/hadoop/hadoop/bin/hdfs dfs -cat file:///home/hadoop/.bashrc /user/hadoop/mapred-env.sh
出力は次のとおりです。
hadoop:~$ hdfs dfs -cat file:///home/hadoop/.bashrc /user/hadoop/mapred-env.sh
## ~/.bashrc: executed by bash(1) for non-login shells.
## see /usr/share/doc/bash/examples/startup-files (in the package bash-doc)
## for examples
## If not running interactively, don't do anything
case $- in
...
ファイルを別のパスにコピーする必要がある場合は、cpパラメータを使用できます。
/home/hadoop/hadoop/bin/hdfs dfs -cp /user/hadoop/mapred-env.sh /user/hadoop/copied_file.txt
同様に、ファイルを移動する必要がある場合は、mvパラメータを使用します。これは基本的に Linux ファイルシステムコマンド形式と同じです。
/home/hadoop/hadoop/bin/hdfs dfs -mv /user/hadoop/mapred-env.sh /moved_file.txt
lsrパラメータを使用して、現在のディレクトリの内容、サブディレクトリの内容を含めて一覧表示します。出力は次のとおりです。
hdfs dfs -lsr /
HDFS 上のファイルに新しいコンテンツを追加したい場合は、appendToFileパラメータを使用できます。また、追加するローカルファイルパスを指定する際には、複数指定できます。最後のパラメータが追加対象となります。ファイルは HDFS 上に存在している必要があり、そうでない場合はエラーが報告されます。
echo 1 >> a.txt
echo 2 >> b.txt
/home/hadoop/hadoop/bin/hdfs dfs -appendToFile a.txt b.txt /user/hadoop/mapred-env.sh
追加が成功したかどうかを確認するために、ファイルの末尾(ファイルの最後の部分)の内容を表示するには、tailパラメータを使用できます。
/home/hadoop/hadoop/bin/hdfs dfs -tail /user/hadoop/mapred-env.sh
tailコマンドの出力を確認する。
hadoop:~$ echo 1 >> a.txt
echo 2 >> b.txt
hdfs dfs -appendToFile a.txt b.txt /user/hadoop/mapred-env.sh
hadoop:~$ hdfs dfs -tail /user/hadoop/mapred-env.sh
1
2
ファイルまたはディレクトリを削除する必要がある場合は、rmパラメータを使用します。このパラメータには、-rと-fを付けることもでき、これらは Linux ファイルシステムコマンドrmと同じ意味を持ちます。
/home/hadoop/hadoop/bin/hdfs dfs -rm /moved_file.txt
ファイルmoved_file.txtの内容が削除され、コマンドは次の出力を返します。'Deleted /moved_file.txt'
ディレクトリ操作
前の内容では、HDFS でディレクトリを作成する方法を学びました。実際、一度に複数のディレクトリを作成する必要がある場合は、複数のディレクトリのパスを直接パラメータとして指定できます。-pパラメータは、親ディレクトリが存在しない場合に自動的に作成されることを示します。
/home/hadoop/hadoop/bin/hdfs dfs -mkdir -p /user/hadoop/dir1 /user/hadoop/dir2/sub_dir1
特定のファイルまたはディレクトリがどのくらいのスペースを占めているかを確認したい場合は、duパラメータを使用できます。
/home/hadoop/hadoop/bin/hdfs dfs -du /user/hadoop/
出力は次のとおりです。
hadoop:~$ hdfs dfs -du /user/hadoop/
1764 1764 /user/hadoop/copied_file.txt
0 0 /user/hadoop/dir1
0 0 /user/hadoop/dir2
1484 1484 /user/hadoop/httpfs-env.sh
4 4 /user/hadoop/mapred-env.sh
ファイルのエクスポート
前のセクションでは、主に HDFS 内のファイルとディレクトリ操作を紹介しました。MapReduce などのアプリケーションで計算が行われ、結果を記録したファイルが生成された場合、そのファイルを Linux システムのローカルディレクトリにエクスポートするには、getパラメータを使用できます。
ここで最初のパスパラメータは HDFS 内のパスを指し、最後のパスはローカルディレクトリに保存するパスを指します。
/home/hadoop/hadoop/bin/hdfs dfs -get /user/hadoop/mapred-env.sh /home/hadoop/exported_file.txt
エクスポートが成功すると、ローカルディレクトリにファイルが見つかります。
cd ~
ls
出力は次のとおりです。
a.txt b.txt exported_file.txt hadoop hadoopdata sample_data
Hadoop の Web 操作
Web 管理インターフェイス
各 NameNode または DataNode は内部で Web サーバーを実行し、クラスタの現在の状態などの基本情報を表示します。デフォルトの設定では、NameNode のホームページはhttp://localhost:9870/です。ここには、DataNode とクラスタの基本統計が表示されます。
Web ブラウザを開き、アドレスバーに次のように入力します。
http://localhost:9870/
概要の中の現在の「クラスタ」におけるアクティブな DataNode ノードの数を確認できます。
この Web インターフェイスを使って、HDFS 内のディレクトリやファイルを参照することもできます。上部のメニューバーで、「ユーティリティ」の下にある「ファイルシステムを参照する」リンクをクリックします。
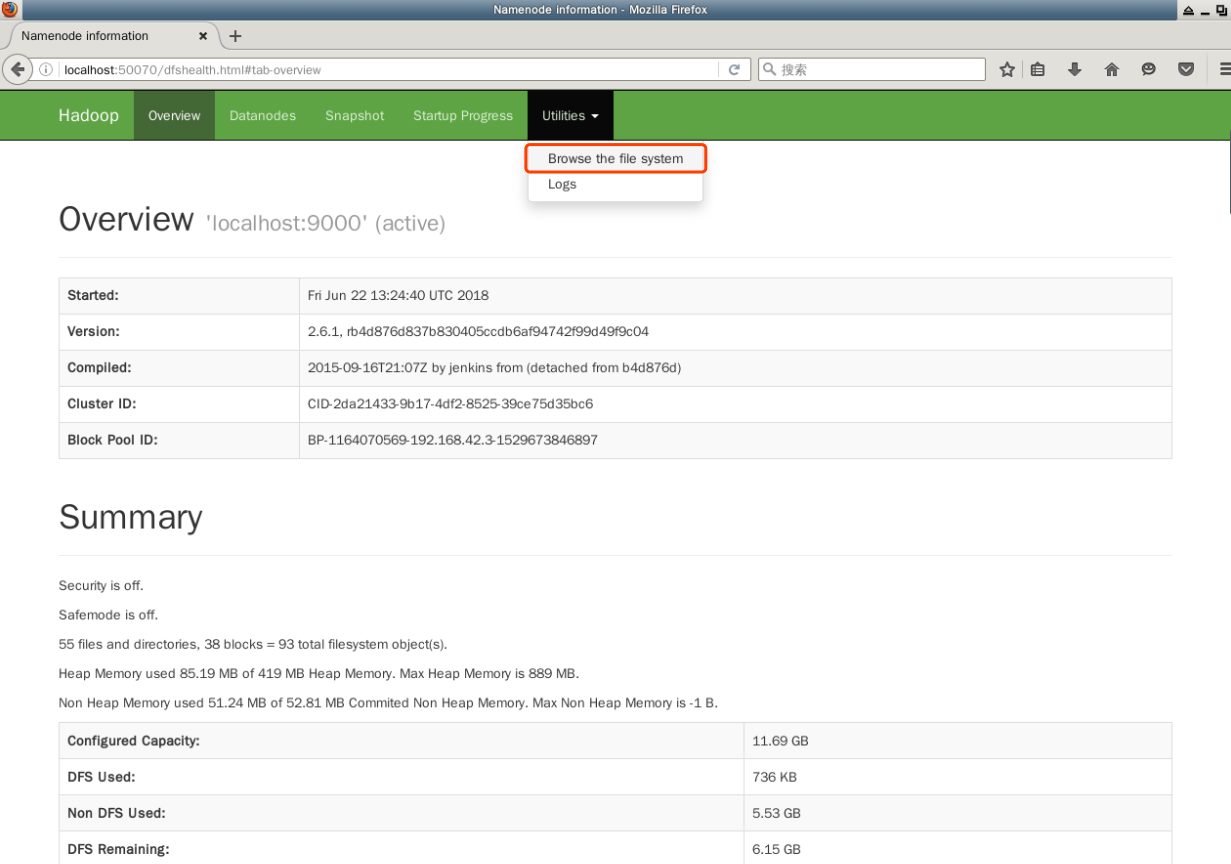
Hadoop クラスタを停止する
ここでは、WebHDFS の基本操作の一部を紹介しました。WebHDFS のドキュメントには、さらに詳細な説明があります。この実験はここまでです。習慣として、Hadoop クラスタを停止する必要があります。
/home/hadoop/hadoop/sbin/stop-yarn.sh
/home/hadoop/hadoop/sbin/stop-dfs.sh
hadoop:~$ jps
11633 Jps
まとめ
この実験では、HDFS のアーキテクチャを紹介しました。また、コマンドラインから基本的な HDFS 操作コマンドを学び、その後 HDFS の Web アクセスパターンに移行しました。これにより、HDFS が外部アプリケーションに対する本格的なストレージサービスとして機能するようになります。
この実験では、WebHDFS でのファイル削除のシナリオは一切挙げていません。ドキュメントをご自身で確認してください。公式ドキュメントにはさらに多くの機能が隠されているので、ドキュメントの読み込みに興味を持ち続けるようにしてください。
以下は、拡張読み込み用の資料です。


