
Introduction
Ce laboratoire porte principalement sur les bases d'Hadoop et est écrit pour les étudiants ayant une certaine connaissance de Linux afin qu'ils comprennent l'architecture du système logiciel Hadoop, ainsi que les méthodes de déploiement de base.
Veuillez saisir vous-même tout le code d'exemple présent dans le document et évitez autant que possible de simplement copier et coller. Seulement de cette manière pourrez-vous être plus familier avec le code. Si vous rencontrez des problèmes, relisez attentivement la documentation, sinon vous pouvez aller sur le forum pour demander de l'aide et communiquer.
Présentation d'Hadoop
Distribué sous la licence Apache 2.0, Apache Hadoop est un cadre logiciel open source qui prend en charge les applications distribuées intensives en données.
La bibliothèque logicielle Apache Hadoop est un cadre qui permet le traitement distribué de grands ensembles de données sur des grappes informatiques en utilisant un modèle de programmation simple. Il est conçu pour être extensible d'un serveur unique à des milliers de machines, chacune offrant un calcul et un stockage locaux plutôt que de dépendre du matériel pour offrir une haute disponibilité.
Concepts clés
Un projet Hadoop comprend principalement les quatre modules suivants :
- Hadoop Common : Une application publique qui offre un support aux autres modules Hadoop.
- Hadoop Distributed File System (HDFS) : Un système de fichiers distribué qui offre un accès à haut débit aux données des applications.
- Hadoop YARN : Un cadre de planification de tâches et de gestion des ressources de grappe.
- Hadoop MapReduce : Un cadre de calcul parallèle pour de grands ensembles de données basé sur YARN.
Pour les utilisateurs nouveaux en Hadoop, vous devriez vous concentrer sur HDFS et MapReduce. En tant que cadre de calcul distribué, HDFS répond aux exigences de stockage des données du cadre, et MapReduce répond aux exigences de calcul des données du cadre.
La figure suivante montre l'architecture de base d'un cluster Hadoop :
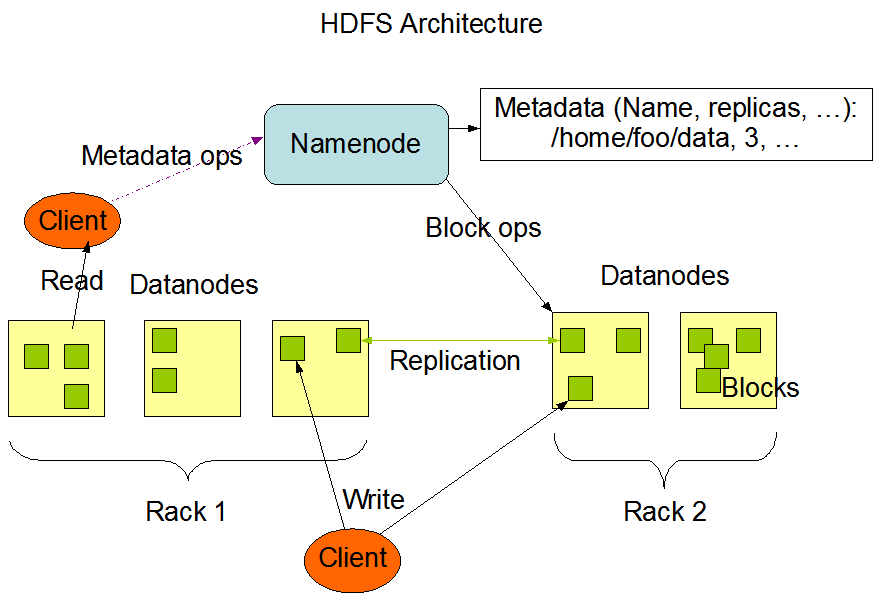
Cette image est extraite du site officiel d'Hadoop.
Écosystème Hadoop
De même que Facebook a dérivé le référentiel de données Hive à partir d'Hadoop, il existe de nombreux projets open source associés dans la communauté. Voici quelques projets récemment actifs :
- HBase : Une base de données distribuée évolutive qui prend en charge le stockage de données structurées pour de grandes tables.
- Hive : Une infrastructure de référentiel de données qui offre la synthèse de données et des requêtes temporaires.
- Pig : Un langage de flux de données avancé et un cadre d'exécution pour le calcul parallèle.
- ZooKeeper : Un service de coordination haute performance pour les applications distribuées.
- Spark : Un moteur de calcul de données Hadoop rapide et polyvalent avec un modèle de programmation simple et expressif qui prend en charge l'ETL (extraction, transformation et chargement) de données, l'apprentissage automatique, le traitement en flux et le calcul graphique.
Ce laboratoire commencera par Hadoop, en introduisant les utilisations de base des composants associés.
Il est important de noter que Spark, un cadre de calcul mémoire distribué, est issu du système Hadoop. Il a une bonne héritage pour des composants tels que HDFS et YARN, et il améliore également certains des défauts existants d'Hadoop.
Certains d'entre vous peuvent avoir des questions sur le chevauchement entre les scénarios d'utilisation d'Hadoop et de Spark, mais apprendre le modèle de fonctionnement et le modèle de programmation d'Hadoop aidera à approfondir la compréhension du cadre Spark, voilà pourquoi il est important d'apprendre Hadoop en premier.
Déploiement d'Hadoop
Pour les débutants, il n'y a pas grande différence entre les versions d'Hadoop postérieures à la version 2.0. Cette section prendra la version 3.3.6 comme exemple.
Hadoop a trois principaux modèles de déploiement :
- Mode autonome : S'exécute dans un seul processus sur un seul ordinateur.
- Mode pseudo-distribué : S'exécute dans plusieurs processus sur un seul ordinateur. Ce mode simule un scénario "multi-nœud" sous un seul nœud.
- Mode totalement distribué : S'exécute dans un seul processus sur chacun de plusieurs ordinateurs.
Ensuite, nous installons la version 3.3.6 d'Hadoop sur un seul ordinateur.
Configuration des utilisateurs et des groupes d'utilisateurs
Double-cliquez pour ouvrir le terminal Xfce sur votre bureau et entrez la commande suivante pour créer un utilisateur nommé hadoop :
cd ~
sudo adduser hadoop
Ensuite, suivez les invitations pour entrer le mot de passe de l'utilisateur hadoop ; par exemple, définissez le mot de passe sur hadoop.
Remarque : Lorsque vous entrez le mot de passe, il n'y a pas de message d'invite dans la commande. Vous pouvez simplement appuyer sur Entrée une fois que vous avez fini.
Ensuite, ajoutez l'utilisateur hadoop créé au groupe d'utilisateurs sudo pour accorder à l'utilisateur des privilèges plus élevés :
sudo usermod -G sudo hadoop
Vérifiez que l'utilisateur hadoop a été ajouté au groupe sudo en entrant la commande suivante :
sudo cat /etc/group | grep hadoop
Vous devriez voir la sortie suivante :
sudo:x:27:shiyanlou,labex,hadoop
Installation de JDK
Comme mentionné dans le contenu précédent, Hadoop est principalement développé en Java. Par conséquent, pour l'exécuter, il est nécessaire d'avoir un environnement Java.
Différentes versions d'Hadoop présentent des différences subtiles dans les exigences en termes de version de Java. Pour déterminer quelle version de JDK choisir pour votre Hadoop, vous pouvez consulter Hadoop Java Versions sur le site Wiki d'Hadoop.
Changez d'utilisateur :
su - hadoop
Installez la version JDK 11 en entrant la commande suivante dans le terminal :
sudo apt update
sudo apt install openjdk-11-jdk -y
Une fois l'installation réussie, vérifiez la version de Java actuelle :
java -version
Consultez la sortie :
openjdk version "11.0.22" 2024-01-16
OpenJDK Runtime Environment (build 11.0.22+7-post-Ubuntu-0ubuntu222.04.1)
OpenJDK 64-Bit Server VM (build 11.0.22+7-post-Ubuntu-0ubuntu222.04.1, mixed mode, sharing)
Configuration de la connexion SSH sans mot de passe
Le but de l'installation et de la configuration de SSH est de faciliter l'exécution par Hadoop de scripts liés au démon de gestion distante. Ces scripts nécessitent le service sshd.
Lors de la configuration, commençons par basculer sur l'utilisateur hadoop. Entrez la commande suivante dans le terminal pour ce faire :
su hadoop
Si une invite vous demande d'entrer un mot de passe, entrez simplement le mot de passe spécifié lors de la création précédente de l'utilisateur (hadoop) :
Une fois le changement d'utilisateur effectué avec succès, l'invite de commande devrait être comme celle montrée ci-dessus. Les étapes suivantes seront exécutées en tant qu'utilisateur hadoop.
Ensuite, générez la clé pour la connexion SSH sans mot de passe.
Le terme "sans mot de passe" signifie en fait de changer le mode d'authentification de SSH de la connexion par mot de passe à la connexion par clé, de sorte que chaque composant d'Hadoop n'ait pas besoin d'entrer de mot de passe via une interaction utilisateur lors de l'accès les uns aux autres, ce qui peut réduire beaucoup d'opérations redondantes.
Commencez par basculer dans le répertoire personnel de l'utilisateur, puis utilisez la commande ssh-keygen pour générer la clé RSA.
Veuillez entrer la commande suivante dans le terminal :
cd /home/hadoop
ssh-keygen -t rsa
Lorsque vous rencontrez des informations telles que l'emplacement où la clé est stockée, vous pouvez appuyer sur Entrée pour utiliser la valeur par défaut.
The key's randomart image is:
+---[RSA 3072]----+
| ..+. |
| . =. o |
| .o o *. |
| o... + o |
| = +.S.. + |
| + + +++.. |
| . B.O+. |
| o +oXo*E |
| =.+==o. |
+----[SHA256]-----+
Une fois la clé générée, la clé publique sera générée dans le répertoire .ssh situé dans le répertoire personnel de l'utilisateur.
L'opération spécifique est montrée dans la figure ci-dessous :
Ensuite, continuez à entrer la commande suivante pour ajouter la clé publique générée au fichier d'enregistrement d'authentification de l'hôte. Donnez les droits d'écriture au fichier authorized_keys, sinon la vérification ne fonctionnera pas correctement :
cat.ssh/id_rsa.pub >> .ssh/authorized_keys
chmod 600.ssh/authorized_keys
Une fois l'ajout effectué avec succès, essayez de vous connecter à l'ordinateur local. Veuillez entrer la commande suivante dans le terminal :
ssh localhost
Lorsque vous vous connectez pour la première fois, vous serez invité à confirmer l'empreinte digitale de la clé publique, appuyez simplement sur yes et confirmez. Ensuite, lors de la connexion suivante, ce sera une connexion sans mot de passe :
...
Welcome to Alibaba Cloud Elastic Compute Service!
To run a command as administrator (user "root"), use "sudo <command>".
See "man sudo_root" for details.
hadoop:~$
Vous devez taper history -w ou quitter le terminal pour enregistrer les modifications afin de passer le script de vérification.
Installation d'Hadoop
Maintenant, vous pouvez télécharger le package d'installation d'Hadoop. Le site officiel fournit le lien de téléchargement de la dernière version d'Hadoop. Vous pouvez également utiliser la commande wget pour télécharger le package directement dans le terminal.
Entrez la commande suivante dans le terminal pour télécharger le package :
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz
Une fois le téléchargement terminé, vous pouvez utiliser la commande tar pour extraire le package :
tar zxvf hadoop-3.3.6.tar.gz
sudo mv hadoop-3.3.6 hadoop
sudo chown -R hadoop:hadoop /home/hadoop
Vous pouvez trouver l'emplacement de JAVA_HOME en exécutant la commande dirname $(dirname $(readlink -f $(which java))) dans le terminal.
dirname $(readlink -f $(which java))
Ensuite, ouvrez le fichier .zshrc avec un éditeur de texte dans le terminal :
vim /home/hadoop/.bashrc
Ajoutez les lignes suivantes à la fin du fichier /home/hadoop/.bashrc :
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
export HADOOP_HOME=/home/hadoop/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
Enregistrez et quittez l'éditeur vim. Ensuite, entrez la commande source dans le terminal pour activer les variables d'environnement nouvellement ajoutées :
source /home/hadoop/.bashrc
Vérifiez l'installation en exécutant la commande hadoop version dans le terminal.
hadoop@iZj6cgdabeniugz9ypibzxZ:~$ hadoop version
Hadoop 3.3.6
Source code repository https://github.com/apache/hadoop.git -r 1be78238728da9266a4f88195058f08fd012bf9c
Compiled by ubuntu on 2023-06-18T08:22Z
Compiled on platform linux-x86_64
Compiled with protoc 3.7.1
From source with checksum 5652179ad55f76cb287d9c633bb53bbd
This command was run using /home/hadoop/hadoop/share/hadoop/common/hadoop-common-3.3.6.jar
Configuration du modèle pseudo-distribué
Dans la plupart des cas, Hadoop est utilisé dans un environnement en grappe, c'est-à-dire que nous devons déployer Hadoop sur plusieurs nœuds. En même temps, Hadoop peut également fonctionner sur un seul nœud en mode pseudo-distribué, simulant des scénarios multi-nœuds grâce à plusieurs processus Java indépendants. Dans la phase initiale d'apprentissage, il n'est pas nécessaire de consacrer beaucoup de ressources pour créer différents nœuds. Ainsi, dans cette section et dans les chapitres suivants, nous utiliserons principalement le mode pseudo-distribué pour le déploiement du "cluster" Hadoop.
Création de répertoires
Pour commencer, créez les répertoires namenode et datanode dans le répertoire personnel de l'utilisateur Hadoop. Exécutez la commande ci-dessous pour créer ces répertoires :
rm -rf ~/hadoopdata
mkdir -p ~/hadoopdata/hdfs/{namenode,datanode}
Ensuite, vous devez modifier les fichiers de configuration d'Hadoop pour qu'il fonctionne en mode pseudo-distribué.
Édition de core-site.xml
Ouvrez le fichier core-site.xml avec un éditeur de texte dans le terminal :
vim /home/hadoop/hadoop/etc/hadoop/core-site.xml
Dans le fichier de configuration, modifiez la valeur de la balise configuration pour qu'elle soit la suivante :
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
L'élément de configuration fs.defaultFS est utilisé pour indiquer l'emplacement du système de fichiers utilisé par défaut par le cluster :
Enregistrez le fichier et quittez vim après édition.
Édition de hdfs-site.xml
Ouvrez un autre fichier de configuration hdfs-site.xml :
vim /home/hadoop/hadoop/etc/hadoop/hdfs-site.xml
Dans le fichier de configuration, modifiez la valeur de la balise configuration pour qu'elle soit la suivante :
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopdata/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopdata/hdfs/datanode</value>
</property>
</configuration>
Cet élément de configuration est utilisé pour indiquer le nombre de copies de fichiers dans HDFS, qui est 3 par défaut. Puisque nous l'avons déployé de manière pseudo-distribuée sur un seul nœud, il est modifié en 1 :
Enregistrez le fichier et quittez vim après édition.
Édition de hadoop-env.sh
Ensuite, éditez le fichier hadoop-env.sh :
vim /home/hadoop/hadoop/etc/hadoop/hadoop-env.sh
Changez la valeur de JAVA_HOME pour le lieu réel de l'installation du JDK, c'est-à-dire /usr/lib/jvm/java-11-openjdk-amd64.
Remarque : Vous pouvez utiliser la commande
echo $JAVA_HOMEpour vérifier le lieu réel de l'installation du JDK.
Enregistrez le fichier et quittez l'éditeur vim après édition.
Édition de yarn-site.xml
Ensuite, éditez le fichier yarn-site.xml :
vim /home/hadoop/hadoop/etc/hadoop/yarn-site.xml
Ajoutez le code suivant à la balise configuration :
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
Enregistrez le fichier et quittez l'éditeur vim après édition.
Édition de mapred-site.xml
Enfin, vous devez éditer le fichier mapred-site.xml.
Ouvrez le fichier avec l'éditeur vim :
vim /home/hadoop/hadoop/etc/hadoop/mapred-site.xml
De même, ajoutez le code suivant à la balise configuration :
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/home/hadoop/hadoop</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/home/hadoop/hadoop</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/home/hadoop/hadoop</value>
</property>
</configuration>
Enregistrez le fichier et quittez l'éditeur vim après édition.
Test de démarrage d'Hadoop
Ouvrez d'abord le terminal Xfce sur le bureau et basculez sur l'utilisateur Hadoop :
su -l hadoop
L'initialisation de HDFS consiste principalement à formater :
/home/hadoop/hadoop/bin/hdfs namenode -format
Astuce : vous devez supprimer le répertoire de données HDFS avant de formater.
Si vous voyez ce message, cela signifie que la formattage a réussi :
2024-02-29 18:24:53,887 INFO common.Storage: Storage directory /home/hadoop/hadoopdata/hdfs/namenode has been successfully formatted.
Vous devez taper history -w ou quitter le terminal pour enregistrer l'historique et passer le script de vérification.
Démarrer le système de fichiers distribué Hadoop (HDFS)
Une fois l'initialisation d'HDFS terminée, vous pouvez démarrer les démon pour le NameNode et le DataNode. Une fois démarrés, les applications Hadoop (telles que les tâches MapReduce) peuvent lire et écrire des fichiers dans/à partir de HDFS.
Démarrez le démon en entrant la commande suivante dans le terminal :
/home/hadoop/hadoop/sbin/start-dfs.sh
Voyez la sortie :
Starting namenodes on [localhost]
Starting datanodes
Starting secondary namenodes [iZj6cjditp4l7k0fylhhfbZ]
iZj6cjditp4l7k0fylhhfbZ: Warning: Permanently added 'izj6cjditp4l7k0fylhhfbz' (ED25519) to the list of known hosts.
Pour confirmer que Hadoop a été exécuté avec succès en mode pseudo-distribué, vous pouvez utiliser l'outil de visualisation de processus Java jps pour voir s'il existe un processus correspondant.
Entrez la commande suivante dans le terminal :
jps
Comme montré dans la figure, si vous voyez les processus du NameNode, du DataNode et du SecondaryNameNode, cela indique que le service Hadoop fonctionne correctement :
Voir les fichiers de journal et l'interface WebUI
Lorsque Hadoop ne peut pas démarrer ou que des erreurs sont signalées pendant l'exécution d'une tâche (ou autre chose), en plus de l'information de prompt du terminal, la consultation des journaux est le meilleur moyen de localiser un problème. La plupart des problèmes peuvent être trouvés grâce aux journaux des logiciels concernés pour déterminer la cause et trouver une solution. En tant qu'apprenant dans le domaine des grands données, la capacité d'analyser les journaux est aussi importante que la capacité d'apprendre le cadre de calcul et il faut la prendre au sérieux.
La sortie par défaut des journaux des démon d'Hadoop se trouve dans le répertoire de journal (logs) sous le répertoire d'installation. Entrez la commande suivante dans le terminal pour accéder au répertoire de journal :
ls /home/hadoop/hadoop/logs
hadoop-hadoop-datanode-iZj6cjditp4l7k0fylhhfbZ.log
hadoop-hadoop-datanode-iZj6cjditp4l7k0fylhhfbZ.out
hadoop-hadoop-namenode-iZj6cjditp4l7k0fylhhfbZ.log
hadoop-hadoop-namenode-iZj6cjditp4l7k0fylhhfbZ.out
hadoop-hadoop-secondarynamenode-iZj6cjditp4l7k0fylhhfbZ.log
hadoop-hadoop-secondarynamenode-iZj6cjditp4l7k0fylhhfbZ.out
SecurityAuth-hadoop.audit
Vous pouvez utiliser l'éditeur vim pour consulter n'importe quel fichier de journal.
Une fois HDFS démarré, un service web interne fournit également une page web affichant l'état du cluster. Basculez vers le haut de la machine virtuelle LabEx et cliquez sur "Web 8088" pour ouvrir la page web :
Après avoir ouvert la page web, vous pouvez voir l'état général du cluster, l'état du DataNode etc. :
N'hésitez pas à cliquer sur le menu en haut de la page pour explorer les conseils et les fonctionnalités.
Vous devez taper history -w ou quitter le terminal pour enregistrer l'historique et passer le script de vérification.
Test de téléchargement de fichiers dans le système de fichiers distribué Hadoop (HDFS)
Une fois que HDFS est en cours d'exécution, il peut être considéré comme un système de fichiers. Pour tester la fonctionnalité de téléchargement de fichiers, vous devez créer un répertoire (un niveau de profondeur par étape, jusqu'au niveau de répertoire requis) et essayer de télécharger certains fichiers du système Linux vers HDFS :
cd ~
/home/hadoop/hadoop/bin/hdfs dfs -mkdir /user
/home/hadoop/hadoop/bin/hdfs dfs -mkdir /user/hadoop
Une fois le répertoire créé avec succès, utilisez la commande hdfs dfs -put pour télécharger les fichiers du disque local (les fichiers de configuration d'Hadoop sélectionnés au hasard ici) vers HDFS :
/home/hadoop/hadoop/bin/hdfs dfs -put /home/hadoop/hadoop/etc/hadoop /user/hadoop/input
Cas de test de PI
La vaste majorité des applications Hadoop déployées dans des environnements de production du monde réel et résolvant des problèmes du monde réel sont basées sur le modèle de programmation MapReduce représenté par WordCount. Par conséquent, WordCount peut être utilisé comme un programme "HelloWorld" pour commencer avec Hadoop, ou vous pouvez ajouter vos propres idées pour résoudre des problèmes spécifiques.
Démarrer la tâche
À la fin de la section précédente, nous avons téléchargé quelques fichiers de configuration sur HDFS, à titre d'exemple. Ensuite, nous pouvons essayer d'exécuter le cas de test PI pour obtenir les statistiques de fréquence de mots de ces fichiers et les afficher selon nos règles de filtrage.
Démarrez d'abord le service de calcul YARN dans le terminal :
/home/hadoop/hadoop/sbin/start-yarn.sh
Ensuite, entrez la commande suivante pour démarrer la tâche :
/home/hadoop/hadoop/bin/hadoop jar /home/hadoop/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar pi 3 3
Voyez les résultats de sortie :
Estimated value of Pi is 3.55555555555555555556
Parmi les paramètres ci-dessus, il y a trois paramètres concernant le chemin. Ils sont : l'emplacement du package jar, l'emplacement du fichier d'entrée et l'emplacement de stockage du résultat de sortie. Lorsque vous spécifiez le chemin, vous devriez avoir l'habitude de spécifier un chemin absolu. Cela vous aidera à localiser rapidement les problèmes et à livrer votre travail rapidement.
Terminez la tâche, vous pouvez consulter les résultats.
Fermer le service HDFS
Après le calcul, si aucun autre programme logiciel n'utilise les fichiers sur HDFS, vous devriez fermer le démon HDFS en temps voulu.
En tant qu'utilisateur de clusters distribués et de cadres de calcul associés, vous devriez avoir l'habitude de vérifier activement l'état des composants matériels et logiciels associés chaque fois que cela implique l'ouverture et la fermeture du cluster, l'installation de matériel et de logiciel, ou n'importe quel type de mise à jour.
Utilisez la commande suivante dans le terminal pour fermer les démon HDFS et YARN :
/home/hadoop/hadoop/sbin/stop-yarn.sh
/home/hadoop/hadoop/sbin/stop-dfs.sh
Vous devez taper history -w ou quitter le terminal pour enregistrer l'historique et passer le script de vérification.
Résumé
Ce laboratoire a présenté l'architecture d'Hadoop, les méthodes d'installation et de déploiement en mode autonome et en mode pseudo-distribué, et exécuté WordCount pour des tests de base.
Voici les principaux points de ce laboratoire :
- Architecture d'Hadoop
- Principal module d'Hadoop
- Comment utiliser le mode autonome d'Hadoop
- Déploiement en mode pseudo-distribué d'Hadoop
- Utilisations de base d'HDFS
- Cas de test de WordCount
En général, Hadoop est un cadre de calcul et de stockage couramment utilisé dans le domaine des grands données. Ses fonctionnalités doivent être explorées plus avant. Veuillez conserver l'habitude de consulter des documents techniques et continuez à apprendre les étapes suivantes.


