
Einführung
Die Essenz von Docker besteht darin, LXC (Linux Containers) zu nutzen, um virtuelle Maschinen-ähnliche Funktionen zu erreichen. Dadurch werden Hardware-Ressourcen eingespart und den Benutzern mehr Rechenkapazität zur Verfügung gestellt. In diesem Projekt werden C++ mit den Linux-Namespace- und Control-Group-Technologien kombiniert, um einen einfachen Docker-Container zu implementieren.
Schließlich werden wir für den Container die folgenden Funktionen erreichen:
- Unabhängiges Dateisystem
- Unterstützung für Netzwerkzugang
👀 Vorschau
$ make
make container
make[1]: Entering directory '/home/labex/project'
gcc -c network.c nl.c
g++ -std=c++11 -o docker-run main.cpp network.o nl.o
make[1]: Leaving directory '/home/labex/project'
$ sudo./docker-run
...start container
root@labex:/## ifconfig
eth0 Link encap:Ethernet HWaddr 00:16:3e:da:01:72
inet6 addr: fe80::dc15:18ff:fe43:53b9/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:38 errors:0 dropped:0 overruns:0 frame:0
TX packets:9 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:5744 (5.7 KB) TX bytes:726 (726.0 B)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
🎯 Aufgaben
In diesem Projekt lernen Sie:
- Wie Sie einen einfachen Docker-Container mit C++ und der Linux-Namespace-Technologie erstellen
- Wie Sie ein unabhängiges Dateisystem für den Container implementieren
- Wie Sie den Netzwerkzugang für den Container ermöglichen
🏆 Errungenschaften
Nach Abschluss dieses Projekts können Sie:
- Einen einfachen Docker-Container mit C++ und der Linux-Namespace-Technologie erstellen
- Ein unabhängiges Dateisystem für den Container implementieren
- Den Netzwerkzugang für den Container ermöglichen
Linux-Namespace-Technologie
In C++ kennen wir das Schlüsselwort namespace. In C++ isoliert jeder Namespace gleiche Namen in verschiedenen Teilen des Codes. Solange die Namen der Namespaces unterschiedlich sind, können die Namen des Codes innerhalb der Namespaces identisch sein. Dadurch wird das Problem von Namenskonflikten im Code gelöst.
Linux Namespace hingegen ist eine Technologie, die vom Linux-Kernel bereitgestellt wird und eine Lösung für die Ressourcenisolierung von Anwendungen bietet, ähnlich wie das Konzept von namespace in C++. Wir wissen, dass Ressourcen wie PID (Prozess-ID), IPC (Interprozesskommunikation) und Netzwerkeigenschaften normalerweise vom Betriebssystem selbst verwaltet werden. Mit Linux Namespace können diese Ressourcen jedoch nicht mehr global sein, sondern werden bestimmten Namespaces zugewiesen.
In der Welt der Docker-Technologie hören wir oft Begriffe wie LXC (Linux Containers) und OS-Level-Virtualisierung. LXC nutzt die Namespace-Technologie, um die Ressourcenisolierung zwischen verschiedenen Containern zu erreichen. Durch die Verwendung der Namespace-Technologie gehören die Prozesse in verschiedenen Containern zu verschiedenen Namespaces und stören sich nicht gegenseitig. Zusammenfassend bietet die Namespace-Technologie eine leichte Form der Virtualisierung, die es uns ermöglicht, systemweite Eigenschaften aus verschiedenen Perspektiven zu verwalten.
In Linux ist der wichtigste Systemaufruf im Zusammenhang mit Namespaces clone(). Der Zweck von clone() besteht darin, Threads bei der Prozesserstellung auf einen bestimmten Namespace zu beschränken.
Kapselung von Systemaufrufen
Da Linux-Systemaufrufe in C geschrieben sind, müssen wir für unser Projekt C++-Code schreiben. Um einen einheitlichen, rein C++-basierten Codierstil beizubehalten, kapseln wir zunächst diese notwendigen APIs in eine C++-Form. Dies ermöglicht es uns auch, ein tieferes Verständnis davon zu erlangen, wie diese APIs verwendet werden.
Wir werden die folgenden APIs verwenden:
clone()
Sowohl der clone- als auch der fork-Systemaufruf werden in Linux zur Prozesserstellung verwendet. Allerdings ist fork nur ein kleiner Teil von clone. Der Unterschied zwischen ihnen besteht darin, dass fork nur einen Kindprozess erstellt, der eine exakte Kopie des Elternprozesses ist, während clone leistungsfähiger ist, da es die selektive Kopie von Ressourcen des Elternprozesses in den Kindprozess ermöglicht. Die Ressourcen, die nicht kopiert werden, werden zwischen den Prozessen über Zeigerkopien (arg) geteilt. Die spezifischen Ressourcen, die kopiert werden sollen, können mit flags angegeben werden, und die Funktion gibt die PID (Prozess-ID) des Kindprozesses zurück.
Wir wissen, dass ein Prozess aus vier Hauptkomponenten besteht:
- Ein auszuführender Codeabschnitt
- Ein privater Stapelraum für den Prozess
- Ein Prozesssteuerblock (PCB - Process Control Block)
- Prozess-spezifische Namespaces
Die ersten beiden Komponenten entsprechen den Parametern fn und child_stack in clone. Der Prozesssteuerblock wird vom Kernel gesteuert, und wir müssen uns nicht darum kümmern. Daher sind die Namespaces mit dem Parameter flags verknüpft. Um unser Ziel der Erstellung eines Docker-Containers zu erreichen, sind die wichtigsten Parameter wie folgt:
Namespace-Klassifikation Systemaufruf-Parameter
UTS CLONE_NEWUTS
Mount CLONE_NEWNS
PID CLONE_NEWPID
Network CLONE_NEWNET
Aus den Namen lässt sich erkennen, dass CLONE_NEWNS die Dateisystem-bezogene Montage für die Kopie und Dateisystem-bezogene Ressourcen bereitstellt, CLONE_NEWUTS die Möglichkeit bietet, den Hostnamen festzulegen, CLONE_NEWPID die Unterstützung für einen unabhängigen Prozessraum bietet und CLONE_NEWNET die Netzwerk-bezogene Unterstützung bereitstellt.
execv()
int execv(const char *path, char *const argv[]);
execv führt die ausführbare Datei aus, die durch path angegeben wird. Dieser Systemaufruf ermöglicht es unserem Kindprozess, /bin/bash auszuführen, um den Container am Laufen zu halten.
sethostname()
int sethostname(const char *name, size_t len);
Wie der Name schon sagt, wird dieser Systemaufruf verwendet, um den Hostnamen festzulegen. Es ist erwähnenswert, dass, da C-Strings Zeiger verwenden und die Länge des Strings nicht direkt bestimmt werden kann, der Parameter len verwendet wird, um die Länge des Strings zu erhalten.
chdir()
int chdir(const char *path);
Wir wissen, dass jedes Programm in einem bestimmten Verzeichnis ausgeführt wird. Wenn wir auf Ressourcen zugreifen müssen, können wir relative Pfade anstelle von absoluten Pfaden verwenden, um auf die relevanten Ressourcen zuzugreifen. chdir bietet uns die Möglichkeit, das Arbeitsverzeichnis unseres Programms zu ändern, was für bestimmte Zwecke genutzt werden kann.
chroot()
Dieser Systemaufruf wird verwendet, um das Root-Verzeichnis zu ändern:
int chroot(const char *path);
mount()
Dieser Systemaufruf wird verwendet, um Dateisysteme zu montieren, ähnlich wie der mount-Befehl.
int mount(const char *source, const char *target,
const char *filesystemtype, unsigned long mountflags,
const void *data);
Erstellen eines Container-Unterprozesses
Gehen Sie in das Verzeichnis ~/project und erstellen Sie eine Datei namens docker.hpp. In dieser Datei werden wir zunächst einen Namespace namens docker erstellen, der von unserem externen Code aufgerufen werden kann.
//
// docker.hpp
// cpp_docker
//
// Header-Dateien für Systemaufrufe
#include <sys/wait.h> // waitpid
#include <sys/mount.h> // mount
#include <fcntl.h> // open
#include <unistd.h> // execv, sethostname, chroot, fchdir
#include <sched.h> // clone
// C-Standardbibliothek
#include <cstring>
// C++-Standardbibliothek
#include <string> // std::string
#define STACK_SIZE (512 * 512) // Definieren Sie die Größe des Kindprozess-Speicherbereichs
namespace docker {
//.. hier beginnt die Docker-Magie
}
Lassen Sie uns zunächst einige Variablen definieren, um die Lesbarkeit zu verbessern:
// Innerhalb des `docker`-Namespaces definiert
typedef int proc_status;
proc_status proc_err = -1;
proc_status proc_exit = 0;
proc_status proc_wait = 1;
Bevor wir die Container-Klasse definieren, lassen Sie uns die Parameter analysieren, die für die Erstellung eines Containers erforderlich sind. Wir werden uns vorerst nicht um die netzwerkbezogene Konfiguration kümmern. Um einen Docker-Container aus einem Image zu erstellen, müssen wir nur den Hostnamen und den Speicherort des Images angeben. Daher:
// Docker-Container-Startkonfiguration
typedef struct container_config {
std::string host_name; // Hostname
std::string root_dir; // Root-Verzeichnis des Containers
} container_config;
Jetzt definieren wir die container-Klasse und lassen sie die erforderlichen Konfigurationen für den Container im Konstruktor durchführen:
class container {
private:
// Verbessert die Lesbarkeit
typedef int process_pid;
// Kindprozess-Stack
char child_stack[STACK_SIZE];
// Container-Konfiguration
container_config config;
public:
container(container_config &config) {
this->config = config;
}
};
Bevor wir über die spezifischen Methoden in der container-Klasse nachdenken, lassen Sie uns zunächst darüber nachdenken, wie wir diese container-Klasse verwenden würden. Dazu erstellen wir eine main.cpp-Datei im ~/project-Ordner:
//
// main.cpp
// cpp_docker
//
#include "docker.hpp"
#include <iostream>
int main(int argc, char** argv) {
std::cout << "...start container" << std::endl;
docker::container_config config;
// Konfigurieren Sie den Container
//...
docker::container container(config);// Erstellen Sie den Container basierend auf der Konfiguration
container.start(); // Starten Sie den Container
std::cout << "stop container..." << std::endl;
return 0;
}
In main.cpp, um den Containerstart kompakt und verständlich zu gestalten, nehmen wir an, dass der Container mit einer start()-Methode gestartet wird. Dies bildet die Grundlage für das Schreiben der docker.hpp-Datei später.
Jetzt kehren wir zu docker.hpp zurück und implementieren die start()-Methode:
void start() {
auto setup = [](void *args) -> int {
auto _this = reinterpret_cast<container *>(args);
// Führen Sie die relevanten Konfigurationen für den Container durch
//...
return proc_wait;
};
process_pid child_pid = clone(setup, child_stack+STACK_SIZE, // Gehen Sie zum unteren Ende des Stacks
SIGCHLD, // Senden Sie ein Signal an den Elternprozess, wenn der Kindprozess beendet wird
this);
waitpid(child_pid, nullptr, 0); // Warten Sie auf das Beenden des Kindprozesses
}
Die docker::container::start()-Methode verwendet den clone()-Systemaufruf in Linux. Um das docker::container-Instanzobjekt an die Callback-Funktion setup zu übergeben, können wir es über das vierte Argument von clone() übergeben. Hier übergeben wir den this-Zeiger.
Was die setup-Funktion betrifft, erstellen wir dafür einen Lambda-Ausdruck. In C++ kann ein Lambda-Ausdruck mit einer leeren Capture-Liste als Funktionszeiger übergeben werden. Daher wird setup zur Callback-Funktion, die an clone() übergeben wird.
Sie können auch eine statische Memberfunktion in der Klasse anstelle eines Lambda-Ausdrucks verwenden, aber das würde den Code weniger elegant gestalten.
Im Konstruktor dieser container-Klasse definieren wir eine Kindprozess-Behandlungsfunktion, die vom clone()-Systemaufruf aufgerufen wird. Wir verwenden typedef, um den Rückgabetyp dieser Funktion in proc_status zu ändern. Wenn diese Funktion proc_wait zurückgibt, wird der von clone() geklonte Kindprozess auf das Beenden warten.
Dies reicht jedoch nicht aus, da wir keine Konfiguration innerhalb des Prozesses durchgeführt haben. Infolgedessen wird unser Programm sofort beendet, da es nichts weiter zu tun hat, sobald der Prozess gestartet wird. Wie wir wissen, können wir in Docker, um einen Container am Laufen zu halten, verwenden:
docker run -it ubuntu:14.04 /bin/bash
Dies bindet STDIN an das /bin/bash des Containers. Lassen Sie uns also der docker::container-Klasse eine start_bash()-Methode hinzufügen:
private:
void start_bash() {
// Konvertieren Sie sicher einen C++-std::string in einen C-Style-String char *
// Ab C++14 ist diese direkte Zuweisung verboten: `char *str = "test";`
std::string bash = "/bin/bash";
char *c_bash = new char[bash.length()+1]; // +1 für '\0'
strcpy(c_bash, bash.c_str());
char* const child_args[] = { c_bash, NULL };
execv(child_args[0], child_args); // Führen Sie /bin/bash im Kindprozess aus
delete []c_bash;
}
Und rufen Sie es innerhalb von setup auf:
auto setup = [](void *args) -> int {
auto _this = reinterpret_cast<container *>(args);
_this->start_bash();
return proc_wait;
}
Jetzt können wir die folgenden Aktionen sehen:
labex:project/ $ hostname
iZj6cboigynrxh4mn2oo16Z
labex:project/ $ g++ main.cpp -std=c++11
labex:project/ $./a.out
...start container
labex@iZj6cboigynrxh4mn2oo16Z:~/project$ mkdir test
labex@iZj6cboigynrxh4mn2oo16Z:~/project$ ls
a.out docker.hpp main.cpp test
labex@iZj6cboigynrxh4mn2oo16Z:~/project$ exit
exit
stop container...
In den obigen Schritten überprüfen wir zunächst den aktuellen hostname, kompilieren den bisher geschriebenen Code, führen ihn aus und treten in unseren Container ein. Wir können sehen, dass sich der Bash-Prompt nach dem Eintritt in den Container ändert, was wir erwartet haben.
Es fällt jedoch leicht auf, dass dies nicht das gewünschte Ergebnis ist, da es genau das gleiche wie unser Hostsystem ist. Alle Operationen, die innerhalb dieses "Containers" ausgeführt werden, wirken sich direkt auf das Hostsystem aus.
Hier führen wir die erforderlichen Namespaces in der clone-API ein.
Ermöglichen, dass der Container seinen eigenen Hostnamen hat
Wie bereits im Abschnitt über Systemaufrufe erwähnt, ist es recht einfach, den Hostnamen eines Kindprozesses mithilfe eines Systemaufrufs festzulegen. Daher erstellen wir eine private Methode für die Klasse docker::container:
private:
// Setzen Sie den Hostnamen des Containers
void set_hostname() {
sethostname(this->config.host_name.c_str(), this->config.host_name.length());
}
Wir ändern auch die start()-Methode wie folgt:
void start() {
auto setup = [](void *args) -> int {
auto _this = reinterpret_cast<container *>(args);
// Konfigurieren Sie den Container
_this->set_hostname();
_this->start_bash();
return proc_wait;
};
process_pid child_pid = clone(setup, child_stack+STACK_SIZE,
CLONE_NEWUTS| // Fügen Sie den UTS-Namespace hinzu
SIGCHLD, // Senden Sie ein Signal an den Elternprozess, wenn der Kindprozess beendet wird
this);
waitpid(child_pid, nullptr, 0); // Warten Sie auf das Beenden des Kindprozesses
}
In der main.cpp-Datei konfigurieren we den Namen des Hostnamens:
int main(int argc, char** argv) {
std::cout << "...start container" << std::endl;
docker::container_config config;
config.host_name = "labex";
……
Jetzt lassen wir uns den Code neu kompilieren:
labex:project/ $ g++ main.cpp -std=c++11
labex:project/ $./a.out
...start container
stop container...
Es wird beobachtet, dass unser Container sofort beendet wird. Dies liegt daran, dass sobald wir den Namespace einführen, unser Programm Superuser-Rechte erfordert. Daher müssen wir das Programm mit sudo ausführen:
labex:project/ $ sudo./a.out
...start container
root@labex:/home/labex/project## hostname
labex
root@labex:/home/labex/project## exit
exit
stop container...
labex:project/ $ hostname
iZj6cboigynrxh4mn2oo16Z
Dies erreicht jedoch immer noch nicht den gewünschten Effekt des Containers, da wir, wie aus dem ls-Befehl ersichtlich ist, immer noch auf das Verzeichnis des Hosts zugreifen können.
Ermöglichen, dass der Container sein eigenes Dateisystem hat
In der Docker-Technologie werden Container auf der Grundlage von Images erstellt. Da wir einen Container implementieren möchten, ist es natürlich, dass wir ihn auf der Grundlage eines Images erstellen müssen. Glücklicherweise haben wir ein Docker-Image für Sie vorbereitet. Sie können es herunterladen von:
cd ~/project
wget --header="User-Agent: Mozilla/5.0" https://file.labex.io/lab/171925/docker-image.tar
Dann extrahieren Sie es in den Ordner ~/project/labex:
mkdir labex
tar -xf docker-image.tar --directory labex/
rm docker-image.tar
Hier können Sie möglicherweise einige Extraktionsfehler erhalten. Dies liegt daran, dass in der Umgebung einige Dateien nicht extern erstellt werden dürfen. Dies beeinträchtigt nicht unsere Implementierung unseres eigenen Containers, also können Sie es einfach ignorieren.
tar: dev/agpgart: Cannot mknod: Operation not permitted
tar: dev/audio: Cannot mknod: Operation not permitted
tar: dev/audio1: Cannot mknod: Operation not permitted
tar: dev/audio2: Cannot mknod: Operation not permitted
tar: dev/audio3: Cannot mknod: Operation not permitted
tar: dev/audioctl: Cannot mknod: Operation not permitted
……
Nachdem die Extraktion abgeschlossen ist, können wir unter labex ein fast komplettes Linux-Verzeichnis sehen:
labex:project/ $ ls labex
bin boot dev etc home lib lib64 media mnt opt proc root run sbin srv sys tmp usr var
Jetzt möchten wir, dass docker::container in dieses Verzeichnis wechselt und es als Root-Verzeichnis verwendet, um den externen Zugriff des Unterprozesses beim Start zu maskieren:
private:
// Setzen Sie das Root-Verzeichnis
void set_rootdir() {
// chdir-Systemaufruf, wechseln Sie in ein bestimmtes Verzeichnis
chdir(this->config.root_dir.c_str());
// chroot-Systemaufruf, setzen Sie das Root-Verzeichnis. Da wir uns
// bereits zuvor in das aktuelle Verzeichnis gewechselt haben,
// können wir einfach das aktuelle Verzeichnis als Root-Verzeichnis verwenden
chroot(".");
}
Dann füllen Sie die relevante Konfiguration in main.cpp aus:
#include "docker.hpp"
#include <iostream>
int main(int argc, char** argv) {
std::cout << "...start container" << std::endl;
docker::container_config config;
config.host_name = "labex";
config.root_dir = "./labex";
……
Und aktivieren Sie CLONE_NEWNS im clone()-Aufruf, um den Mount-Namespace zu aktivieren:
void start() {
auto setup = [](void *args) -> int {
auto _this = reinterpret_cast<container *>(args);
_this->set_hostname();
_this->set_rootdir();
_this->start_bash();
return proc_wait;
};
process_pid child_pid = clone(setup, child_stack+STACK_SIZE,
CLONE_NEWUTS| // UTS-Namespace
CLONE_NEWNS| // Mount-Namespace
SIGCHLD, // Ein Signal wird an den Elternprozess gesendet, wenn der Kindprozess beendet wird
this);
waitpid(child_pid, nullptr, 0); // Warten Sie auf das Beenden des Kindprozesses
}
Jetzt lassen wir uns den Code neu kompilieren:
labex:project/ $ g++ main.cpp -std=c++11
labex:project/ $ sudo./a.out
...start container
root@labex:/## ls
bin boot dev etc home lib lib64 media mnt opt proc root run sbin srv sys tmp usr var
root@labex:/## hostname
labex
Durch Ausführen von ls können wir sehen, dass der Kindprozess jetzt in einem kompletten linux-Verzeichnis lebt.
Ermöglichen, dass der Container sein eigenes Prozesssystem hat
Allerdings gibt es immer noch ein Problem. Wenn wir Befehle wie ps oder top verwenden, können wir immer noch alle Prozesse im Elternprozess beobachten. Dies ist nicht der gewünschte Effekt. Beispielsweise können wir a.out in der Ausgabe von ps sehen, und der Prozess-ID-Wert ist auch sehr groß.
Um dieses Problem zu lösen, müssen wir den PID-Namespace (Prozess-ID-Namespace) einführen, um den PID-Speicherbereich der Kindprozesse vom Elternprozess zu isolieren.
private:
// Einrichten eines unabhängigen Prozess-Namespace
void set_procsys() {
// Mounten des proc-Dateisystems
mount("none", "/proc", "proc", 0, nullptr);
mount("none", "/sys", "sysfs", 0, nullptr);
}
Ebenso müssen wir diesen Codeabschnitt in start() hinzufügen und CLONE_NEWPID einführen:
void start() {
auto setup = [](void *args) -> int {
auto _this = reinterpret_cast<container *>(args);
_this->set_hostname();
_this->set_rootdir();
_this->set_procsys();
_this->start_bash();
return proc_wait;
};
process_pid child_pid = clone(setup, child_stack,
CLONE_NEWUTS| // UTS-Namespace
CLONE_NEWNS| // Mount-Namespace
CLONE_NEWPID| // PID-Namespace
SIGCHLD, // Ein Signal wird an den Elternprozess gesendet, wenn der Kindprozess beendet wird
this);
waitpid(child_pid, nullptr, 0); // Warten auf das Beenden des Kindprozesses
}
Jetzt, wenn wir erneut kompilieren und ausführen, werden wir sehen, dass der Container seinen eigenen unabhängigen Prozessspeicherbereich hat:
An diesem Punkt haben wir die Namespace-Technologie in Linux verwendet, um die Ressourcen in den Kindprozessen zu isolieren und unserem Docker-Container seinen eigenen Prozessspeicherbereich und sein eigenes Dateisystem zu geben.
Allerdings kann der Container immer noch nicht auf das Netzwerk zugreifen, und wir können sogar die Netzwerkeinrichtungen des Hosts mit ifconfig zugreifen. Dies ist nicht, was wir wollen. Als Nächstes werden wir den Container weiter verbessern, um ihn noch mehr wie einen vollständigen Container aussehen zu lassen und die Unterstützung für den Netzwerkzugriff bereitzustellen.
Docker-Netzwerkkonzepte
Bisher hatten wir einen ersten Einblick in die Funktionsweise von Docker bei der Erstellung eines isolierten Containers. Allerdings haben wir auch festgestellt, dass der von uns implementierte Docker-Container keinen Netzwerkzugriff unterstützt und dass die verschiedenen von uns ausgeführten Container nicht in der Lage sind, miteinander zu kommunizieren.
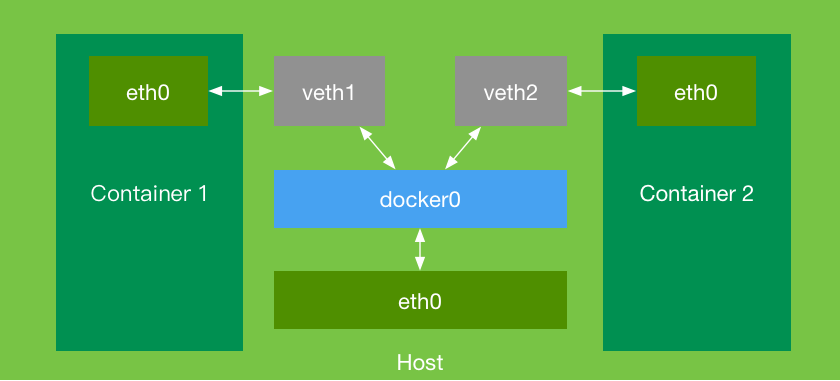
Das Prinzip der Netzwerkkommunikation zwischen Docker-Containern wird über eine Brücke namens 'docker0' realisiert. Die beiden Container 'container1' und 'container2' verfügen jeweils über ihr eigenes Netzwerkgerät 'eth0'. Alle Netzwerkanfragen werden über 'eth0' weitergeleitet. Da Container in Kindprozessen laufen, müssen zur Ermöglichung der Kommunikation zwischen ihren 'eth0'-Schnittstellen ein Paar Netzwerkgeräte 'veth1' und 'veth2' erstellt und der 'docker0'-Brücke hinzugefügt werden. Dadurch kann die Brücke die von den 'eth0'-Schnittstellen innerhalb des Containers generierten Netzwerkanfragen bedingungslos weiterleiten und routen, wodurch die Kommunikation zwischen den Containern ermöglicht wird.
Um also unseren selbstgeschriebenen Containern Netzwerkkommunikationsfähigkeiten zu verleihen, müssen wir zunächst eine Brücke erstellen, die sie nutzen können. Der Einfachheit halber werden wir direkt die bereits vorhandene 'docker0' in der Umgebung verwenden.
Vorbereitung für die Netzwerkerstellung
Die Manipulation des Netzwerks mit der nativen Linux-API ist eine sehr komplexe Aufgabe, die auch viele C-Sprachenoperationen beinhaltet. Um uns stärker auf die Programmierung in C++ zu konzentrieren, werden hier einige bereits implementierte "Tools" bereitgestellt, die es Ihnen erleichtern, das Netzwerk zu manipulieren.
Gehen Sie in das Verzeichnis
/tmp. Wir haben Ihnen vier Dateien zur Verfügung gestellt:network.h,nl.h,network.cundnl.c.
Kopieren Sie diese vier Dateien in das Verzeichnis ~/project:
cp /tmp/network.h /tmp/nl.h /tmp/network.c /tmp/nl.c ~/project/
Der Code der letzten drei Dateien stammt aus dem LXC-Toolset. Dieser Code ist jedoch in der Programmiersprache C geschrieben. Da C++ und C ab C++11 nicht mehr miteinander kompatibel sind, müssen wir etwas über gemischtes C/C++-Programmieren wissen, damit C++ diesen Code problemlos aufrufen kann.
Zunächst wissen wir, dass die Umwandlung von Quellcode in ausführbare Dateien nicht direkt erfolgt, sondern in mehreren Schritten: Vorverarbeitung, Kompilierung, Assemblierung und Linken. Normalerweise verwenden wir den Befehl g++ main.cpp, um alle obigen Schritte auf einmal abzuschließen.
Wenn das Projekt jedoch größer wird und die Anzahl der Quellcode-Dateien zunimmt, lohnt es sich nicht, das gesamte Projekt nur wegen einer kleinen Änderung neu zu kompilieren. In diesem Fall können wir zunächst den Code in .o-Dateien kompilieren und dann die Linkarbeit durchführen. Dies ermöglicht es uns auch, eine C-kompilierte Linkdatei und C++-relevanten Quellcode gleichzeitig zu kompilieren.
C++ und C haben unterschiedliche Kompilierungs- und Handhabungsmethoden. Wenn wir also einen Satz C-Code kompilieren möchten, müssen wir die __cplusplus-Makro und extern "C" verwenden.
In network.h sind die relevanten Schnittstellendeklarationen von network.c gespeichert. Wenn wir die folgenden kommentierten Teile auskommentieren:
// #ifdef __cplusplus
// extern "C"
// {
// #endif
#include <sys/types.h>
int netdev_set_flag(const char *name, int flag);
……
void new_hwaddr(char *hwaddr);
// #ifdef __cplusplus
// }
// #endif
Und dann mit gcc direkt in .o-Dateien kompilieren:
gcc -c network.c nl.c
Und anschließend den folgenden Code verwenden:
// test.cpp
#include "network.h"
int main() {
new_hwaddr(nullptr);
return 0;
}
Um ihn zu kompilieren und zu testen:
g++ test.cpp network.o nl.o -std=c++11
Wir werden feststellen, dass die Kompilierung fehlschlägt und einen Fehler undefined reference to 'new_hwaddr(char*)' ausgibt.
/usr/bin/ld: /tmp/ccz4DEEy.o: in function `main':
test.cpp:(.text+0xe): undefined reference to `new_hwaddr(char*)'
collect2: error: ld returned 1 exit status
Mit anderen Worten:
Wenn wir C-Bibliotheken in C++ kompilieren und verlinken möchten, müssen wir die relevante Deklaration der Schnittstelle umschließen:
#ifdef __cplusplus
extern "C"
{
#endif
// C-Schnittstellenfunktionen
#ifdef __cplusplus
}
#endif
Zu diesem Zeitpunkt kompilieren wir network.c und nl.c erneut in .o-Dateien und kompilieren dann *.o mit test.cpp erfolgreich.
Erstellung eines Container-Netzwerks
Basierend auf dem vorherigen Abschnitt über das Netzwerkprinzip von Docker können wir die folgenden Schritte zusammenfassen, um die von uns erstellten Container für Netzwerkunterstützung zu aktivieren:
- Erstellen eines Paars virtueller Netzwerkgeräte veth1/veth2;
- Festlegen der MAC-Adresse von veth1;
- Hinzufügen von veth1 zur Brücke labex0;
- Aktivieren von veth1;
- Erstellen eines Kindprozesses;
- Verschieben von veth2 in den Netzwerk-Namespace (Netzwerkbereich) des Kindprozesses und Umbenennen in eth0;
- Warten auf das Beenden des Kindprozesses;
- Löschen der Netzwerkgeräte veth1 und veth2;
Wir müssen daher die Logik von start() weiter optimieren.
Zunächst sollten wir Netzwerk-relevante Konfigurationen zu docker::container_config hinzufügen:
Fügen Sie die Header-Dateien hinzu:
#include <net/if.h> // if_nametoindex
#include <arpa/inet.h> // inet_pton
#include "network.h"
Fügen Sie die docker::container_config-Konfiguration hinzu:
// Docker-Container-Startkonfiguration
typedef struct container_config {
std::string host_name; // Hostname
std::string root_dir; // Container-Wurzelverzeichnis
std::string ip; // Container-IP
std::string bridge_name; // Brückenname
std::string bridge_ip; // Brücken-IP
} container_config;
Legen Sie dann in main.cpp die Container-IP, den Namen der hinzuzufügenden Brücke docker0 und die IP der Brücke fest:
int main(int argc, char** argv) {
std::cout << "...start container" << std::endl;
docker::container_config config;
config.host_name = "labex";
config.root_dir = "./labex";
// Konfigurieren Sie die Netzwerkparameter
config.ip = "192.168.0.100"; // Container-IP
config.bridge_name = "docker0"; // Host-Brücke
config.bridge_ip = "192.168.0.1"; // Host-Brücken-IP
docker::container container(config);
container.start();
std::cout << "stop container..." << std::endl;
return 0;
}
Lassen Sie uns die start()-Methode basierend auf der obigen Logik zum Laden von Netzwerkgeräten neu gestalten:
private:
// Speichern der Container-Netzwerkgeräte zum Löschen
char *veth1;
char *veth2;
public:
void start() {
char veth1buf[IFNAMSIZ] = "labex0X";
char veth2buf[IFNAMSIZ] = "labex0X";
// Erstellen eines Paars Netzwerkgeräte, eines wird auf den Host geladen, das andere wird in den Container im Kindprozess verschoben
veth1 = lxc_mkifname(veth1buf); // Die lxc_mkifname-API erfordert, dass mindestens ein "X" zum Namen des virtuellen Netzwerkgeräts hinzugefügt wird, um die zufällige Erstellung von virtuellen Netzwerkgeräten zu unterstützen
veth2 = lxc_mkifname(veth2buf); // Dies dient zur sicheren Erstellung von Netzwerkgeräten. Details finden Sie in der Implementierung von lxc_mkifname in network.c
lxc_veth_create(veth1, veth2);
// Festlegen der MAC-Adresse von veth1
setup_private_host_hw_addr(veth1);
// Hinzufügen von veth1 zur Brücke
lxc_bridge_attach(config.bridge_name.c_str(), veth1);
// Aktivieren von veth1
lxc_netdev_up(veth1);
// Einige Konfigurationsarbeiten vor der Containererstellung
auto setup = [](void *args) -> int {
auto _this = reinterpret_cast<container *>(args);
_this->set_hostname();
_this->set_rootdir();
_this->set_procsys();
// Konfigurieren des Netzwerks innerhalb des Containers
//...
_this->start_bash();
return proc_wait;
};
// Erstellen des Containers mit clone
process_pid child_pid = clone(setup, child_stack,
CLONE_NEWUTS| // UTS-Namespace
CLONE_NEWNS| // Mount-Namespace
CLONE_NEWPID| // PID-Namespace
CLONE_NEWNET| // Netzwerk-Namespace
SIGCHLD, // Der Kindprozess sendet ein Signal an den Elternprozess, wenn er beendet wird
this);
// Verschieben von veth2 in den Container und Umbenennen in eth0
lxc_netdev_move_by_name(veth2, child_pid, "eth0");
waitpid(child_pid, nullptr, 0); // Warten auf das Beenden des Kindprozesses
}
~container() {
// Denken Sie daran, die erstellten virtuellen Netzwerkgeräte beim Beenden zu löschen
lxc_netdev_delete_by_name(veth1);
lxc_netdev_delete_by_name(veth2);
}
Hinweis: Fügen Sie
CLONE_NEWNETinclonehinzu.
Aus den obigen Schritten können wir sehen, dass wir nach der Erstellung der Netzwerkgeräte und während der Erstellung des Kindprozesses in Zusammenarbeit mit den externen Netzwerkgeräten entsprechende Konfigurationen innerhalb des Containers vornehmen müssen:
- Aktivieren des
lo-Geräts innerhalb des Containers; - Konfigurieren der IP-Adresse von
eth0; - Aktivieren von
eth0; - Festlegen des Gateways;
- Festlegen der MAC-Adresse von
eth0;
private:
void set_network() {
int ifindex = if_nametoindex("eth0");
struct in_addr ipv4;
struct in_addr bcast;
struct in_addr gateway;
// IP-Adressen-Transformationsfunktion, die IP-Adressen zwischen Punkt-Dezimal- und Binärdarstellung konvertiert
inet_pton(AF_INET, this->config.ip.c_str(), &ipv4);
inet_pton(AF_INET, "255.255.255.0", &bcast);
inet_pton(AF_INET, this->config.bridge_ip.c_str(), &gateway);
// Konfigurieren der IP-Adresse von eth0
lxc_ipv4_addr_add(ifindex, &ipv4, &bcast, 16);
// Aktivieren von lo
lxc_netdev_up("lo");
// Aktivieren von eth0
lxc_netdev_up("eth0");
// Festlegen des Gateways
lxc_ipv4_gateway_add(ifindex, &gateway);
// Festlegen der MAC-Adresse von eth0
char mac[18];
new_hwaddr(mac);
setup_hw_addr(mac, "eth0");
}
Rufen Sie dann diese Methode in der setup-Funktion des Containers auf:
……
_this->set_procsys();
_this->set_network(); // Zusammenarbeit für die Netzwerkkonfiguration innerhalb des Containers
_this->start_bash();
return proc_wait;
Da wir nun die kompilierten Linkdateien network.o und nl.o verwenden, schreiben wir eine sehr einfache Makefile:
C = gcc
CXX = g++
C_LIB = network.c nl.c
C_LINK = network.o nl.o
MAIN = main.cpp
LD = -std=c++11
OUT = docker-run
all:
make container
container:
$(C) -c $(C_LIB)
$(CXX) $(LD) -o $(OUT) $(MAIN) $(C_LINK)
clean:
rm *.o $(OUT)
Hinweis: Der Befehl in der Makefile sollte mit einem Tabulator und nicht mit Leerzeichen beginnen. Dies liegt daran, dass der Markdown-Interpreter einen Tabulator in vier Leerzeichen umwandelt. Wenn Sie eine Makefile schreiben, verwenden Sie unbedingt einen Tabulator anstelle von vier Leerzeichen. Andernfalls wird die Makefile den Fehler "Makefile:10: *** missing separator. Stop." ausgeben.
Kompilieren und ausführen Sie es erneut und geben Sie den Container ein. Wir können ifconfig verwenden, um das Netzwerk zu überprüfen:
labex:project/ $ make
make container
make[1]: Entering directory '/home/labex/project'
gcc -c network.c nl.c
g++ -std=c++11 -o docker-run main.cpp network.o nl.o
make[1]: Leaving directory '/home/labex/project'
labex:project/ $ sudo./docker-run
...start container
root@labex:/## ifconfig
eth0 Link encap:Ethernet HWaddr 00:16:3e:da:01:72
inet6 addr: fe80::dc15:18ff:fe43:53b9/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:38 errors:0 dropped:0 overruns:0 frame:0
TX packets:9 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:5744 (5.7 KB) TX bytes:726 (726.0 B)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
Zusammenfassung
Durch dieses Projekt haben wir schrittweise Folgendes erreicht: Einbinden eines Dateisystems in einen Container und Ermöglichung des Zugangs zu externen Netzwerken.
Wir haben erfolgreich einen grundlegenden Docker-Container erstellt. Sie können diesen Container weiter optimieren, um eine realistischere Emulation zu erreichen.


